Semantic Search with Vector Databases

Picture generated with Ideogram.ai
I’m certain that the majority of us have used engines like google.
There’s even a phrase resembling “Simply Google it.” The phrase means it’s best to seek for the reply utilizing Google’s search engine. That’s how common Google can now be recognized as a search engine.
Why search engine is so beneficial? Serps permit customers to simply purchase info on the web utilizing restricted question enter and manage that info based mostly on relevance and high quality. In flip, search permits accessibility to huge information that was beforehand inaccessible.
Historically, the search engine method to discovering info is predicated on lexical matches or phrase matching. It really works effectively, however generally, the end result could possibly be extra correct as a result of the person intention differs from the enter textual content.
For instance, the enter “Crimson Costume Shot within the Darkish” can have a double which means, particularly with the phrase “Shot.” The extra possible which means is that the Crimson Costume image is taken at midnight, however conventional engines like google wouldn’t perceive it. That’s why Semantic Search is rising.
Semantic search could possibly be outlined as a search engine that considers the which means of phrases and sentences. The semantic search output can be info that matches the question which means, which contrasts with a standard search that matches the question with phrases.
Within the NLP (Pure Language Processing) discipline, vector databases have considerably improved semantic search capabilities by using the storage, indexing, and retrieval of high-dimensional vectors representing textual content’s which means. So, semantic search and vector databases had been carefully associated fields.
This text will focus on semantic search and how one can use a Vector Database. With that in thoughts, let’s get into it.
Let’s focus on Semantic Search within the context of Vector Databases.
Semantic search concepts are based mostly on the meanings of the textual content, however how might we seize that info? A pc can’t have a sense or information like people do, which implies the phrase “meanings” must confer with one thing else. Within the semantic search, the phrase “which means” would turn into a illustration of information that’s appropriate for significant retrieval.
The which means illustration comes as Embedding, the textual content transformation course of right into a Vector with numerical info. For instance, we will remodel the sentence “I wish to find out about Semantic Search” utilizing the OpenAI Embedding mannequin.
[-0.027598874643445015, 0.005403674207627773, -0.03200408071279526, -0.0026835924945771694, -0.01792600005865097,...]
How is that this numerical vector in a position to seize the meanings, then? Let’s take a step again. The end result you see above is the embedding results of the sentence. The embedding output can be totally different should you changed even only one phrase within the above sentence. Even a single phrase would have a unique embedding output as effectively.
If we have a look at the entire image, embeddings for a single phrase versus a whole sentence will differ considerably as a result of sentence embeddings account for relationships between phrases and the sentence’s general which means, which isn’t captured within the particular person phrase embeddings. It means every phrase, sentence, and textual content is exclusive in its embedding end result. That is how embedding might seize which means as an alternative of lexical matching.
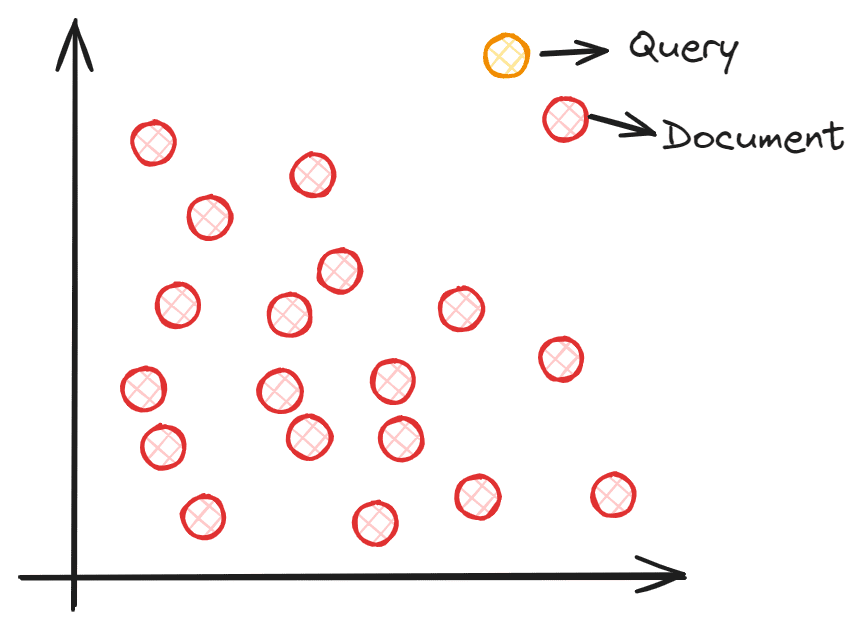
So, how does semantic search work with vectors? A semantic search goals to embed your corpus right into a vector area. This permits every knowledge level to offer info (textual content, sentence, paperwork, and so on.) and turn into a coordinate level. The question enter is processed right into a vector through embedding into the identical vector area throughout search time. We might discover the closest embedding from our corpus to the question enter utilizing vector similarity measures resembling Cosine similarities. To grasp higher, you’ll be able to see the picture under.
Picture by Creator
Every doc embedding coordinate is positioned within the vector area, and the question embedding is positioned within the vector area. The closest doc to the question can be chosen because it theoretically has the closest semantic which means to the enter.
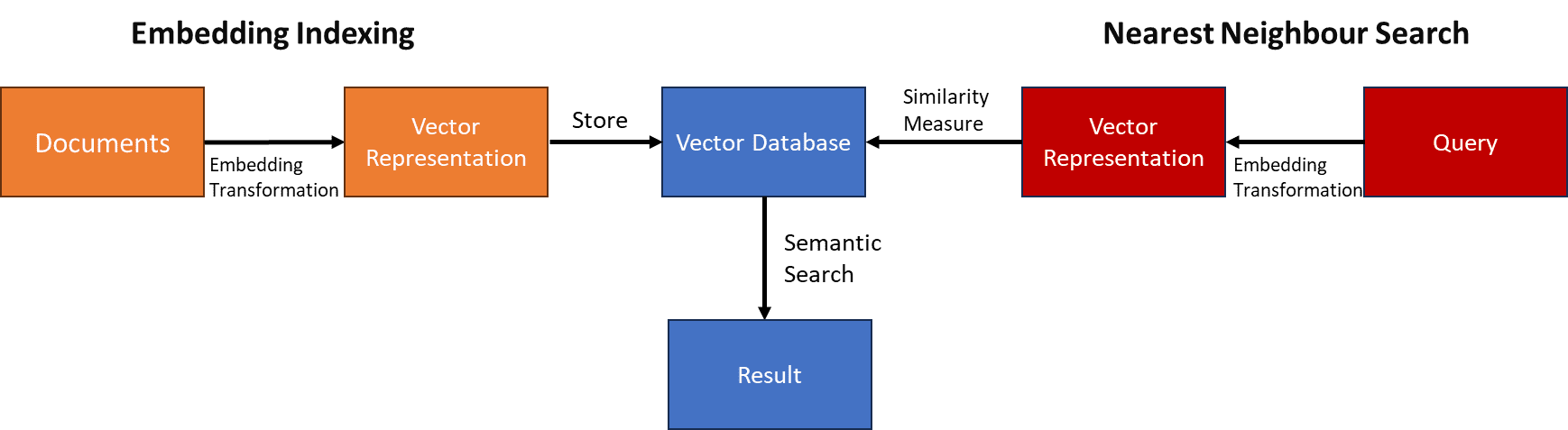
Nonetheless, sustaining the vector area that accommodates all of the coordinates can be an enormous job, particularly with a bigger corpus. The Vector database is preferable for storing the vector as an alternative of getting the entire vector area because it permits higher vector calculation and may preserve effectivity as the information grows.
The high-level strategy of Semantic Search with Vector Databases will be seen within the picture under.
Picture by Creator
Within the subsequent part, we are going to carry out a semantic search with a Python instance.
On this article, we are going to use an open-source Vector Database Weaviate. For tutorial functions, we additionally use Weaviate Cloud Service (WCS) to retailer our vector.
First, we have to set up the Weavieate Python Package deal.
pip set up weaviate-client
Then, please register for his or her free cluster through Weaviate Console and safe each the Cluster URL and the API Key.
As for the dataset instance, we’d use the Legal Text data from Kaggle. To make issues simpler, we’d additionally solely use the highest 100 rows of information.
import pandas as pd
knowledge = pd.read_csv('legal_text_classification.csv', nrows = 100)
Picture by Creator
Subsequent, we’d retailer all the information within the Vector Databases on Weaviate Cloud Service. To do this, we have to set the connection to the database.
import weaviate
import os
import requests
import json
cluster_url = "YOUR_CLUSTER_URL"
wcs_api_key = "YOUR_WCS_API_KEY"
Openai_api_key ="YOUR_OPENAI_API_KEY"
shopper = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
The subsequent factor we have to do is hook up with the Weaviate Cloud Service and create a category (like Desk in SQL) to retailer all of the textual content knowledge.
import weaviate.courses as wvc
shopper.join()
legal_cases = shopper.collections.create(
identify="LegalCases",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
Within the code above, we create a LegalCases class that makes use of the OpenAI Embedding mannequin. Within the background, no matter textual content object we’d retailer within the LegalCases class would undergo the OpenAI Embedding mannequin and be saved because the embedding vector.
Let’s attempt to retailer the Authorized textual content knowledge in a vector database. To do this, you should utilize the next code.
sent_to_vdb = knowledge.to_dict(orient="information")
legal_cases.knowledge.insert_many(sent_to_vdb)
You need to see within the Weaviate Cluster that your Authorized textual content is already saved there.
With the Vector Database prepared, let’s strive the Semantic Search. Weaviate API makes it simpler, as proven within the code under. Within the instance under, we are going to attempt to discover the instances that occur in Australia.
response = legal_cases.question.near_text(
question="Circumstances in Australia",
restrict=2
)
for i in vary(len(response.objects)):
print(response.objects[i].properties)
The result’s proven under.
{'case_title': 'Castlemaine Tooheys Ltd v South Australia [1986] HCA 58 ; (1986) 161 CLR 148', 'case_id': 'Case11', 'case_text': 'Hexal Australia Pty Ltd v Roche Therapeutics Inc (2005) 66 IPR 325, the probability of irreparable hurt was regarded by Stone J as, certainly, a separate component that needed to be established by an applicant for an interlocutory injunction. Her Honour cited the well-known passage from the judgment of Mason ACJ in Castlemaine Tooheys Ltd v South Australia [1986] HCA 58 ; (1986) 161 CLR 148 (at 153) as help for that proposition.', 'case_outcome': 'cited'}
{'case_title': 'Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd [2005] NSWSC 1247', 'case_id': 'Case97', 'case_text': 'each propositions are of some novelty in circumstances resembling the current, counsel is appropriate in submitting that there's some help to be derived from the choices of Younger CJ in Eq in Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd [2005] NSWSC 1247 and Austin J in Re Currabubula Holdings Pty Ltd (in liq); Ex parte Lord (2004) 48 ACSR 734; (2004) 22 ACLC 858, a minimum of as far as standing is worried.', 'case_outcome': 'cited'}
As you’ll be able to see, we have now two totally different outcomes. Within the first case, the phrase “Australia” was instantly talked about within the doc so it’s simpler to search out. Nonetheless, the second end result didn’t have any phrase “Australia” wherever. Nonetheless, Semantic Search can discover it as a result of there are phrases associated to the phrase “Australia” resembling “NSWSC” which stands for New South Wales Supreme Court docket, or the phrase “Currabubula” which is the village in Australia.
Conventional lexical matching may miss the second report, however the semantic search is far more correct because it takes into consideration the doc meanings.
That’s all the easy Semantic Search with Vector Database implementation.
Serps have dominated info acquisition on the web though the standard methodology with lexical match accommodates a flaw, which is that it fails to seize person intent. This limitation offers rise to the Semantic Search, a search engine methodology that may interpret the which means of doc queries. Enhanced with vector databases, semantic search functionality is much more environment friendly.
On this article, we have now explored how Semantic Search works and hands-on Python implementation with Open-Supply Weaviate Vector Databases. I hope it helps!
Cornellius Yudha Wijaya is an information science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and knowledge suggestions through social media and writing media. Cornellius writes on a wide range of AI and machine studying matters.