Speaker diarization, an important course of in audio evaluation, segments an audio file based mostly on speaker identification. This submit delves into integrating Hugging Face’s PyAnnote for speaker diarization with Amazon SageMaker asynchronous endpoints.
We offer a complete information on how one can deploy speaker segmentation and clustering options utilizing SageMaker on the AWS Cloud. You should use this resolution for functions coping with multi-speaker (over 100) audio recordings.
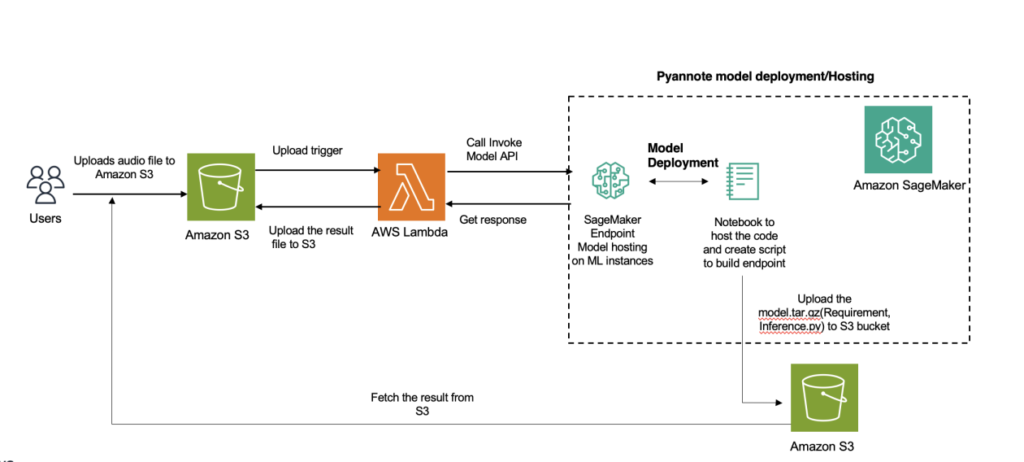
Answer overview
Amazon Transcribe is the go-to service for speaker diarization in AWS. Nonetheless, for non-supported languages, you should utilize different fashions (in our case, PyAnnote) that can be deployed in SageMaker for inference. For brief audio recordsdata the place the inference takes as much as 60 seconds, you should utilize real-time inference. For longer than 60 seconds, asynchronous inference needs to be used. The additional advantage of asynchronous inference is the price financial savings by auto scaling the occasion depend to zero when there are not any requests to course of.
Hugging Face is a well-liked open supply hub for machine studying (ML) fashions. AWS and Hugging Face have a partnership that enables a seamless integration by way of SageMaker with a set of AWS Deep Studying Containers (DLCs) for coaching and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK. SageMaker options and capabilities assist builders and knowledge scientists get began with pure language processing (NLP) on AWS with ease.
The combination for this resolution includes utilizing Hugging Face’s pre-trained speaker diarization mannequin utilizing the PyAnnote library. PyAnnote is an open supply toolkit written in Python for speaker diarization. This mannequin, educated on the pattern audio dataset, permits efficient speaker partitioning in audio recordsdata. The mannequin is deployed on SageMaker as an asynchronous endpoint setup, offering environment friendly and scalable processing of diarization duties.
The next diagram illustrates the answer structure.
For this submit, we use the next audio file.
Stereo or multi-channel audio recordsdata are routinely downmixed to mono by averaging the channels. Audio recordsdata sampled at a unique price are resampled to 16kHz routinely upon loading.
Ensure that the AWS account has a service quota for internet hosting a SageMaker endpoint for an ml.g5.2xlarge occasion.
Create a mannequin operate for accessing PyAnnote speaker diarization from Hugging Face
You should use the Hugging Face Hub to entry the specified pre-trained PyAnnote speaker diarization model. You employ the identical script for downloading the mannequin file when creating the SageMaker endpoint.
See the next code:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the mannequin from the required mannequin listing
mannequin = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Exchange-with-the-Hugging-face-auth-token")
return mannequin
Bundle the mannequin code
Put together important recordsdata like inference.py, which accommodates the inference code:
%%writefile mannequin/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the mannequin from the required mannequin listing
mannequin = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return mannequin
def diarization_from_s3(mannequin, s3_file, language=None):
s3 = boto3.consumer("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
outcome = mannequin("tmp.wav")
knowledge = {}
for flip, _, speaker in outcome.itertracks(yield_label=True):
knowledge[turn] = (flip.begin, flip.finish, speaker)
data_df = pd.DataFrame(knowledge.values(), columns=["start", "end", "speaker"])
print(data_df.form)
outcome = data_df.to_json(orient="cut up")
return outcome
def predict_fn(knowledge, mannequin):
s3_file = knowledge.pop("s3_file")
language = knowledge.pop("language", None)
outcome = diarization_from_s3(mannequin, s3_file, language)
return {
"diarization_from_s3": outcome
}
Put together a necessities.txt file, which accommodates the required Python libraries essential to run the inference:
with open("mannequin/code/necessities.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
Lastly, compress the inference.py and necessities.txt recordsdata and reserve it as mannequin.tar.gz:
Configure a SageMaker mannequin
Outline a SageMaker mannequin useful resource by specifying the picture URI, mannequin knowledge location in Amazon Simple Storage Service (S3), and SageMaker function:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess isn't None:
sagemaker_session_bucket = sess.default_bucket()
strive:
function = sagemaker.get_execution_role()
besides ValueError:
iam = boto3.consumer("iam")
function = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker function arn: {function}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session area: {sess.boto_region_name}")
Add the mannequin to Amazon S3
Add the zipped PyAnnote Hugging Face mannequin file to an S3 bucket:
Configure an asynchronous endpoint for deploying the mannequin on SageMaker utilizing the offered asynchronous inference configuration:
from sagemaker.huggingface.mannequin import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Mannequin Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your mannequin and script
function=function, # iam function with permissions to create an Endpoint
transformers_version="4.17", # transformers model used
pytorch_version="1.10", # pytorch model used
py_version="py38", # python model used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # The place our outcomes can be saved
# Add nofitication SNS if wanted
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
Take a look at the endpoint
Consider the endpoint performance by sending an audio file for diarization and retrieving the JSON output saved within the specified S3 output path:
# Exchange with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(knowledge=knowledge)
print(f"Response output path: {res.output_path}")
print("Begin Polling to get response:")
config = WaiterConfig(
max_attempts=10, # variety of makes an attempt
delay=10# time in seconds to attend between makes an attempt
)
res.get_result(config)
#import waiterconfig
To deploy this resolution at scale, we advise utilizing AWS Lambda, Amazon Simple Notification Service (Amazon SNS), or Amazon Simple Queue Service (Amazon SQS). These providers are designed for scalability, event-driven architectures, and environment friendly useful resource utilization. They will help decouple the asynchronous inference course of from the outcome processing, permitting you to scale every part independently and deal with bursts of inference requests extra successfully.
Outcomes
Mannequin output is saved at s3://sagemaker-xxxx /async_inference/output/. The output reveals that the audio recording has been segmented into three columns:
Begin (begin time in seconds)
Finish (finish time in seconds)
Speaker (speaker label)
The next code reveals an instance of our outcomes:
You possibly can set a scaling coverage to zero by setting MinCapacity to 0; asynchronous inference allows you to auto scale to zero with no requests. You don’t must delete the endpoint, it scales from zero when wanted once more, decreasing prices when not in use. See the next code:
# Frequent class representing utility autoscaling for SageMaker
consumer = boto3.consumer('application-autoscaling')
# That is the format through which utility autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Outline and register your endpoint variant
response = consumer.register_scalable_target(
ServiceNamespace="sagemaker",
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The variety of EC2 situations in your Amazon SageMaker mannequin endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
If you wish to delete the endpoint, use the next code:
The answer can effectively deal with a number of or giant audio recordsdata.
This instance makes use of a single occasion for demonstration. If you wish to use this resolution for a whole lot or 1000’s of movies and use an asynchronous endpoint to course of throughout a number of situations, you should utilize an auto scaling policy, which is designed for numerous supply paperwork. Auto scaling dynamically adjusts the variety of situations provisioned for a mannequin in response to modifications in your workload.
The answer optimizes assets and reduces system load by separating long-running duties from real-time inference.
Conclusion
On this submit, we offered a simple method to deploy Hugging Face’s speaker diarization mannequin on SageMaker utilizing Python scripts. Utilizing an asynchronous endpoint gives an environment friendly and scalable means to ship diarization predictions as a service, accommodating concurrent requests seamlessly.
Get began immediately with asynchronous speaker diarization in your audio tasks. Attain out within the feedback in case you have any questions on getting your individual asynchronous diarization endpoint up and working.
In regards to the Authors
Sanjay Tiwary is a Specialist Options Architect AI/ML who spends his time working with strategic prospects to outline enterprise necessities, present L300 classes round particular use circumstances, and design AI/ML functions and providers which are scalable, dependable, and performant. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has carried out a number of proofs of idea utilizing Amazon AI providers. He has additionally developed the superior analytics platform as part of the digital transformation journey.
Kiran Challapalli is a deep tech enterprise developer with the AWS public sector. He has greater than 8 years of expertise in AI/ML and 23 years of general software program improvement and gross sales expertise. Kiran helps public sector companies throughout India discover and co-create cloud-based options that use AI, ML, and generative AI—together with giant language fashions—applied sciences.


 Sanjay Tiwary is a Specialist Options Architect AI/ML who spends his time working with strategic prospects to outline enterprise necessities, present L300 classes round particular use circumstances, and design AI/ML functions and providers which are scalable, dependable, and performant. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has carried out a number of proofs of idea utilizing Amazon AI providers. He has additionally developed the superior analytics platform as part of the digital transformation journey.
Sanjay Tiwary is a Specialist Options Architect AI/ML who spends his time working with strategic prospects to outline enterprise necessities, present L300 classes round particular use circumstances, and design AI/ML functions and providers which are scalable, dependable, and performant. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has carried out a number of proofs of idea utilizing Amazon AI providers. He has additionally developed the superior analytics platform as part of the digital transformation journey. Kiran Challapalli is a deep tech enterprise developer with the AWS public sector. He has greater than 8 years of expertise in AI/ML and 23 years of general software program improvement and gross sales expertise. Kiran helps public sector companies throughout India discover and co-create cloud-based options that use AI, ML, and generative AI—together with giant language fashions—applied sciences.
Kiran Challapalli is a deep tech enterprise developer with the AWS public sector. He has greater than 8 years of expertise in AI/ML and 23 years of general software program improvement and gross sales expertise. Kiran helps public sector companies throughout India discover and co-create cloud-based options that use AI, ML, and generative AI—together with giant language fashions—applied sciences.



