Nota AI Researchers Introduce LD-Pruner: A Novel Efficiency-Preserving Structured Pruning Technique for Compressing Latent Diffusion Fashions LDMs
Generative fashions have emerged as transformative instruments throughout varied domains, together with pc imaginative and prescient and pure language processing, by studying knowledge distributions and producing samples from them. Amongst these fashions, Diffusion Fashions (DMs) have garnered consideration for his or her means to supply high-quality pictures. Latent Diffusion Fashions (LDMs) stand out for his or her speedy era capabilities and lowered computational value. Nevertheless, deploying LDMs on resource-limited gadgets stays difficult resulting from important compute necessities, significantly from the Unet part.
Researchers have explored varied compression methods for LDMs to handle this problem, aiming to cut back computational overhead whereas sustaining efficiency. These methods embrace quantization, low-rank filter decomposition, token merging, and pruning. Pruning, historically used for compressing convolutional networks, has been tailored to DMs by way of strategies like Diff-Pruning, which identifies non-contributory diffusion steps and necessary weights to cut back computational complexity.
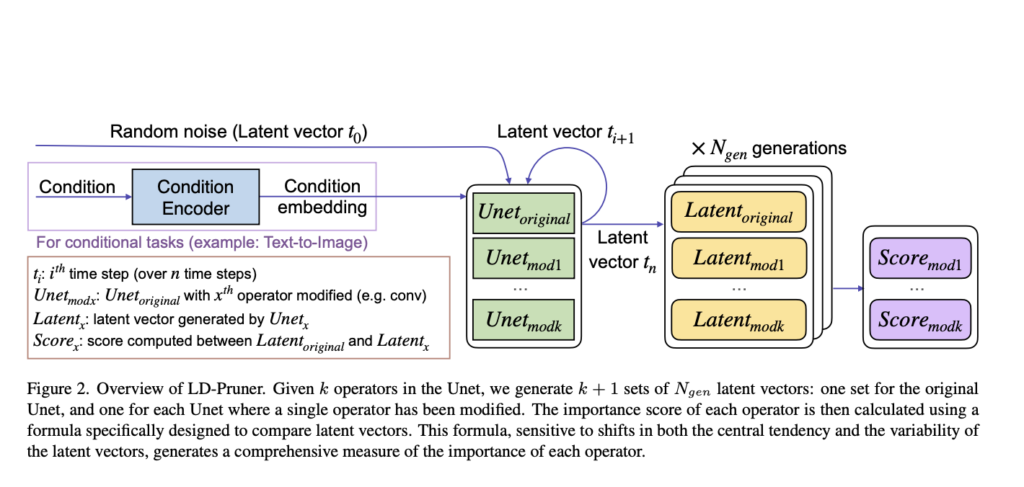
Whereas pruning gives promise for LDM compression, its adaptability and effectiveness throughout varied duties nonetheless have to be improved. Furthermore, evaluating pruning’s affect on generative fashions presents challenges as a result of complexity and resource-intensive nature of efficiency metrics like Frechet Inception Distance (FID). In response, the researchers from Nota AI suggest a novel task-agnostic metric for measuring the significance of particular person operators in LDMs, leveraging the latent house in the course of the pruning course of.
Their proposed method ensures independence from output varieties and enhances computational effectivity by working within the latent house, the place knowledge is compact. This enables for seamless adaptation to completely different duties with out requiring task-specific changes. The tactic successfully identifies and removes parts with minimal contribution to the output, leading to compressed fashions with quicker inference speeds and fewer parameters.
Their research introduces a complete metric for evaluating LDM latent and formulates a task-agnostic algorithm for compressing LDMs by way of architectural pruning. Experimental outcomes throughout varied duties exhibit the flexibility and effectiveness of the proposed method, promising wider applicability of LDMs in resource-constrained environments.
Moreover, their proposed method gives a nuanced understanding of the latent representations of LDMs by way of the novel metric, which is grounded in rigorous experimental evaluations and logical reasoning. By totally assessing every component of the metric’s design, the researchers guarantee its effectiveness in precisely and sensitively evaluating LDM latent. This stage of granularity enhances the interpretability of the pruning course of and permits exact identification of parts for removing whereas preserving output high quality.
Along with its technical contributions, their research showcases the proposed methodology’s sensible applicability throughout three distinct duties: text-to-image (T2I) era, Unconditional Picture Technology (UIG), and Unconditional Audio Technology (UAG). The profitable execution of those experiments underscores the method’s versatility and potential affect in various real-world situations. Their analysis validates the proposed methodology by demonstrating its effectiveness throughout a number of duties. It opens avenues for its adoption in varied purposes, additional advancing the sphere of generative modeling and compression methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 40k+ ML SubReddit
Arshad is an intern at MarktechPost. He’s at the moment pursuing his Int. MSc Physics from the Indian Institute of Expertise Kharagpur. Understanding issues to the basic stage results in new discoveries which result in development in expertise. He’s obsessed with understanding the character essentially with the assistance of instruments like mathematical fashions, ML fashions and AI.




