Improve efficiency of generative language fashions with self-consistency prompting on Amazon Bedrock
Generative language fashions have confirmed remarkably skillful at fixing logical and analytical pure language processing (NLP) duties. Moreover, using prompt engineering can notably improve their efficiency. For instance, chain-of-thought (CoT) is thought to enhance a mannequin’s capability for complicated multi-step issues. To moreover increase accuracy on duties that contain reasoning, a self-consistency prompting strategy has been steered, which replaces grasping with stochastic decoding throughout language technology.
Amazon Bedrock is a totally managed service that gives a alternative of high-performing basis fashions from main AI corporations and Amazon by way of a single API, together with a broad set of capabilities to construct generative AI functions with safety, privateness, and accountable AI. With the batch inference API, you need to use Amazon Bedrock to run inference with basis fashions in batches and get responses extra effectively. This publish exhibits the best way to implement self-consistency prompting by way of batch inference on Amazon Bedrock to boost mannequin efficiency on arithmetic and multiple-choice reasoning duties.
Overview of answer
Self-consistency prompting of language fashions depends on the technology of a number of responses which might be aggregated right into a remaining reply. In distinction to single-generation approaches like CoT, the self-consistency sample-and-marginalize process creates a variety of mannequin completions that result in a extra constant answer. The technology of various responses for a given immediate is feasible because of using a stochastic, slightly than grasping, decoding technique.
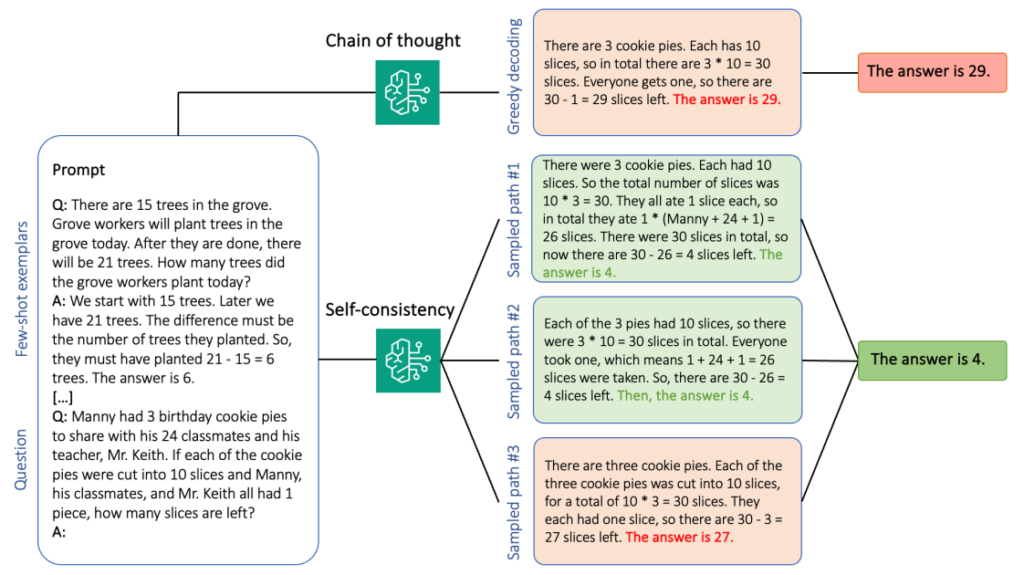
The next determine exhibits how self-consistency differs from grasping CoT in that it generates a various set of reasoning paths and aggregates them to provide the ultimate reply.

Decoding methods for textual content technology
Textual content generated by decoder-only language fashions unfolds phrase by phrase, with the next token being predicted on the premise of the previous context. For a given immediate, the mannequin computes a likelihood distribution indicating the chance of every token to look subsequent within the sequence. Decoding entails translating these likelihood distributions into precise textual content. Textual content technology is mediated by a set of inference parameters which might be usually hyperparameters of the decoding methodology itself. One instance is the temperature, which modulates the likelihood distribution of the subsequent token and influences the randomness of the mannequin’s output.
Greedy decoding is a deterministic decoding technique that at every step selects the token with the very best likelihood. Though simple and environment friendly, the strategy dangers falling into repetitive patterns, as a result of it disregards the broader likelihood house. Setting the temperature parameter to 0 at inference time primarily equates to implementing grasping decoding.
Sampling introduces stochasticity into the decoding course of by randomly deciding on every subsequent token based mostly on the expected likelihood distribution. This randomness ends in larger output variability. Stochastic decoding proves more proficient at capturing the range of potential outputs and sometimes yields extra imaginative responses. Greater temperature values introduce extra fluctuations and enhance the creativity of the mannequin’s response.
Prompting methods: CoT and self-consistency
The reasoning capability of language fashions will be augmented by way of immediate engineering. Particularly, CoT has been proven to elicit reasoning in complicated NLP duties. One method to implement a zero-shot CoT is by way of immediate augmentation with the instruction to “assume step-by-step.” One other is to reveal the mannequin to exemplars of intermediate reasoning steps in few-shot prompting trend. Each situations usually use grasping decoding. CoT results in important efficiency beneficial properties in comparison with easy instruction prompting on arithmetic, commonsense, and symbolic reasoning duties.
Self-consistency prompting is predicated on the idea that introducing variety within the reasoning course of will be helpful to assist fashions converge on the right reply. The approach makes use of stochastic decoding to attain this purpose in three steps:
- Immediate the language mannequin with CoT exemplars to elicit reasoning.
- Change grasping decoding with a sampling technique to generate a various set of reasoning paths.
- Combination the outcomes to search out essentially the most constant reply within the response set.
Self-consistency is proven to outperform CoT prompting on standard arithmetic and commonsense reasoning benchmarks. A limitation of the strategy is its bigger computational value.
This publish exhibits how self-consistency prompting enhances efficiency of generative language fashions on two NLP reasoning duties: arithmetic problem-solving and multiple-choice domain-specific query answering. We display the strategy utilizing batch inference on Amazon Bedrock:
- We entry the Amazon Bedrock Python SDK in JupyterLab on an Amazon SageMaker pocket book occasion.
- For arithmetic reasoning, we immediate Cohere Command on the GSM8K dataset of grade faculty math issues.
- For multiple-choice reasoning, we immediate AI21 Labs Jurassic-2 Mid on a small pattern of questions from the AWS Licensed Options Architect – Affiliate examination.
Stipulations
This walkthrough assumes the next conditions:

The estimated value to run the code proven on this publish is $100, assuming you run self-consistency prompting one time with 30 reasoning paths utilizing one worth for the temperature-based sampling.
Dataset to probe arithmetic reasoning capabilities
GSM8K is a dataset of human-assembled grade faculty math issues that includes a excessive linguistic variety. Every drawback takes 2–8 steps to unravel and requires performing a sequence of elementary calculations with primary arithmetic operations. This information is usually used to benchmark the multi-step arithmetic reasoning capabilities of generative language fashions. The GSM8K train set contains 7,473 data. The next is an instance:
{"query": "Natalia offered clips to 48 of her pals in April, after which she offered half as many clips in Might. What number of clips did Natalia promote altogether in April and Might?", "reply": "Natalia offered 48/2 = <<48/2=24>>24 clips in Might.nNatalia offered 48+24 = <<48+24=72>>72 clips altogether in April and Might.n#### 72"}
Set as much as run batch inference with Amazon Bedrock
Batch inference means that you can run a number of inference calls to Amazon Bedrock asynchronously and enhance the efficiency of mannequin inference on massive datasets. The service is in preview as of this writing and solely obtainable via the API. Seek advice from Run batch inference to entry batch inference APIs by way of customized SDKs.
After you will have downloaded and unzipped the Python SDK in a SageMaker pocket book occasion, you may set up it by operating the next code in a Jupyter pocket book cell:
Format and add enter information to Amazon S3
Enter information for batch inference must be ready in JSONL format with recordId and modelInput keys. The latter ought to match the physique subject of the mannequin to be invoked on Amazon Bedrock. Particularly, some supported inference parameters for Cohere Command are temperature for randomness, max_tokens for output size, and num_generations to generate a number of responses, all of that are handed along with the immediate as modelInput:
See Inference parameters for foundation models for extra particulars, together with different mannequin suppliers.
Our experiments on arithmetic reasoning are carried out within the few-shot setting with out customizing or fine-tuning Cohere Command. We use the identical set of eight few-shot exemplars from the chain-of-thought (Table 20) and self-consistency (Table 17) papers. Prompts are created by concatenating the exemplars with every query from the GSM8K practice set.
We set max_tokens to 512 and num_generations to five, the utmost allowed by Cohere Command. For grasping decoding, we set temperature to 0 and for self-consistency, we run three experiments at temperatures 0.5, 0.7, and 1. Every setting yields totally different enter information in keeping with the respective temperature values. Information is formatted as JSONL and saved in Amazon S3.
Create and run batch inference jobs in Amazon Bedrock
Batch inference job creation requires an Amazon Bedrock consumer. We specify the S3 enter and output paths and provides every invocation job a singular identify:
Jobs are created by passing the IAM function, mannequin ID, job identify, and enter/output configuration as parameters to the Amazon Bedrock API:
Listing, monitoring, and stopping batch inference jobs is supported by their respective API calls. On creation, jobs seem first as Submitted, then as InProgress, and eventually as Stopped, Failed, or Accomplished.
If the roles are efficiently full, the generated content material will be retrieved from Amazon S3 utilizing its distinctive output location.
[Out]: 'Natalia offered 48 * 1/2 = 24 clips much less in Might. This implies she offered 48 + 24 = 72 clips in April and Might. The reply is 72.'
Self-consistency enhances mannequin accuracy on arithmetic duties
Self-consistency prompting of Cohere Command outperforms a grasping CoT baseline by way of accuracy on the GSM8K dataset. For self-consistency, we pattern 30 unbiased reasoning paths at three totally different temperatures, with topP and topK set to their default values. Closing options are aggregated by selecting essentially the most constant incidence by way of majority voting. In case of a tie, we randomly select one of many majority responses. We compute accuracy and normal deviation values averaged over 100 runs.
The next determine exhibits the accuracy on the GSM8K dataset from Cohere Command prompted with grasping CoT (blue) and self-consistency at temperature values 0.5 (yellow), 0.7 (inexperienced), and 1.0 (orange) as a operate of the variety of sampled reasoning paths.

The previous determine exhibits that self-consistency enhances arithmetic accuracy over grasping CoT when the variety of sampled paths is as little as three. Efficiency will increase constantly with additional reasoning paths, confirming the significance of introducing variety within the thought technology. Cohere Command solves the GSM8K query set with 51.7% accuracy when prompted with CoT vs. 68% with 30 self-consistent reasoning paths at T=1.0. All three surveyed temperature values yield comparable outcomes, with decrease temperatures being comparatively extra performant at much less sampled paths.
Sensible issues on effectivity and value
Self-consistency is proscribed by the elevated response time and value incurred when producing a number of outputs per immediate. As a sensible illustration, batch inference for grasping technology with Cohere Command on 7,473 GSM8K data completed in lower than 20 minutes. The job took 5.5 million tokens as enter and generated 630,000 output tokens. At present Amazon Bedrock inference prices, the whole value incurred was round $9.50.
For self-consistency with Cohere Command, we use inference parameter num_generations to create a number of completions per immediate. As of this writing, Amazon Bedrock permits a most of 5 generations and three concurrent Submitted batch inference jobs. Jobs proceed to the InProgress standing sequentially, subsequently sampling greater than 5 paths requires a number of invocations.
The next determine exhibits the runtimes for Cohere Command on the GSM8K dataset. Whole runtime is proven on the x axis and runtime per sampled reasoning path on the y axis. Grasping technology runs within the shortest time however incurs a better time value per sampled path.

Grasping technology completes in lower than 20 minutes for the total GSM8K set and samples a singular reasoning path. Self-consistency with 5 samples requires about 50% longer to finish and prices round $14.50, however produces 5 paths (over 500%) in that point. Whole runtime and value enhance step-wise with each additional 5 sampled paths. A value-benefit evaluation means that 1–2 batch inference jobs with 5–10 sampled paths is the really helpful setting for sensible implementation of self-consistency. This achieves enhanced mannequin efficiency whereas preserving value and latency at bay.
Self-consistency enhances mannequin efficiency past arithmetic reasoning
An important query to show the suitability of self-consistency prompting is whether or not the strategy succeeds throughout additional NLP duties and language fashions. As an extension to an Amazon-related use case, we carry out a small-sized evaluation on pattern questions from the AWS Solutions Architect Associate Certification. This can be a multiple-choice examination on AWS know-how and providers that requires area data and the flexibility to purpose and determine amongst a number of choices.
We put together a dataset from SAA-C01 and SAA-C03 pattern examination questions. From the 20 obtainable questions, we use the primary 4 as few-shot exemplars and immediate the mannequin to reply the remaining 16. This time, we run inference with the AI21 Labs Jurassic-2 Mid mannequin and generate a most of 10 reasoning paths at temperature 0.7. Outcomes present that self-consistency enhances efficiency: though grasping CoT produces 11 right solutions, self-consistency succeeds on 2 extra.
The next desk exhibits the accuracy outcomes for five and 10 sampled paths averaged over 100 runs.
| . | Grasping decoding | T = 0.7 |
| # sampled paths: 5 | 68.6 | 74.1 ± 0.7 |
| # sampled paths: 10 | 68.6 | 78.9 ± 0.3 |
Within the following desk, we current two examination questions which might be incorrectly answered by grasping CoT whereas self-consistency succeeds, highlighting in every case the right (inexperienced) or incorrect (purple) reasoning traces that led the mannequin to provide right or incorrect responses. Though not each sampled path generated by self-consistency is right, the bulk converges on the true reply because the variety of sampled paths will increase. We observe that 5–10 paths are usually sufficient to enhance over the grasping outcomes, with diminishing returns by way of effectivity previous these values.
| Query |
An online utility permits prospects to add orders to an S3 bucket. The ensuing Amazon S3 occasions set off a Lambda operate that inserts a message to an SQS queue. A single EC2 occasion reads messages from the queue, processes them, and shops them in a DynamoDB desk partitioned by distinctive order ID. Subsequent month visitors is predicted to extend by an element of 10 and a Options Architect is reviewing the structure for attainable scaling issues. Which part is MOST more likely to want re-architecting to have the ability to scale to accommodate the brand new visitors? A. Lambda operate |
An utility operating on AWS makes use of an Amazon Aurora Multi-AZ DB cluster deployment for its database. When evaluating efficiency metrics, a options architect found that the database reads are inflicting excessive I/O and including latency to the write requests in opposition to the database. What ought to the options architect do to separate the learn requests from the write requests? A. Allow read-through caching on the Aurora database. |
| Appropriate reply | C – A single EC2 occasion is not going to scale and is a single level of failure within the structure. A a lot better answer can be to have EC2 cases in an Auto Scaling group throughout 2 availability zones learn messages from the queue. The opposite responses are all managed providers that may be configured to scale or will scale mechanically. | C – Aurora Replicas present a method to offload learn visitors. Aurora Replicas share the identical underlying storage as the principle database, so lag time is mostly very low. Aurora Replicas have their very own endpoints, so the appliance will must be configured to direct learn visitors to the brand new endpoints. |
| Grasping decoding | Scaling the EC2 occasion immediately might not be attainable, because it might not be attainable to resize the occasion. Scaling the Lambda operate might not be adequate, as Lambda features have a 6 GB of reminiscence allocation restrict. Scaling the SQS queue might not be adequate, as SQS has a ten,000 message restrict. DynamoDB tables will be scaled by provisioning extra capability items. The right reply is D. | Modifying the appliance to learn from the Multi-AZ standby occasion (choice B) is the very best strategy. The standby occasion is asynchronously replicated from the first occasion, so learn operations is not going to intervene with write operations. Enabling read-through caching (choice A) or creating an Aurora duplicate (choice C) is not going to remedy the I/O competition subject. Making a second Aurora database and linking it as a learn duplicate (choice D) is not going to remedy the I/O competition subject both. The right reply is B. |
| Sampled path #1 | Scaling the EC2 occasion to 10 instances its present dimension might not be possible, both from a price or efficiency perspective. It could require a bigger occasion, which will be costly. A more cost effective strategy is likely to be to make use of a swarm of smaller cases (e.g., Auto Scaling Group) to share the load. On this case, the EC2 occasion would probably must be re-architected. The right reply is C. | Modifying the appliance to make use of the suitable endpoints isn’t a sensible answer as it will require adjustments to the appliance code. The right reply is C: Create an Aurora duplicate and modify the appliance to make use of the suitable endpoints. |
| Sampled path #2 | Scaling a single EC2 occasion is harder and problematic than scaling the opposite service parts. Amazon SQS, Lambda, and DynamoDB can all scale mechanically to deal with the elevated load. The right reply is C. |
(C) Create an Aurora duplicate and modify the appliance to make use of the suitable endpoints. By configuring an Aurora Duplicate, you may separate learn visitors from write visitors. The Aurora Replicas use totally different endpoint URLs, permitting you to direct learn visitors to the duplicate as an alternative of the first database. The duplicate can course of learn requests in parallel with write requests to the first database, decreasing I/O and latency. |
Clear up
Working batch inference in Amazon Bedrock is topic to expenses in keeping with the Amazon Bedrock Pricing. If you full the walkthrough, delete your SageMaker pocket book occasion and take away all information out of your S3 buckets to keep away from incurring future expenses.
Issues
Though the demonstrated answer exhibits improved efficiency of language fashions when prompted with self-consistency, it’s essential to notice that the walkthrough isn’t production-ready. Earlier than you deploy to manufacturing, you must adapt this proof of idea to your individual implementation, preserving in thoughts the next necessities:
- Entry restriction to APIs and databases to stop unauthorized utilization.
- Adherence to AWS safety greatest practices concerning IAM function entry and safety teams.
- Validation and sanitization of person enter to stop immediate injection assaults.
- Monitoring and logging of triggered processes to allow testing and auditing.
Conclusion
This publish exhibits that self-consistency prompting enhances efficiency of generative language fashions in complicated NLP duties that require arithmetic and multiple-choice logical expertise. Self-consistency makes use of temperature-based stochastic decoding to generate numerous reasoning paths. This will increase the flexibility of the mannequin to elicit numerous and helpful ideas to reach at right solutions.
With Amazon Bedrock batch inference, the language mannequin Cohere Command is prompted to generate self-consistent solutions to a set of arithmetic issues. Accuracy improves from 51.7% with grasping decoding to 68% with self-consistency sampling 30 reasoning paths at T=1.0. Sampling 5 paths already enhances accuracy by 7.5 % factors. The strategy is transferable to different language fashions and reasoning duties, as demonstrated by outcomes of the AI21 Labs Jurassic-2 Mid mannequin on an AWS Certification examination. In a small-sized query set, self-consistency with 5 sampled paths will increase accuracy by 5 % factors over grasping CoT.
We encourage you to implement self-consistency prompting for enhanced efficiency in your individual functions with generative language fashions. Be taught extra about Cohere Command and AI21 Labs Jurassic fashions obtainable on Amazon Bedrock. For extra details about batch inference, discuss with Run batch inference.
Acknowledgements
The creator thanks technical reviewers Amin Tajgardoon and Patrick McSweeney for useful suggestions.
In regards to the Writer

Lucía Santamaría is a Sr. Utilized Scientist at Amazon’s ML College, the place she’s centered on elevating the extent of ML competency throughout the corporate via hands-on training. Lucía has a PhD in astrophysics and is obsessed with democratizing entry to tech data and instruments.




