Strategies and approaches for monitoring massive language fashions on AWS

Massive Language Fashions (LLMs) have revolutionized the sphere of pure language processing (NLP), enhancing duties akin to language translation, textual content summarization, and sentiment evaluation. Nevertheless, as these fashions proceed to develop in measurement and complexity, monitoring their efficiency and conduct has turn out to be more and more difficult.
Monitoring the efficiency and conduct of LLMs is a important activity for guaranteeing their security and effectiveness. Our proposed structure supplies a scalable and customizable resolution for on-line LLM monitoring, enabling groups to tailor your monitoring resolution to your particular use circumstances and necessities. Through the use of AWS companies, our structure supplies real-time visibility into LLM conduct and allows groups to shortly determine and tackle any points or anomalies.
On this put up, we show just a few metrics for on-line LLM monitoring and their respective structure for scale utilizing AWS companies akin to Amazon CloudWatch and AWS Lambda. This presents a customizable resolution past what is feasible with model evaluation jobs with Amazon Bedrock.
Overview of resolution
The very first thing to think about is that totally different metrics require totally different computation concerns. A modular structure, the place every module can consumption mannequin inference information and produce its personal metrics, is critical.
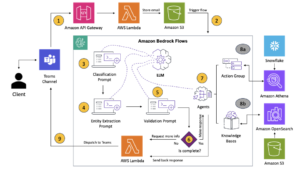
We recommend that every module take incoming inference requests to the LLM, passing immediate and completion (response) pairs to metric compute modules. Every module is liable for computing its personal metrics with respect to the enter immediate and completion (response). These metrics are handed to CloudWatch, which might combination them and work with CloudWatch alarms to ship notifications on particular situations. The next diagram illustrates this structure.

Fig 1: Metric compute module – resolution overview
The workflow consists of the next steps:
- A person makes a request to Amazon Bedrock as a part of an utility or person interface.
- Amazon Bedrock saves the request and completion (response) in Amazon Simple Storage Service (Amazon S3) because the per configuration of invocation logging.
- The file saved on Amazon S3 creates an occasion that triggers a Lambda perform. The perform invokes the modules.
- The modules put up their respective metrics to CloudWatch metrics.
- Alarms can notify the event staff of sudden metric values.
The second factor to think about when implementing LLM monitoring is selecting the best metrics to trace. Though there are various potential metrics that you should use to observe LLM efficiency, we clarify a number of the broadest ones on this put up.
Within the following sections, we spotlight just a few of the related module metrics and their respective metric compute module structure.
Semantic similarity between immediate and completion (response)
When operating LLMs, you’ll be able to intercept the immediate and completion (response) for every request and rework them into embeddings utilizing an embedding mannequin. Embeddings are high-dimensional vectors that signify the semantic that means of the textual content. Amazon Titan supplies such fashions via Titan Embeddings. By taking a distance akin to cosine between these two vectors, you’ll be able to quantify how semantically comparable the immediate and completion (response) are. You should use SciPy or scikit-learn to compute the cosine distance between vectors. The next diagram illustrates the structure of this metric compute module.

Fig 2: Metric compute module – semantic similarity
This workflow consists of the next key steps:
- A Lambda perform receives a streamed message by way of Amazon Kinesis containing a immediate and completion (response) pair.
- The perform will get an embedding for each the immediate and completion (response), and computes the cosine distance between the 2 vectors.
- The perform sends that info to CloudWatch metrics.
Sentiment and toxicity
Monitoring sentiment means that you can gauge the general tone and emotional impression of the responses, whereas toxicity evaluation supplies an essential measure of the presence of offensive, disrespectful, or dangerous language in LLM outputs. Any shifts in sentiment or toxicity needs to be carefully monitored to make sure the mannequin is behaving as anticipated. The next diagram illustrates the metric compute module.

Fig 3: Metric compute module – sentiment and toxicity
The workflow consists of the next steps:
- A Lambda perform receives a immediate and completion (response) pair via Amazon Kinesis.
- By way of AWS Step Capabilities orchestration, the perform calls Amazon Comprehend to detect the sentiment and toxicity.
- The perform saves the data to CloudWatch metrics.
For extra details about detecting sentiment and toxicity with Amazon Comprehend, discuss with Build a robust text-based toxicity predictor and Flag harmful content using Amazon Comprehend toxicity detection.
Ratio of refusals
A rise in refusals, akin to when an LLM denies completion attributable to lack of understanding, might imply that both malicious customers try to make use of the LLM in methods which can be supposed to jailbreak it, or that customers’ expectations aren’t being met and they’re getting low-value responses. One option to gauge how typically that is taking place is by evaluating customary refusals from the LLM mannequin getting used with the precise responses from the LLM. For instance, the next are a few of Anthropic’s Claude v2 LLM frequent refusal phrases:
“Sadly, I wouldn't have sufficient context to supply a substantive response. Nevertheless, I'm an AI assistant created by Anthropic to be useful, innocent, and trustworthy.”
“I apologize, however I can't advocate methods to…”
“I am an AI assistant created by Anthropic to be useful, innocent, and trustworthy.”
On a hard and fast set of prompts, a rise in these refusals could be a sign that the mannequin has turn out to be overly cautious or delicate. The inverse case also needs to be evaluated. It might be a sign that the mannequin is now extra inclined to interact in poisonous or dangerous conversations.
To assist mannequin integrity and mannequin refusal ratio, we will examine the response with a set of identified refusal phrases from the LLM. This might be an precise classifier that may clarify why the mannequin refused the request. You’ll be able to take the cosine distance between the response and identified refusal responses from the mannequin being monitored. The next diagram illustrates this metric compute module.

Fig 4: Metric compute module – ratio of refusals
The workflow consists of the next steps:
- A Lambda perform receives a immediate and completion (response) and will get an embedding from the response utilizing Amazon Titan.
- The perform computes the cosine or Euclidian distance between the response and present refusal prompts cached in reminiscence.
- The perform sends that common to CloudWatch metrics.
Another choice is to make use of fuzzy matching for a simple however much less highly effective strategy to check the identified refusals to LLM output. Check with the Python documentation for an instance.
Abstract
LLM observability is a important observe for guaranteeing the dependable and reliable use of LLMs. Monitoring, understanding, and guaranteeing the accuracy and reliability of LLMs can assist you mitigate the dangers related to these AI fashions. By monitoring hallucinations, unhealthy completions (responses), and prompts, you can also make positive your LLM stays on monitor and delivers the worth you and your customers are in search of. On this put up, we mentioned just a few metrics to showcase examples.
For extra details about evaluating basis fashions, discuss with Use SageMaker Clarify to evaluate foundation models, and browse further example notebooks accessible in our GitHub repository. You may also discover methods to operationalize LLM evaluations at scale in Operationalize LLM Evaluation at Scale using Amazon SageMaker Clarify and MLOps services. Lastly, we advocate referring to Evaluate large language models for quality and responsibility to be taught extra about evaluating LLMs.
Concerning the Authors
 Bruno Klein is a Senior Machine Studying Engineer with AWS Skilled Companies Analytics Apply. He helps prospects implement massive information and analytics options. Outdoors of labor, he enjoys spending time with household, touring, and attempting new meals.
Bruno Klein is a Senior Machine Studying Engineer with AWS Skilled Companies Analytics Apply. He helps prospects implement massive information and analytics options. Outdoors of labor, he enjoys spending time with household, touring, and attempting new meals.
 Rushabh Lokhande is a Senior Knowledge & ML Engineer with AWS Skilled Companies Analytics Apply. He helps prospects implement massive information, machine studying, and analytics options. Outdoors of labor, he enjoys spending time with household, studying, operating, and taking part in golf.
Rushabh Lokhande is a Senior Knowledge & ML Engineer with AWS Skilled Companies Analytics Apply. He helps prospects implement massive information, machine studying, and analytics options. Outdoors of labor, he enjoys spending time with household, studying, operating, and taking part in golf.