Vector Databases in AI and LLM Use Instances


Picture generated with Ideogram.ai
So, you would possibly hear all these Vector Database phrases. Some would possibly perceive about it, and a few may not. No worries if you happen to don’t learn about them, as Vector Databases have solely grow to be a extra distinguished matter in recent times.
Vector databases have risen in reputation due to the introduction of Generative AI to the general public, particularly the LLM.
Many LLM merchandise, corresponding to GPT-4 and Gemini, assist our work by offering textual content technology functionality for our enter. Nicely, vector databases truly play a component in these LLM merchandise.
However How did Vector Database work? And what are their relevances within the LLM?
The query above is what we might reply on this article. Nicely, Let’s discover them collectively.
A vector database is a specialised database storage designed to retailer, index, and question vector information. It’s usually optimized for high-dimensional vector information as normally it’s the output for the machine studying mannequin, particularly LLM.
Within the context of a Vector Database, the vector is a mathematical illustration of the information. Every vector consists of an array of numerical factors representing the information place. Vector is commonly used within the LLM to characterize the textual content information as a vector is less complicated to course of than the textual content information.
Within the LLM area, the mannequin may need a textual content enter and will remodel the textual content right into a high-dimensional vector representing the semantic and syntactic traits of the textual content. This course of is what we name Embedding. In easier phrases, embedding is a course of that transforms textual content into vectors with numerical information.
Embedding usually makes use of a Neural Community mannequin known as the Embedding Mannequin to characterize the textual content within the Embedding Area.
Let’s use an instance textual content: “I Love Information Science”. Representing them with the OpenAI mannequin text-embedding-3-small would lead to a vector with 1536 dimensions.
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
The quantity throughout the vector is the coordinate throughout the mannequin’s embedding area. Collectively, they might kind a novel illustration of the sentence which means coming from the mannequin.
Vector Database would then be answerable for storing these embedding mannequin outputs. The person then might question, index, and retrieve the vector as they want.
Possibly that’s sufficient introduction, and let’s get right into a extra technical hands-on. We might attempt to set up and retailer vectors with an open-source vector database known as Weaviate.
Weaviate is a scalable open-source Vector Database that serves as a framework to retailer our vector. We are able to run Weaviate in cases like Docker or use Weaviate Cloud Providers (WCS).
To begin utilizing Weaviate, we have to set up the packages utilizing the next code:
pip set up weaviate-client
To make issues simpler, we might use a sandbox cluster from WCS to behave as our Vector Database. Weaviate supplies a 14-day free cluster that we are able to use to retailer our vectors with out registering any fee methodology. To try this, it’s good to register on their WCS console initially.
As soon as throughout the WCS platform, choose Create a Cluster and enter your Sandbox title. The UI ought to appear like the picture beneath.
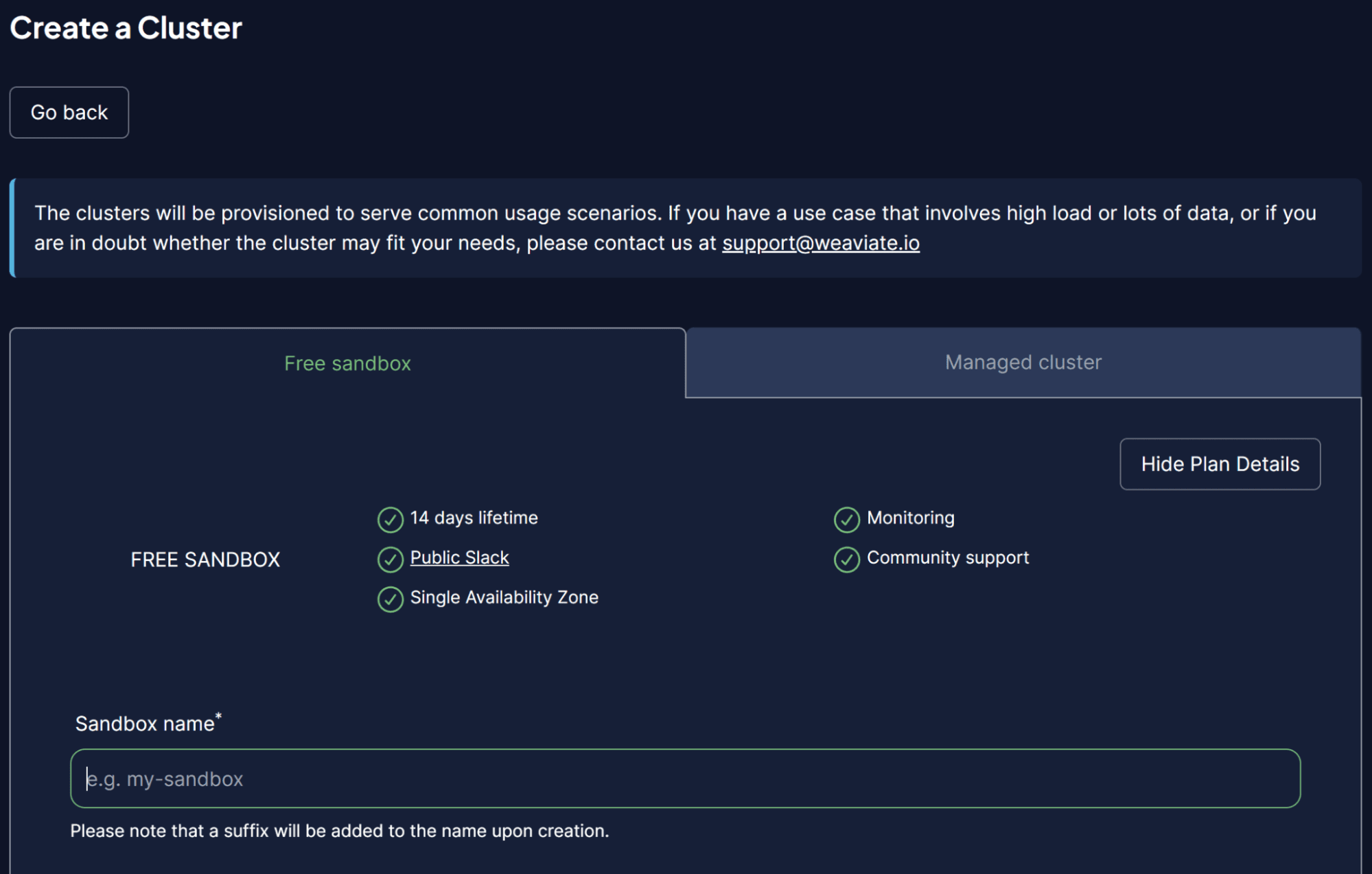
Picture by Writer
Don’t overlook to allow authentication, as we additionally wish to entry this cluster by way of the WCS API Key. After the cluster is prepared, discover the API key and Cluster URL, which we’ll use to entry the Vector Database.
As soon as issues are prepared, we might simulate storing our first vector within the Vector Database.
For the Vector Database storing instance, I might use the Book Collection instance dataset from Kaggle. I might solely use the highest 100 rows and three columns (title, description, intro).
import pandas as pd
information = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
Let’s put aside our information and hook up with our Vector Database. First, we have to arrange a distant connection utilizing the API key and your Cluster URL.
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
consumer = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
When you arrange your consumer variable, we’ll hook up with the Weaviate Cloud Service and create a category to retailer the vector. Class in Weaviate is the information assortment or analogs to the desk title in a relational database.
import weaviate.courses as wvc
consumer.join()
book_collection = consumer.collections.create(
title="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
Within the code above, we hook up with the Weaviate Cluster and create a BookCollection class. The category object additionally makes use of the OpenAI text2vec embedding mannequin to vectorize the textual content information and OpenAI generative module.
Let’s attempt to retailer the textual content information in a vector database. To try this, you need to use the next code.
sent_to_vdb = information.to_dict(orient="data")
book_collection.information.insert_many(sent_to_vdb)
Picture by Writer
We simply efficiently saved our dataset within the Vector Database! How straightforward is that?
Now, you could be curious in regards to the use circumstances for utilizing Vector Databases with LLM. That’s what we’re going to focus on subsequent.
A couple of use circumstances by which LLM could be utilized with Vector Database. Let’s discover them collectively.
Semantic Search
Semantic Search is a means of looking for information by utilizing the which means of the question to retrieve related outcomes somewhat than relying solely on the standard keyword-based search.
The method entails the utilization of the LLM Mannequin Embedding of the question and performing embedding similarity search into our saved embedded within the vector database.
Let’s attempt to use Weaviate to carry out a semantic search primarily based on a selected question.
book_collection = consumer.collections.get("BookCollection")
consumer.join()
response = book_collection.question.near_text(
question="childhood story,
restrict=2
)
Within the code above, we attempt to carry out a semantic search with Weaviate to seek out the highest two books carefully associated to the question childhood story. The semantic search makes use of the OpenAI embedding mannequin we beforehand arrange. The result’s what you may see in beneath.
{'title': 'Act Your Age', 'description': 'A younger lady is advised again and again to behave her age.', 'intro': 'Colleen Archer has written for nHighlightsn. On this brief story, a younger lady is advised again and again to behave her age.nAs you learn, take notes on what Frances is doing when she is advised to behave her age. '}
{'title': 'The Anklet', 'description': 'A younger lady should take care of unkind and spiteful remedy from her two older sisters.', 'intro': "Neil Philip is a author and poet who has retold the best-known tales from nThe Arabian Nightsn for a modern-day viewers. nThe Arabian Nightsn is the English-language nickname steadily given to nOne Thousand and One Arabian Nightsn, a set of people tales written and picked up within the Center East throughout the Islamic Golden Age of the eighth to thirteenth centuries. On this story, a poor younger lady should take care of mistreatment by members of her family.nAs you learn, take notes on the youngest sister's actions and emotions."}
As you may see, no direct phrases about childhood tales are within the end result above. Nonetheless, the end result remains to be carefully associated to a narrative that goals for youngsters.
Generative Search
The Generative Search might be outlined as an extension software for the Semantic Search. The Generative Search, or Retrieval Augmented Era (RAG), makes use of LLM prompting with the Semantic search that retrieved information from the vector database.
With RAG, the end result from the question search is processed to LLM, so we get them within the kind we would like as an alternative of the uncooked information. Let’s attempt a easy implementation of the RAG with Vector Database.
response = book_collection.generate.near_text(
question="childhood story",
restrict=2,
grouped_task="Write a brief LinkedIn publish about these books."
)
print(response.generated)
The end result could be seen within the textual content beneath.
Excited to share two fascinating brief tales that discover themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a younger lady who is continually advised to behave her age, whereas "The Anklet" by Neil Philip delves into the unkind remedy confronted by a younger lady from her older sisters. These thought-provoking tales will go away you reflecting on societal expectations and household dynamics. #ShortStories #Literature #BookRecommendations 📚
As you may see, the information content material is similar as earlier than however has now been processed with OpenAI LLM to offer a brief LinkedIn publish. On this manner, RAG is helpful after we need particular kind output from the information.
Query Answering with RAG
In our earlier instance, we used a question to get the information we wished, and RAG processed that information into the supposed output.
Nonetheless, we are able to flip the RAG functionality right into a question-answering device. We are able to obtain this by combining them with the LangChain framework.
First, let’s set up the mandatory packages.
pip set up langchain
pip set up langchain_community
pip set up langchain_openai
Then, let’s attempt to import the packages and provoke the variables we require to make QA with RAG work.
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name="gpt-3.5-turbo-instruct", temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
consumer = weaviate.Shopper(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
Within the code above, we arrange the LLM for the textual content technology, embedding mannequin, and the Weaviate consumer connection.
Subsequent, we set the Weaviate connection to the Vector Database.
weaviate_vectorstore = Weaviate(consumer=consumer, index_name="BookCollection", text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
Within the code above, make the Weaviate Database BookCollection the RAG device that may search the ‘intro’ function when prompted.
Then, we might create Query Answering Chain from the LangChain with the code beneath.
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
All the things is now prepared. Let’s check out the QA with RAG utilizing the next code instance.
response = qa_chain.invoke(
"Who's the author who write about love between two goldfish?")
print(response)
The result’s proven within the textual content beneath.
{'question': 'Who's the author who write about love between two goldfish?', 'end result': ' The author is Grace Chua.'}
With the Vector Database because the place to retailer all of the textual content information, we are able to implement RAG to carry out QA with LangChain. How neat is that?
A vector database is a specialised storage resolution designed to retailer, index, and question vector information. It’s usually used to retailer textual content information and carried out along side Giant Language Fashions (LLMs). This text will attempt a hands-on setup of the Vector Database Weaviate, together with instance use circumstances corresponding to Semantic Search, Retrieval-Augmented Era (RAG), and Query Answering with RAG.
Cornellius Yudha Wijaya is an information science assistant supervisor and information author. Whereas working full-time at Allianz Indonesia, he likes to share Python and information suggestions by way of social media and writing media. Cornellius writes on a wide range of AI and machine studying matters.