Google DeepMind Presents Combination-of-Depths: Optimizing Transformer Fashions for Dynamic Useful resource Allocation and Enhanced Computational Sustainability

The transformer mannequin has emerged as a cornerstone expertise in AI, revolutionizing duties comparable to language processing and machine translation. These fashions allocate computational sources uniformly throughout enter sequences, a way that, whereas easy, overlooks the nuanced variability within the computational calls for of various elements of the info. This one-size-fits-all strategy typically results in inefficiencies, as not all sequence segments are equally advanced or require the identical degree of consideration.
Researchers from Google DeepMind, McGill College, and Mila have launched a groundbreaking technique referred to as Combination-of-Depths (MoD), which diverges from the normal uniform useful resource allocation mannequin. MoD empowers transformers to dynamically distribute computational sources, specializing in probably the most pivotal tokens inside a sequence. This technique represents a paradigm shift in managing computational sources and guarantees substantial effectivity and efficiency enhancements.
MoD’s innovation lies in its skill to regulate computational focus inside a transformer mannequin dynamically, making use of extra sources to elements of the enter sequence which can be deemed extra crucial for the duty at hand. The approach operates underneath a hard and fast computational price range, strategically choosing tokens for processing primarily based on a routing mechanism that evaluates their significance. This strategy drastically reduces pointless computations, successfully slashing the transformer’s operational calls for whereas sustaining or enhancing its efficiency.
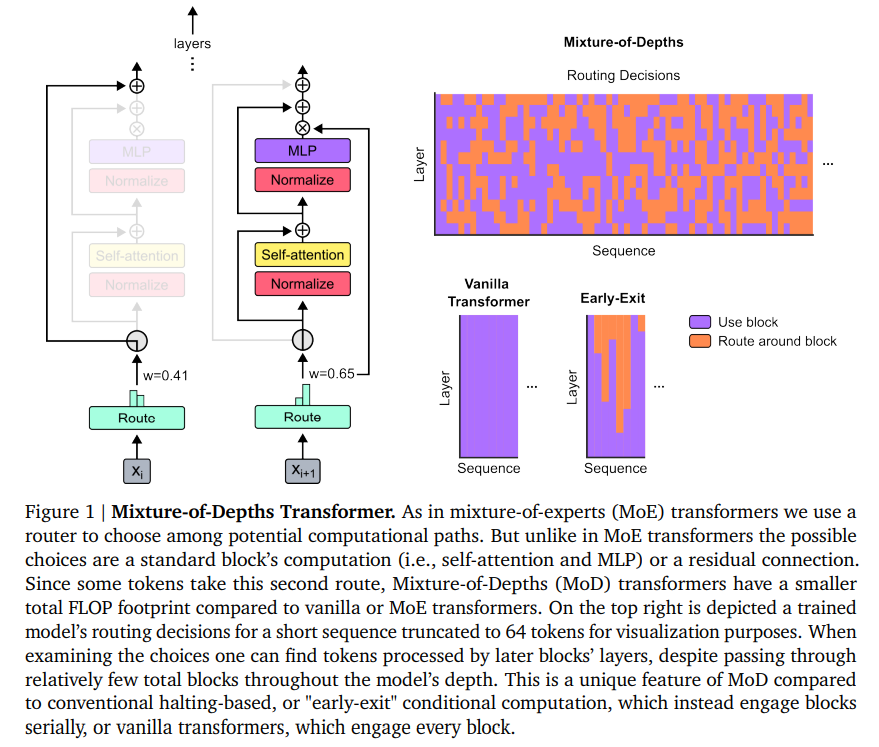
MoD-equipped fashions demonstrated the flexibility to keep up baseline efficiency ranges with considerably diminished computational masses. For instance, fashions may obtain coaching aims with an identical Flops (floating-point operations per second) to traditional transformers however required as much as 50% fewer Flops per ahead cross. These fashions may function as much as 60% sooner in sure coaching situations, showcasing the tactic’s functionality to considerably increase effectivity with out compromising the standard of outcomes.

In conclusion, the precept of dynamic compute allocation is revolutionizing effectivity, with MoD underscoring this development. By illustrating that not all tokens require equal computational effort, with some demanding extra sources for correct predictions, this technique paves the best way for important compute financial savings. The MoD technique presents a transformative strategy to optimizing transformer fashions by dynamically allocating computational sources addressing inherent inefficiencies in conventional fashions. This breakthrough signifies a shift in direction of scalable, adaptive computing for LLMs.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our newsletter..
Don’t Neglect to affix our 39k+ ML SubReddit
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at present pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m keen about expertise and need to create new merchandise that make a distinction.





