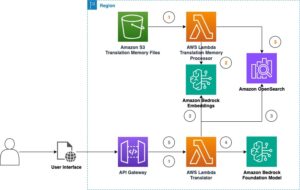
Use RAG for drug discovery with Information Bases for Amazon Bedrock

Amazon Bedrock supplies a broad vary of fashions from Amazon and third-party suppliers, together with Anthropic, AI21, Meta, Cohere, and Stability AI, and covers a variety of use circumstances, together with textual content and picture era, embedding, chat, high-level brokers with reasoning and orchestration, and extra. Knowledge Bases for Amazon Bedrock means that you can construct performant and customised Retrieval Augmented Technology (RAG) functions on prime of AWS and third-party vector shops utilizing each AWS and third-party fashions. Information Bases for Amazon Bedrock automates synchronization of your information along with your vector retailer, together with diffing the information when it’s up to date, doc loading, and chunking, in addition to semantic embedding. It means that you can seamlessly customise your RAG prompts and retrieval methods—we offer the supply attribution, and we deal with reminiscence administration routinely. Information Bases is totally serverless, so that you don’t must handle any infrastructure, and when utilizing Information Bases, you’re solely charged for the fashions, vector databases and storage you utilize.
RAG is a well-liked approach that mixes using personal information with massive language fashions (LLMs). RAG begins with an preliminary step to retrieve related paperwork from a knowledge retailer (mostly a vector index) based mostly on the consumer’s question. It then employs a language mannequin to generate a response by contemplating each the retrieved paperwork and the unique question.
On this put up, we display the best way to construct a RAG workflow utilizing Information Bases for Amazon Bedrock for a drug discovery use case.
Overview of Information Bases for Amazon Bedrock
Information Bases for Amazon Bedrock helps a broad vary of widespread file varieties, together with .txt, .docx, .pdf, .csv, and extra. To allow efficient retrieval from personal information, a standard follow is to first cut up these paperwork into manageable chunks. Information Bases has carried out a default chunking technique that works nicely typically to mean you can get began sooner. If you would like extra management, Information Bases allows you to management the chunking technique by way of a set of preconfigured choices. You’ll be able to management the utmost token measurement and the quantity of overlap to be created throughout chunks to supply coherent context to the embedding. Information Bases for Amazon Bedrock manages the method of synchronizing information out of your Amazon Simple Storage Service (Amazon S3) bucket, splits it into smaller chunks, generates vector embeddings, and shops the embeddings in a vector index. This course of comes with clever diffing, throughput, and failure administration.
At runtime, an embedding mannequin is used to transform the consumer’s question to a vector. The vector index is then queried to seek out paperwork much like the consumer’s question by evaluating doc vectors to the consumer question vector. Within the ultimate step, semantically related paperwork retrieved from the vector index are added as context for the unique consumer question. When producing a response for the consumer, the semantically related paperwork are prompted within the textual content mannequin, along with supply attribution for traceability.
Information Bases for Amazon Bedrock helps a number of vector databases, together with Amazon OpenSearch Serverless, Amazon Aurora, Pinecone, and Redis Enterprise Cloud. The Retrieve and RetrieveAndGenerate APIs enable your functions to straight question the index utilizing a unified and customary syntax with out having to study separate APIs for every completely different vector database, decreasing the necessity to write customized index queries towards your vector retailer. The Retrieve API takes the incoming question, converts it into an embedding vector, and queries the backend retailer utilizing the algorithms configured on the vector database degree; the RetrieveAndGenerate API makes use of a user-configured LLM supplied by Amazon Bedrock and generates the ultimate reply in pure language. The native traceability help informs the requesting utility in regards to the sources used to reply a query. For enterprise implementations, Information Bases helps AWS Key Management Service (AWS KMS) encryption, AWS CloudTrail integration, and extra.
Within the following sections, we display the best way to construct a RAG workflow utilizing Information Bases for Amazon Bedrock, backed by the OpenSearch Serverless vector engine, to research an unstructured scientific trial dataset for a drug discovery use case. This information is data wealthy however could be vastly heterogenous. Correct dealing with of specialised terminology and ideas in several codecs is important to detect insights and guarantee analytical integrity. With Information Bases for Amazon Bedrock, you possibly can entry detailed data by way of easy, pure queries.
Construct a information base for Amazon Bedrock
On this part, we demo the method of making a information base for Amazon Bedrock through the console. Full the next steps:
- On the Amazon Bedrock console, below Orchestration within the navigation pane, select Information base.
- Select Create information base.

- Within the Information base particulars part, enter a reputation and elective description.
- Within the IAM permissions part, choose Create and use a brand new service position.
- For Service title position, enter a reputation to your position, which should begin with
AmazonBedrockExecutionRoleForKnowledgeBase_. - Select Subsequent.

- Within the Information supply part, enter a reputation to your information supply and the S3 URI the place the dataset sits. Information Bases helps the next file codecs:
- Plain textual content (.txt)
- Markdown (.md)
- HyperText Markup Language (.html)
- Microsoft Phrase doc (.doc/.docx)
- Comma-separated values (.csv)
- Microsoft Excel spreadsheet (.xls/.xlsx)
- Transportable Doc Format (.pdf)
- Below Extra settings¸ select your most well-liked chunking technique (for this put up, we select Fastened measurement chunking) and specify the chunk measurement and overlay in proportion. Alternatively, you should use the default settings.
- Select Subsequent.

- Within the Embeddings mannequin part, select the Titan Embeddings mannequin from Amazon Bedrock.
- Within the Vector database part, choose Fast create a brand new vector retailer, which manages the method of establishing a vector retailer.
- Select Subsequent.

- Evaluate the settings and select Create information base.

- Look forward to the information base creation to finish and make sure its standing is Prepared.
- Within the Information supply part, or on the banner on the prime of the web page or the popup within the take a look at window, select Sync to set off the method of loading information from the S3 bucket, splitting it into chunks of the scale you specified, producing vector embeddings utilizing the chosen textual content embedding mannequin, and storing them within the vector retailer managed by Information Bases for Amazon Bedrock.

The sync operate helps ingesting, updating, and deleting the paperwork from the vector index based mostly on modifications to paperwork in Amazon S3. You can too use the StartIngestionJob API to set off the sync through the AWS SDK.
When the sync is full, the Sync historical past reveals standing Accomplished.

Question the information base
On this part, we display the best way to entry detailed data within the information base by way of simple and pure queries. We use an unstructured artificial dataset consisting of PDF information, the web page variety of every starting from 10–100 pages, simulating a scientific trial plan of a proposed new medication together with statistical evaluation strategies and participant consent types. We use the Information Bases for Amazon Bedrock retrieve_and_generate and retrieve APIs with Amazon Bedrock LangChain integration.
Earlier than you possibly can write scripts that use the Amazon Bedrock API, you’ll want to put in the suitable model of the AWS SDK in your atmosphere. For Python scripts, this would be the AWS SDK for Python (Boto3):
Moreover, allow entry to the Amazon Titan Embeddings mannequin and Anthropic Claude v2 or v1. For extra data, consult with Model access.
Generate questions utilizing Amazon Bedrock
We will use Anthropic Claude 2.1 for Amazon Bedrock to suggest a listing of inquiries to ask on the scientific trial dataset:
Use the Amazon Bedrock RetrieveAndGenerate API
For a totally managed RAG expertise, you should use the native Information Bases for Amazon Bedrock RetrieveAndGenerate API to acquire the solutions straight:
The cited data supply could be obtained through the next code (with a number of the output redacted for brevity):
By passing the session ID of the RetrieveAndGenerate API, you possibly can protect the dialog context and ask follow-up questions. For instance, with out the context, should you ask for extra particulars from the earlier reply, it might not have the ability to reply accurately:
However by passing the session ID, the RAG pipeline is ready to determine the corresponding context and return related solutions:
The next desk reveals the retrieved solutions to all of the corresponding questions.
| Query | Reply |
| What’s the function of the examine? Be sure you perceive the targets of the analysis and what the examine procedures will entail. | The aim of the examine is to check whether or not lithium is efficient at stopping repeated suicidal self-directed violence in sufferers with melancholy or bipolar dysfunction. |
| What are the dangers and potential advantages? The shape ought to clarify all foreseeable dangers, unwanted side effects, or discomforts you would possibly expertise from collaborating. | The potential dangers or discomforts embrace: the interview questions inflicting discomfort, unwanted side effects from the lithium remedy reminiscent of nausea, free stools, thirst, urination modifications, shakiness, complications, sweating, fatigue, decreased focus, pores and skin rash, thyroid modifications, worsening pimples/psoriasis, lithium toxicity, and dangers if the remedy is all of a sudden stopped. The potential advantages are that the checks might result in new data to assist the participant, and lithium might assist forestall repeated suicidal self-directed violence for these with melancholy or bipolar dysfunction. |
| What’s going to participation contain? Get particulars on what checks, medicines, life-style modifications, or procedures you’ll undergo, how a lot time it should take, and the way lengthy the examine will final. | Participation will contain finishing an interview and questionnaires masking considering, behaviors, psychological well being therapy, medicines, alcohol and drug use, house and social helps, and understanding of the analysis examine. This takes about two hours and could be accomplished in a number of classes, in particular person and by cellphone. If eligible for the total examine, there might be about 20 examine visits over one 12 months. This can contain taking examine remedy, having very important indicators checked, finishing questionnaires, reviewing unwanted side effects, and persevering with regular medical and psychological well being care. |
| Are there any prices or funds? Ask if you may be answerable for any prices associated to the examine or receives a commission for collaborating. | Sure, there are prices and funds mentioned within the search outcomes. You’ll not be charged for any remedies or procedures which might be a part of the examine. Nevertheless, you’ll nonetheless need to pay any typical VA co-payments for care and medicines not associated to the examine. You’ll not be paid for participation, however the examine will reimburse bills associated to participation like transportation, parking, and many others. Reimbursement quantities and course of are supplied. |
| How will my privateness be protected? The shape ought to clarify how your private well being data might be stored confidential earlier than, throughout, and after the trial. | Your privateness might be protected by conducting interviews in personal, retaining written notes in locked information and workplaces, storing digital data in encrypted and password protected information, and acquiring a Confidentiality Certificates from the Division of Well being and Human Companies to stop disclosing data that identifies you. Info that identifies it’s possible you’ll be shared with docs answerable for your care or for audits and evaluations by authorities businesses, however talks and papers in regards to the examine won’t determine you. |
Question utilizing the Amazon Bedrock Retrieve API
To customise your RAG workflow, you should use the Retrieve API to fetch the related chunks based mostly in your question and go it to any LLM supplied by Amazon Bedrock. To make use of the Retrieve API, outline it as follows:
Retrieve the corresponding context (with a number of the output redacted for brevity):
Extract the context for the immediate template:
Import the Python modules and arrange the in-context query answering immediate template, then generate the ultimate reply:
Question utilizing Amazon Bedrock LangChain integration
To create an end-to-end personalized Q&A utility, Information Bases for Amazon Bedrock supplies integration with LangChain. To arrange the LangChain retriever, present the information base ID and specify the variety of outcomes to return from the question:
Now arrange LangChain RetrievalQA and generate solutions from the information base:
This can generate corresponding solutions much like those listed within the earlier desk.
Clear up
Be certain that to delete the next sources to keep away from incurring extra fees:
Conclusion
Amazon Bedrock supplies a broad set of deeply built-in companies to energy RAG functions of all scales, making it simple to get began with analyzing your organization information. Information Bases for Amazon Bedrock integrates with Amazon Bedrock basis fashions to construct scalable doc embedding pipelines and doc retrieval companies to energy a variety of inner and customer-facing functions. We’re excited in regards to the future forward, and your suggestions will play an important position in guiding the progress of this product. To study extra in regards to the capabilities of Amazon Bedrock and information bases, consult with Knowledge base for Amazon Bedrock.
In regards to the Authors
 Mark Roy is a Principal Machine Studying Architect for AWS, serving to prospects design and construct AI/ML options. Mark’s work covers a variety of ML use circumstances, with a main curiosity in laptop imaginative and prescient, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary companies, media and leisure, healthcare, utilities, and manufacturing. Mark holds six AWS Certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Mark was an architect, developer, and expertise chief for over 25 years, together with 19 years in monetary companies.
Mark Roy is a Principal Machine Studying Architect for AWS, serving to prospects design and construct AI/ML options. Mark’s work covers a variety of ML use circumstances, with a main curiosity in laptop imaginative and prescient, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary companies, media and leisure, healthcare, utilities, and manufacturing. Mark holds six AWS Certifications, together with the ML Specialty Certification. Previous to becoming a member of AWS, Mark was an architect, developer, and expertise chief for over 25 years, together with 19 years in monetary companies.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, writer of the guide – Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Ladies in Manufacturing Schooling Basis Board. She leads machine studying (ML) initiatives in varied domains reminiscent of laptop imaginative and prescient, pure language processing and generative AI. She helps prospects to construct, prepare and deploy massive machine studying fashions at scale. She speaks in inner and exterior conferences such re:Invent, Ladies in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for lengthy runs alongside the seashore.
Mani Khanuja is a Tech Lead – Generative AI Specialists, writer of the guide – Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Ladies in Manufacturing Schooling Basis Board. She leads machine studying (ML) initiatives in varied domains reminiscent of laptop imaginative and prescient, pure language processing and generative AI. She helps prospects to construct, prepare and deploy massive machine studying fashions at scale. She speaks in inner and exterior conferences such re:Invent, Ladies in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for lengthy runs alongside the seashore.
 Dr. Baichuan Solar, at present serving as a Sr. AI/ML Resolution Architect at AWS, focuses on generative AI and applies his information in information science and machine studying to supply sensible, cloud-based enterprise options. With expertise in administration consulting and AI resolution structure, he addresses a variety of complicated challenges, together with robotics laptop imaginative and prescient, time sequence forecasting, and predictive upkeep, amongst others. His work is grounded in a strong background of undertaking administration, software program R&D, and educational pursuits. Outdoors of labor, Dr. Solar enjoys the stability of touring and spending time with household and buddies.
Dr. Baichuan Solar, at present serving as a Sr. AI/ML Resolution Architect at AWS, focuses on generative AI and applies his information in information science and machine studying to supply sensible, cloud-based enterprise options. With expertise in administration consulting and AI resolution structure, he addresses a variety of complicated challenges, together with robotics laptop imaginative and prescient, time sequence forecasting, and predictive upkeep, amongst others. His work is grounded in a strong background of undertaking administration, software program R&D, and educational pursuits. Outdoors of labor, Dr. Solar enjoys the stability of touring and spending time with household and buddies.
 Derrick Choo is a Senior Options Architect at AWS targeted on accelerating buyer’s journey to the cloud and remodeling their enterprise by way of the adoption of cloud-based options. His experience is in full stack utility and machine studying improvement. He helps prospects design and construct end-to-end options masking frontend consumer interfaces, IoT functions, API and information integrations and machine studying fashions. In his free time, he enjoys spending time together with his household and experimenting with images and videography.
Derrick Choo is a Senior Options Architect at AWS targeted on accelerating buyer’s journey to the cloud and remodeling their enterprise by way of the adoption of cloud-based options. His experience is in full stack utility and machine studying improvement. He helps prospects design and construct end-to-end options masking frontend consumer interfaces, IoT functions, API and information integrations and machine studying fashions. In his free time, he enjoys spending time together with his household and experimenting with images and videography.
 Frank Winkler is a Senior Options Architect and Generative AI Specialist at AWS based mostly in Singapore, targeted in Machine Studying and Generative AI. He works with international digital native corporations to architect scalable, safe, and cost-effective services and products on AWS. In his free time, he spends time together with his son and daughter, and travels to benefit from the waves throughout ASEAN.
Frank Winkler is a Senior Options Architect and Generative AI Specialist at AWS based mostly in Singapore, targeted in Machine Studying and Generative AI. He works with international digital native corporations to architect scalable, safe, and cost-effective services and products on AWS. In his free time, he spends time together with his son and daughter, and travels to benefit from the waves throughout ASEAN.
 Nihir Chadderwala is a Sr. AI/ML Options Architect within the International Healthcare and Life Sciences group. His experience is in constructing Massive Information and AI-powered options to buyer issues particularly in biomedical, life sciences and healthcare area. He’s additionally excited in regards to the intersection of quantum data science and AI and enjoys studying and contributing to this area. In his spare time, he enjoys enjoying tennis, touring, and studying about cosmology.
Nihir Chadderwala is a Sr. AI/ML Options Architect within the International Healthcare and Life Sciences group. His experience is in constructing Massive Information and AI-powered options to buyer issues particularly in biomedical, life sciences and healthcare area. He’s additionally excited in regards to the intersection of quantum data science and AI and enjoys studying and contributing to this area. In his spare time, he enjoys enjoying tennis, touring, and studying about cosmology.