Open supply observability for AWS Inferentia nodes inside Amazon EKS clusters
Latest developments in machine studying (ML) have led to more and more giant fashions, a few of which require lots of of billions of parameters. Though they’re extra highly effective, coaching and inference on these fashions require important computational assets. Regardless of the supply of superior distributed coaching libraries, it’s frequent for coaching and inference jobs to wish lots of of accelerators (GPUs or purpose-built ML chips similar to AWS Trainium and AWS Inferentia), and due to this fact tens or lots of of situations.
In such distributed environments, observability of each situations and ML chips turns into key to mannequin efficiency fine-tuning and value optimization. Metrics permit groups to grasp workload conduct and optimize useful resource allocation and utilization, diagnose anomalies, and enhance total infrastructure effectivity. For knowledge scientists, ML chips utilization and saturation are additionally related for capability planning.
This publish walks you thru the Open Source Observability pattern for AWS Inferentia, which reveals you the way to monitor the efficiency of ML chips, utilized in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster, with knowledge aircraft nodes based mostly on Amazon Elastic Compute Cloud (Amazon EC2) situations of sort Inf1 and Inf2.
The sample is a part of the AWS CDK Observability Accelerator, a set of opinionated modules that can assist you set observability for Amazon EKS clusters. The AWS CDK Observability Accelerator is organized round patterns, that are reusable models for deploying a number of assets. The open supply observability set of patterns devices observability with Amazon Managed Grafana dashboards, an AWS Distro for OpenTelemetry collector to gather metrics, and Amazon Managed Service for Prometheus to retailer them.
Answer overview
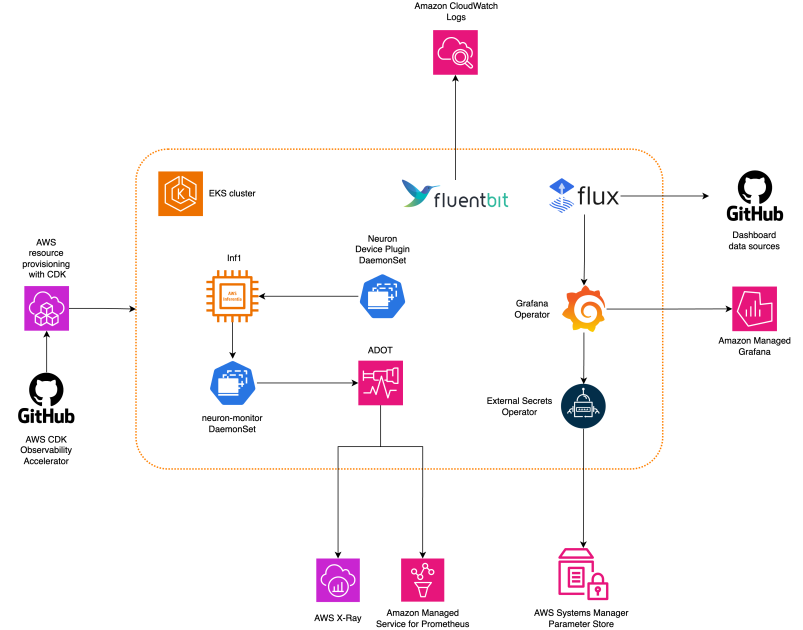
The next diagram illustrates the answer structure.

This answer deploys an Amazon EKS cluster with a node group that features Inf1 situations.
The AMI sort of the node group is AL2_x86_64_GPU, which makes use of the Amazon EKS optimized accelerated Amazon Linux AMI. Along with the usual Amazon EKS-optimized AMI configuration, the accelerated AMI contains the NeuronX runtime.
To entry the ML chips from Kubernetes, the sample deploys the AWS Neuron system plugin.
Metrics are uncovered to Amazon Managed Service for Prometheus by the neuron-monitor DaemonSet, which deploys a minimal container, with the Neuron tools put in. Particularly, the neuron-monitor DaemonSet runs the neuron-monitor command piped into the neuron-monitor-prometheus.py companion script (each instructions are a part of the container):
The command makes use of the next parts:
neuron-monitorcollects metrics and stats from the Neuron purposes working on the system and streams the collected knowledge to stdout in JSON formatneuron-monitor-prometheus.pymaps and exposes the telemetry knowledge from JSON format into Prometheus-compatible format
Information is visualized in Amazon Managed Grafana by the corresponding dashboard.
The remainder of the setup to gather and visualize metrics with Amazon Managed Service for Prometheus and Amazon Managed Grafana is just like that utilized in different open supply based mostly patterns, that are included within the AWS Observability Accelerator for CDK GitHub repository.
Stipulations
You want the next to finish the steps on this publish:
Arrange the surroundings
Full the next steps to arrange your surroundings:
- Open a terminal window and run the next instructions:
- Retrieve the workspace IDs of any current Amazon Managed Grafana workspace:
The next is our pattern output:
- Assign the values of
idandendpointto the next surroundings variables:
COA_AMG_ENDPOINT_URL wants to incorporate https://.
- Create a Grafana API key from the Amazon Managed Grafana workspace:
- Arrange a secret in AWS Systems Manager:
The key can be accessed by the Exterior Secrets and techniques add-on and made out there as a local Kubernetes secret within the EKS cluster.
Bootstrap the AWS CDK surroundings
Step one to any AWS CDK deployment is bootstrapping the surroundings. You utilize the cdk bootstrap command within the AWS CDK CLI to organize the surroundings (a mixture of AWS account and AWS Area) with assets required by AWS CDK to carry out deployments into that surroundings. AWS CDK bootstrapping is required for every account and Area mixture, so if you happen to already bootstrapped AWS CDK in a Area, you don’t must repeat the bootstrapping course of.
Deploy the answer
Full the next steps to deploy the answer:
- Clone the cdk-aws-observability-accelerator repository and set up the dependency packages. This repository accommodates AWS CDK v2 code written in TypeScript.
The precise settings for Grafana dashboard JSON recordsdata are anticipated to be specified within the AWS CDK context. That you must replace context within the cdk.json file, situated within the present listing. The situation of the dashboard is specified by the fluxRepository.values.GRAFANA_NEURON_DASH_URL parameter, and neuronNodeGroup is used to set the occasion sort, quantity, and Amazon Elastic Block Store (Amazon EBS) measurement used for the nodes.
- Enter the next snippet into
cdk.json, changingcontext:
You may exchange the Inf1 occasion sort with Inf2 and alter the scale as wanted. To test availability in your chosen Area, run the next command (amend Values as you see match):
- Set up the venture dependencies:
- Run the next instructions to deploy the open supply observability sample:
Validate the answer
Full the next steps to validate the answer:
- Run the
update-kubeconfigcommand. It is best to be capable of get the command from the output message of the earlier command:
- Confirm the assets you created:
The next screenshot reveals our pattern output.

- Be sure that the
neuron-device-plugin-daemonsetDaemonSet is working:
The next is our anticipated output:
- Affirm that the
neuron-monitorDaemonSet is working:
The next is our anticipated output:
- To confirm that the Neuron units and cores are seen, run the
neuron-lsandneuron-topinstructions from, for instance, your neuron-monitor pod (you will get the pod’s title from the output ofkubectl get pods -A):
The next screenshot reveals our anticipated output.

The next screenshot reveals our anticipated output.

Visualize knowledge utilizing the Grafana Neuron dashboard
Log in to your Amazon Managed Grafana workspace and navigate to the Dashboards panel. It is best to see a dashboard named Neuron / Monitor.
To see some fascinating metrics on the Grafana dashboard, we apply the next manifest:
It is a pattern workload that compiles the torchvision ResNet50 model and runs repetitive inference in a loop to generate telemetry knowledge.
To confirm the pod was efficiently deployed, run the next code:
It is best to see a pod named pytorch-inference-resnet50.
After a couple of minutes, trying into the Neuron / Monitor dashboard, you need to see the gathered metrics just like the next screenshots.




Grafana Operator and Flux at all times work collectively to synchronize your dashboards with Git. If you happen to delete your dashboards by chance, they are going to be re-provisioned robotically.
Clear up
You may delete the entire AWS CDK stack with the next command:
Conclusion
On this publish, we confirmed you the way to introduce observability, with open supply tooling, into an EKS cluster that includes an information aircraft working EC2 Inf1 situations. We began by choosing the Amazon EKS-optimized accelerated AMI for the information aircraft nodes, which incorporates the Neuron container runtime, offering entry to AWS Inferentia and Trainium Neuron units. Then, to reveal the Neuron cores and units to Kubernetes, we deployed the Neuron system plugin. The precise assortment and mapping of telemetry knowledge into Prometheus-compatible format was achieved through neuron-monitor and neuron-monitor-prometheus.py. Metrics have been sourced from Amazon Managed Service for Prometheus and displayed on the Neuron dashboard of Amazon Managed Grafana.
We suggest that you simply discover extra observability patterns within the AWS Observability Accelerator for CDK GitHub repo. To be taught extra about Neuron, confer with the AWS Neuron Documentation.
Concerning the Creator
 Riccardo Freschi is a Sr. Options Architect at AWS, specializing in software modernization. He works carefully with companions and clients to assist them rework their IT landscapes of their journey to the AWS Cloud by refactoring current purposes and constructing new ones.
Riccardo Freschi is a Sr. Options Architect at AWS, specializing in software modernization. He works carefully with companions and clients to assist them rework their IT landscapes of their journey to the AWS Cloud by refactoring current purposes and constructing new ones.





