Unlock the potential of generative AI in industrial operations
Within the evolving panorama of producing, the transformative energy of AI and machine studying (ML) is clear, driving a digital revolution that streamlines operations and boosts productiveness. Nevertheless, this progress introduces distinctive challenges for enterprises navigating data-driven options. Industrial amenities grapple with huge volumes of unstructured knowledge, sourced from sensors, telemetry techniques, and tools dispersed throughout manufacturing strains. Actual-time knowledge is essential for functions like predictive upkeep and anomaly detection, but creating customized ML fashions for every industrial use case with such time collection knowledge calls for appreciable time and assets from knowledge scientists, hindering widespread adoption.
Generative AI utilizing massive pre-trained basis fashions (FMs) resembling Claude can quickly generate quite a lot of content material from conversational textual content to pc code based mostly on easy textual content prompts, generally known as zero-shot prompting. This eliminates the necessity for knowledge scientists to manually develop particular ML fashions for every use case, and subsequently democratizes AI entry, benefitting even small producers. Employees acquire productiveness by AI-generated insights, engineers can proactively detect anomalies, provide chain managers optimize inventories, and plant management makes knowledgeable, data-driven selections.
Nonetheless, standalone FMs face limitations in dealing with advanced industrial knowledge with context measurement constraints (usually less than 200,000 tokens), which poses challenges. To deal with this, you need to use the FM’s potential to generate code in response to pure language queries (NLQs). Brokers like PandasAI come into play, working this code on high-resolution time collection knowledge and dealing with errors utilizing FMs. PandasAI is a Python library that provides generative AI capabilities to pandas, the favored knowledge evaluation and manipulation instrument.
Nevertheless, advanced NLQs, resembling time collection knowledge processing, multi-level aggregation, and pivot or joint desk operations, could yield inconsistent Python script accuracy with a zero-shot immediate.
To reinforce code era accuracy, we suggest dynamically developing multi-shot prompts for NLQs. Multi-shot prompting offers further context to the FM by displaying it a number of examples of desired outputs for comparable prompts, boosting accuracy and consistency. On this put up, multi-shot prompts are retrieved from an embedding containing profitable Python code run on the same knowledge sort (for instance, high-resolution time collection knowledge from Web of Issues gadgets). The dynamically constructed multi-shot immediate offers essentially the most related context to the FM, and boosts the FM’s functionality in superior math calculation, time collection knowledge processing, and knowledge acronym understanding. This improved response facilitates enterprise staff and operational groups in partaking with knowledge, deriving insights with out requiring intensive knowledge science abilities.
Past time collection knowledge evaluation, FMs show useful in varied industrial functions. Upkeep groups assess asset well being, seize pictures for Amazon Rekognition-based performance summaries, and anomaly root trigger evaluation utilizing clever searches with Retrieval Augmented Generation (RAG). To simplify these workflows, AWS has launched Amazon Bedrock, enabling you to construct and scale generative AI functions with state-of-the-art pre-trained FMs like Claude v2. With Knowledge Bases for Amazon Bedrock, you may simplify the RAG growth course of to offer extra correct anomaly root trigger evaluation for plant staff. Our put up showcases an clever assistant for industrial use circumstances powered by Amazon Bedrock, addressing NLQ challenges, producing half summaries from pictures, and enhancing FM responses for tools analysis by the RAG method.
Resolution overview
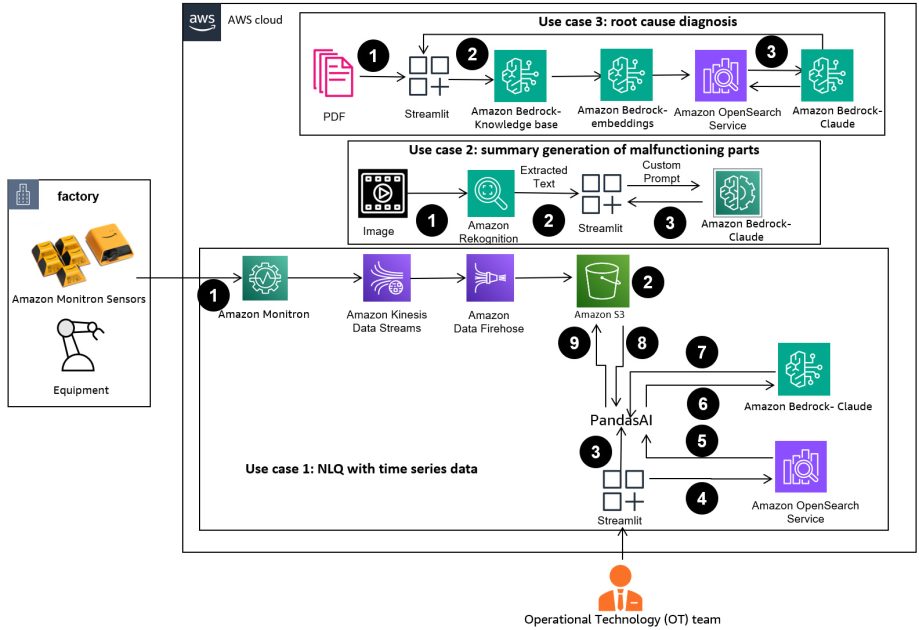
The next diagram illustrates the answer structure.

The workflow contains three distinct use circumstances:
Use case 1: NLQ with time collection knowledge
The workflow for NLQ with time collection knowledge consists of the next steps:
- We use a situation monitoring system with ML capabilities for anomaly detection, resembling Amazon Monitron, to watch industrial tools well being. Amazon Monitron is ready to detect potential tools failures from the tools’s vibration and temperature measurements.
- We gather time collection knowledge by processing Amazon Monitron knowledge by Amazon Kinesis Data Streams and Amazon Data Firehose, changing it right into a tabular CSV format and saving it in an Amazon Simple Storage Service (Amazon S3) bucket.
- The tip-user can begin chatting with their time collection knowledge in Amazon S3 by sending a pure language question to the Streamlit app.
- The Streamlit app forwards person queries to the Amazon Bedrock Titan text embedding model to embed this question, and performs a similarity search inside an Amazon OpenSearch Service index, which accommodates prior NLQs and instance codes.
- After the similarity search, the highest comparable examples, together with NLQ questions, knowledge schema, and Python codes, are inserted in a customized immediate.
- PandasAI sends this tradition immediate to the Amazon Bedrock Claude v2 mannequin.
- The app makes use of the PandasAI agent to work together with the Amazon Bedrock Claude v2 mannequin, producing Python code for Amazon Monitron knowledge evaluation and NLQ responses.
- After the Amazon Bedrock Claude v2 mannequin returns the Python code, PandasAI runs the Python question on the Amazon Monitron knowledge uploaded from the app, amassing code outputs and addressing any needed retries for failed runs.
- The Streamlit app collects the response by way of PandasAI, and offers the output to customers. If the output is passable, the person can mark it as useful, saving the NLQ and Claude-generated Python code in OpenSearch Service.
Use case 2: Abstract era of malfunctioning components
Our abstract era use case consists of the next steps:
- After the person is aware of which industrial asset reveals anomalous conduct, they will add pictures of the malfunctioning half to establish if there’s something bodily unsuitable with this half in accordance with its technical specification and operation situation.
- The person can use the Amazon Recognition DetectText API to extract textual content knowledge from these pictures.
- The extracted textual content knowledge is included within the immediate for the Amazon Bedrock Claude v2 mannequin, enabling the mannequin to generate a 200-word abstract of the malfunctioning half. The person can use this data to carry out additional inspection of the half.
Use case 3: Root trigger analysis
Our root trigger analysis use case consists of the next steps:
- The person obtains enterprise knowledge in varied doc codecs (PDF, TXT, and so forth) associated with malfunctioning belongings, and uploads them to an S3 bucket.
- A data base of those information is generated in Amazon Bedrock with a Titan textual content embeddings mannequin and a default OpenSearch Service vector retailer.
- The person poses questions associated to the foundation trigger analysis for malfunctioning tools. Solutions are generated by the Amazon Bedrock data base with a RAG method.
Conditions
To comply with together with this put up, it is best to meet the next conditions:
Deploy the answer infrastructure
To arrange your answer assets, full the next steps:
- Deploy the AWS CloudFormation template opensearchsagemaker.yml, which creates an OpenSearch Service assortment and index, Amazon SageMaker pocket book occasion, and S3 bucket. You may title this AWS CloudFormation stack as:
genai-sagemaker. - Open the SageMaker pocket book occasion in JupyterLab. You can find the next GitHub repo already downloaded on this occasion: unlocking-the-potential-of-generative-ai-in-industrial-operations.
- Run the pocket book from the next listing on this repository: unlocking-the-potential-of-generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. This pocket book will load the OpenSearch Service index utilizing the SageMaker pocket book to retailer key-value pairs from the existing 23 NLQ examples.
- Add paperwork from the information folder assetpartdoc within the GitHub repository to the S3 bucket listed within the CloudFormation stack outputs.

Subsequent, you create the data base for the paperwork in Amazon S3.
- On the Amazon Bedrock console, select Data base within the navigation pane.
- Select Create data base.
- For Data base title, enter a reputation.
- For Runtime position, choose Create and use a brand new service position.

- For Information supply title, enter the title of your knowledge supply.
- For S3 URI, enter the S3 path of the bucket the place you uploaded the foundation trigger paperwork.
- Select Subsequent.
 The Titan embeddings mannequin is robotically chosen.
The Titan embeddings mannequin is robotically chosen. - Choose Fast create a brand new vector retailer.

- Evaluate your settings and create the data base by selecting Create data base.
- After the data base is efficiently created, select Sync to sync the S3 bucket with the data base.

- After you arrange the data base, you may check the RAG method for root trigger analysis by asking questions like “My actuator travels sluggish, what could be the difficulty?”

The following step is to deploy the app with the required library packages on both your PC or an EC2 occasion (Ubuntu Server 22.04 LTS).
- Set up your AWS credentials with the AWS CLI in your native PC. For simplicity, you need to use the identical admin position you used to deploy the CloudFormation stack. In the event you’re utilizing Amazon EC2, attach a suitable IAM role to the instance.
- Clone GitHub repo:
- Change the listing to
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcand run thesetup.shscript on this folder to put in the required packages, together with LangChain and PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Run the Streamlit app with the next command:
supply monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Present the OpenSearch Service assortment ARN you created in Amazon Bedrock from the earlier step.
Chat along with your asset well being assistant
After you full the end-to-end deployment, you may entry the app by way of localhost on port 8501, which opens a browser window with the online interface. In the event you deployed the app on an EC2 occasion, allow port 8501 access via the security group inbound rule. You may navigate to totally different tabs for varied use circumstances.
Discover use case 1
To discover the primary use case, select Information Perception and Chart. Start by importing your time collection knowledge. In the event you don’t have an present time collection knowledge file to make use of, you may add the next sample CSV file with nameless Amazon Monitron mission knowledge. If you have already got an Amazon Monitron mission, check with Generate actionable insights for predictive maintenance management with Amazon Monitron and Amazon Kinesis to stream your Amazon Monitron knowledge to Amazon S3 and use your knowledge with this utility.
When the add is full, enter a question to provoke a dialog along with your knowledge. The left sidebar provides a variety of instance questions on your comfort. The next screenshots illustrate the response and Python code generated by the FM when inputting a query resembling “Inform me the distinctive variety of sensors for every web site proven as Warning or Alarm respectively?” (a hard-level query) or “For sensors proven temperature sign as NOT Wholesome, are you able to calculate the time length in days for every sensor proven irregular vibration sign?” (a challenge-level query). The app will reply your query, and also will present the Python script of knowledge evaluation it carried out to generate such outcomes.


In the event you’re happy with the reply, you may mark it as Useful, saving the NLQ and Claude-generated Python code to an OpenSearch Service index.

Discover use case 2
To discover the second use case, select the Captured Picture Abstract tab within the Streamlit app. You may add a picture of your industrial asset, and the applying will generate a 200-word abstract of its technical specification and operation situation based mostly on the picture data. The next screenshot reveals the abstract generated from a picture of a belt motor drive. To check this function, should you lack an appropriate picture, you need to use the next example image.

Hydraulic elevator motor label” by Clarence Risher is licensed beneath CC BY-SA 2.0.

Discover use case 3
To discover the third use case, select the Root trigger analysis tab. Enter a question associated to your damaged industrial asset, resembling, “My actuator travels sluggish, what could be the difficulty?” As depicted within the following screenshot, the applying delivers a response with the supply doc excerpt used to generate the reply.

Use case 1: Design particulars
On this part, we talk about the design particulars of the applying workflow for the primary use case.
Customized immediate constructing
The person’s pure language question comes with totally different tough ranges: straightforward, arduous, and problem.
Simple questions could embrace the next requests:
- Choose distinctive values
- Rely complete numbers
- Type values
For these questions, PandasAI can instantly work together with the FM to generate Python scripts for processing.
Exhausting questions require fundamental aggregation operation or time collection evaluation, resembling the next:
- Choose worth first and group outcomes hierarchically
- Carry out statistics after preliminary report choice
- Timestamp rely (for instance, min and max)
For arduous questions, a immediate template with detailed step-by-step directions assists FMs in offering correct responses.
Problem-level questions want superior math calculation and time collection processing, resembling the next:
- Calculate anomaly length for every sensor
- Calculate anomaly sensors for web site on a month-to-month foundation
- Examine sensor readings beneath regular operation and irregular situations
For these questions, you need to use multi-shots in a customized immediate to reinforce response accuracy. Such multi-shots present examples of superior time collection processing and math calculation, and can present context for the FM to carry out related inference on comparable evaluation. Dynamically inserting essentially the most related examples from an NLQ query financial institution into the immediate could be a problem. One answer is to assemble embeddings from present NLQ query samples and save these embeddings in a vector retailer like OpenSearch Service. When a query is shipped to the Streamlit app, the query will probably be vectorized by BedrockEmbeddings. The highest N most-relevant embeddings to that query are retrieved utilizing opensearch_vector_search.similarity_search and inserted into the immediate template as a multi-shot immediate.
The next diagram illustrates this workflow.

The embedding layer is constructed utilizing three key instruments:
- Embeddings mannequin – We use Amazon Titan Embeddings obtainable by Amazon Bedrock (amazon.titan-embed-text-v1) to generate numerical representations of textual paperwork.
- Vector retailer – For our vector retailer, we use OpenSearch Service by way of the LangChain framework, streamlining the storage of embeddings generated from NLQ examples on this pocket book.
- Index – The OpenSearch Service index performs a pivotal position in evaluating enter embeddings to doc embeddings and facilitating the retrieval of related paperwork. As a result of the Python instance codes have been saved as a JSON file, they have been listed in OpenSearch Service as vectors by way of an OpenSearchVevtorSearch.fromtexts API name.
Steady assortment of human-audited examples by way of Streamlit
On the outset of app growth, we started with solely 23 saved examples within the OpenSearch Service index as embeddings. Because the app goes dwell within the subject, customers begin inputting their NLQs by way of the app. Nevertheless, as a result of restricted examples obtainable within the template, some NLQs could not discover comparable prompts. To repeatedly enrich these embeddings and supply extra related person prompts, you need to use the Streamlit app for gathering human-audited examples.
Throughout the app, the next perform serves this goal. When end-users discover the output useful and choose Useful, the applying follows these steps:
- Use the callback technique from PandasAI to gather the Python script.
- Reformat the Python script, enter query, and CSV metadata right into a string.
- Verify whether or not this NLQ instance already exists within the present OpenSearch Service index utilizing opensearch_vector_search.similarity_search_with_score.
- If there’s no comparable instance, this NLQ is added to the OpenSearch Service index utilizing opensearch_vector_search.add_texts.
Within the occasion {that a} person selects Not Useful, no motion is taken. This iterative course of makes certain that the system regularly improves by incorporating user-contributed examples.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######construct the input_question and generated code the identical format as present opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str=""
for key,worth in reconstructed_json.objects():
json_str += key + ':' + worth
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
outcomes = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), okay=kexamples) # our search question # return 3 most related docs
if (dumpd(outcomes[0][1])<similarity_threshold): ###No comparable embedding exist, then add textual content to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "The same embedding is exist already, no motion."
return response
By incorporating human auditing, the amount of examples in OpenSearch Service obtainable for immediate embedding grows because the app features utilization. This expanded embedding dataset leads to enhanced search accuracy over time. Particularly, for difficult NLQs, the FM’s response accuracy reaches roughly 90% when dynamically inserting comparable examples to assemble customized prompts for every NLQ query. This represents a notable 28% enhance in comparison with situations with out multi-shot prompts.
Use case 2: Design particulars
On the Streamlit app’s Captured Picture Abstract tab, you may instantly add a picture file. This initiates the Amazon Rekognition API (detect_text API), extracting textual content from the picture label detailing machine specs. Subsequently, the extracted textual content knowledge is shipped to the Amazon Bedrock Claude mannequin because the context of a immediate, leading to a 200-word abstract.
From a person expertise perspective, enabling streaming performance for a textual content summarization activity is paramount, permitting customers to learn the FM-generated abstract in smaller chunks relatively than ready for your entire output. Amazon Bedrock facilitates streaming by way of its API (bedrock_runtime.invoke_model_with_response_stream).
Use case 3: Design particulars
On this situation, we’ve developed a chatbot utility centered on root trigger evaluation, using the RAG method. This chatbot attracts from a number of paperwork associated to bearing tools to facilitate root trigger evaluation. This RAG-based root trigger evaluation chatbot makes use of data bases for producing vector textual content representations, or embeddings. Data Bases for Amazon Bedrock is a completely managed functionality that helps you implement your entire RAG workflow, from ingestion to retrieval and immediate augmentation, with out having to construct customized integrations to knowledge sources or handle knowledge flows and RAG implementation particulars.
While you’re happy with the data base response from Amazon Bedrock, you may combine the foundation trigger response from the data base to the Streamlit app.
Clear up
To avoid wasting prices, delete the assets you created on this put up:
- Delete the data base from Amazon Bedrock.
- Delete the OpenSearch Service index.
- Delete the genai-sagemaker CloudFormation stack.
- Cease the EC2 occasion should you used an EC2 occasion to run the Streamlit app.
Conclusion
Generative AI functions have already reworked varied enterprise processes, enhancing employee productiveness and talent units. Nevertheless, the constraints of FMs in dealing with time collection knowledge evaluation have hindered their full utilization by industrial shoppers. This constraint has impeded the applying of generative AI to the predominant knowledge sort processed day by day.
On this put up, we launched a generative AI Utility answer designed to alleviate this problem for industrial customers. This utility makes use of an open supply agent, PandasAI, to strengthen an FM’s time collection evaluation functionality. Moderately than sending time collection knowledge on to FMs, the app employs PandasAI to generate Python code for the evaluation of unstructured time collection knowledge. To reinforce the accuracy of Python code era, a customized immediate era workflow with human auditing has been carried out.
Empowered with insights into their asset well being, industrial staff can absolutely harness the potential of generative AI throughout varied use circumstances, together with root trigger analysis and half alternative planning. With Data Bases for Amazon Bedrock, the RAG answer is simple for builders to construct and handle.
The trajectory of enterprise knowledge administration and operations is unmistakably transferring in the direction of deeper integration with generative AI for complete insights into operational well being. This shift, spearheaded by Amazon Bedrock, is considerably amplified by the rising robustness and potential of LLMs like Amazon Bedrock Claude 3 to additional elevate options. To study extra, go to seek the advice of the Amazon Bedrock documentation, and get hands-on with the Amazon Bedrock workshop.
In regards to the authors
 Julia Hu is a Sr. AI/ML Options Architect at Amazon Internet Companies. She is specialised in Generative AI, Utilized Information Science and IoT structure. At the moment she is a part of the Amazon Q workforce, and an lively member/mentor in Machine Studying Technical Subject Neighborhood. She works with prospects, starting from start-ups to enterprises, to develop AWSome generative AI options. She is especially keen about leveraging Giant Language Fashions for superior knowledge analytics and exploring sensible functions that handle real-world challenges.
Julia Hu is a Sr. AI/ML Options Architect at Amazon Internet Companies. She is specialised in Generative AI, Utilized Information Science and IoT structure. At the moment she is a part of the Amazon Q workforce, and an lively member/mentor in Machine Studying Technical Subject Neighborhood. She works with prospects, starting from start-ups to enterprises, to develop AWSome generative AI options. She is especially keen about leveraging Giant Language Fashions for superior knowledge analytics and exploring sensible functions that handle real-world challenges.
 Sudeesh Sasidharan is a Senior Options Architect at AWS, inside the Power workforce. Sudeesh loves experimenting with new applied sciences and constructing progressive options that remedy advanced enterprise challenges. When he isn’t designing options or tinkering with the newest applied sciences, you will discover him on the tennis courtroom engaged on his backhand.
Sudeesh Sasidharan is a Senior Options Architect at AWS, inside the Power workforce. Sudeesh loves experimenting with new applied sciences and constructing progressive options that remedy advanced enterprise challenges. When he isn’t designing options or tinkering with the newest applied sciences, you will discover him on the tennis courtroom engaged on his backhand.
 Neil Desai is a expertise govt with over 20 years of expertise in synthetic intelligence (AI), knowledge science, software program engineering, and enterprise structure. At AWS, he leads a workforce of Worldwide AI companies specialist options architects who assist prospects construct progressive Generative AI-powered options, share finest practices with prospects, and drive product roadmap. In his earlier roles at Vestas, Honeywell, and Quest Diagnostics, Neil has held management roles in creating and launching progressive services and products which have helped corporations enhance their operations, scale back prices, and enhance income. He’s keen about utilizing expertise to unravel real-world issues and is a strategic thinker with a confirmed monitor report of success.
Neil Desai is a expertise govt with over 20 years of expertise in synthetic intelligence (AI), knowledge science, software program engineering, and enterprise structure. At AWS, he leads a workforce of Worldwide AI companies specialist options architects who assist prospects construct progressive Generative AI-powered options, share finest practices with prospects, and drive product roadmap. In his earlier roles at Vestas, Honeywell, and Quest Diagnostics, Neil has held management roles in creating and launching progressive services and products which have helped corporations enhance their operations, scale back prices, and enhance income. He’s keen about utilizing expertise to unravel real-world issues and is a strategic thinker with a confirmed monitor report of success.





