Researchers at CMU Introduce TriForce: A Hierarchical Speculative Decoding AI System that’s Scalable to Lengthy Sequence Era

With the widespread deployment of huge language fashions (LLMs) for lengthy content material technology, there’s a rising want for environment friendly long-sequence inference help. Nevertheless, the key-value (KV) cache, essential for avoiding re-computation, has develop into a important bottleneck, growing in measurement linearly with sequence size. The auto-regressive nature of LLMs necessitates loading your entire KV cache for every generated token, resulting in low computational core utilization and excessive latency. Whereas compression strategies have been proposed, they usually compromise technology high quality. LLMs like GPT-4, Gemini, and LWM are gaining prominence in functions like chatbots, imaginative and prescient technology, and monetary evaluation. Nevertheless, serving these LLMs effectively stays difficult because of the auto-regressive nature and the rising reminiscence footprint of the KV cache.
Prior methodologies suggest KV cache eviction methods to scale back the reminiscence footprint of the KV cache, selectively discarding pairs based mostly on eviction insurance policies. This permits fashions to function inside a restricted cache finances. Nevertheless, such methods face challenges as a result of potential info loss, resulting in points like hallucination and contextual incoherency, significantly in lengthy contexts. Speculative decoding, which includes utilizing a light-weight draft mannequin to foretell the following tokens, has been launched to speed up LLM inference whereas preserving mannequin output. Nevertheless, deploying this for lengthy sequence technology presents challenges, together with the necessity for substantial computation to coach draft fashions and the danger of poor speculating efficiency, particularly with current training-free strategies like KV cache eviction methods.
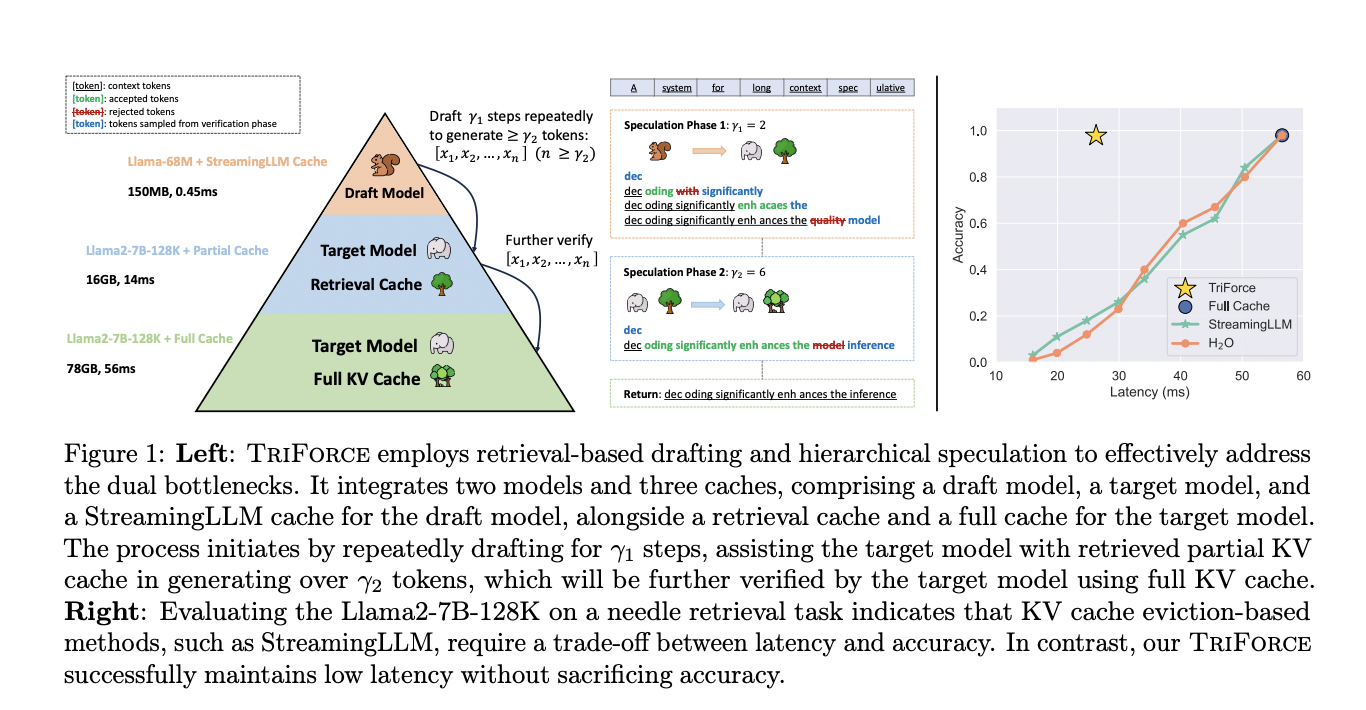
Researchers from Carnegie Mellon College and Meta AI (FAIR) Introduce TriForce, a hierarchical speculative decoding system designed for scalable lengthy sequence technology. TriForce makes use of the unique mannequin weights and dynamic sparse KV cache through retrieval as a draft mannequin, serving as an intermediate layer within the hierarchy. Sustaining the complete cache permits for superior KV cache choice utilizing retrieval-based drafting, characterised as lossless in comparison with eviction-based strategies like StreamingLLM and H2O. The hierarchical system addresses twin reminiscence bottlenecks, pairing a light-weight mannequin with a StreamingLLM cache for preliminary speculations to scale back drafting latency and speed up end-to-end inference.
TriForce introduces a hierarchical speculative decoding system with retrieval-based KV cache choice. The hierarchical system addresses twin bottlenecks, enhancing speed-up. Retrieval-based drafting segments the KV cache, highlighting related info. Light-weight fashions with StreamingLLM cache speed up preliminary speculations, decreasing drafting latency. TriForce makes use of mannequin weights and KV cache to boost LLM inference pace for lengthy sequences. The implementation makes use of Transformers, FlashAttention, and PyTorch CUDA graphs, sustaining full layer sparsity whereas minimizing kernel launching overhead.
TriForce analysis reveals important speedups, as much as 2.31× with a 4K KV cache for Llama2-7B128K on-chip. Offloading to shopper GPUs achieves exceptional effectivity, significantly with Llama2-13B-128K on two RTX 4090 GPUs, 7.94× quicker than optimized methods. Llama2-7B-128K with TriForce operates at 0.108s/token, half as gradual as auto-regressive baselines on A100. Batched inference additionally advantages, attaining 1.9× speedup for a batch measurement of six, every with 19K contexts.
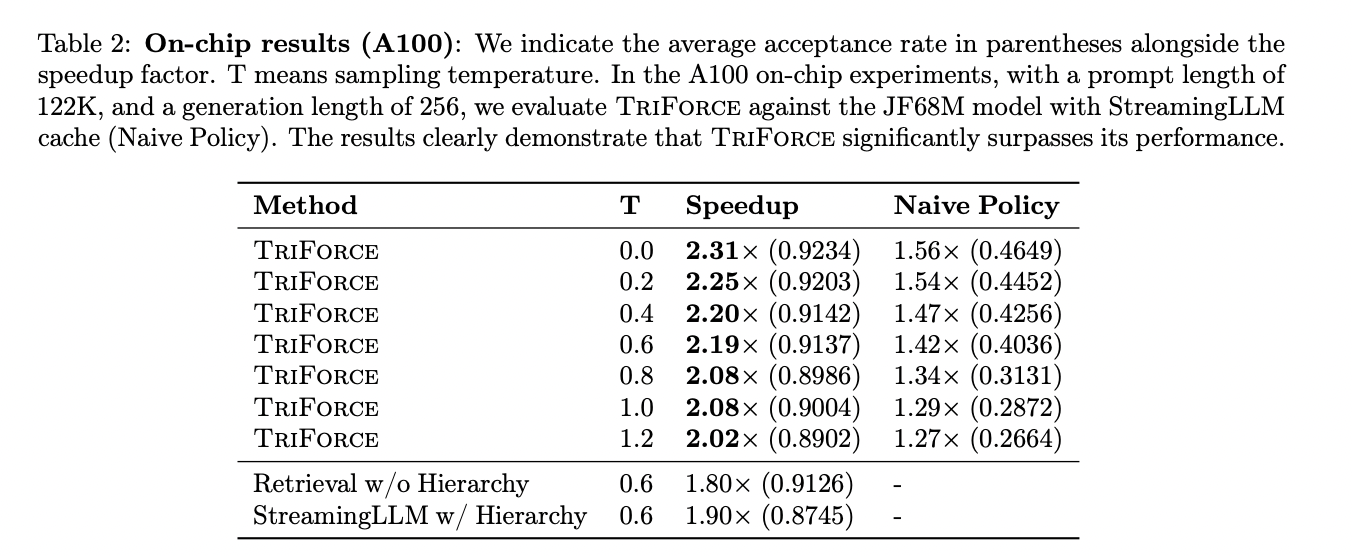
To conclude, this work introduces TriForce, a hierarchical speculative decoding system concentrating on the environment friendly serving of LLMs in lengthy contexts. TriForce addresses twin bottlenecks of KV cache and mannequin weights, yielding important speedups, together with as much as 2.31× on A100 GPUs and a unprecedented 7.78× on RTX 4090 GPUs. TriForce achieves 0.108s/token, half as gradual as auto-regressive baselines on A100. In comparison with DeepSpeed-Zero-Inference, TriForce on a single RTX 4090 GPU is 4.86× quicker and attains a 1.9× speedup with giant batches, showcasing its potential for revolutionizing long-context mannequin serving.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 40k+ ML SubReddit
For Content material Partnership, Please Fill Out This Form Here..
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.