Meet Hydragen: A {Hardware}-Conscious Precise Implementation of Consideration with Shared Prefixes
As synthetic intelligence continues to permeate each side of expertise, optimizing the efficiency of huge language fashions (LLMs) for sensible purposes has develop into a pivotal problem. The appearance of Transformer-based LLMs has revolutionized how we work together with AI, enabling purposes that vary from conversational brokers to advanced problem-solving instruments. Nonetheless, the widespread deployment of those fashions, particularly in eventualities the place they course of batches of sequences sharing frequent prefixes, has highlighted a major effectivity bottleneck. Conventional consideration mechanisms, whereas foundational to the success of LLMs, usually battle with computational redundancy when sequences inside a batch share a place to begin. This inefficiency strains computing assets and limits the scalability of LLM purposes.
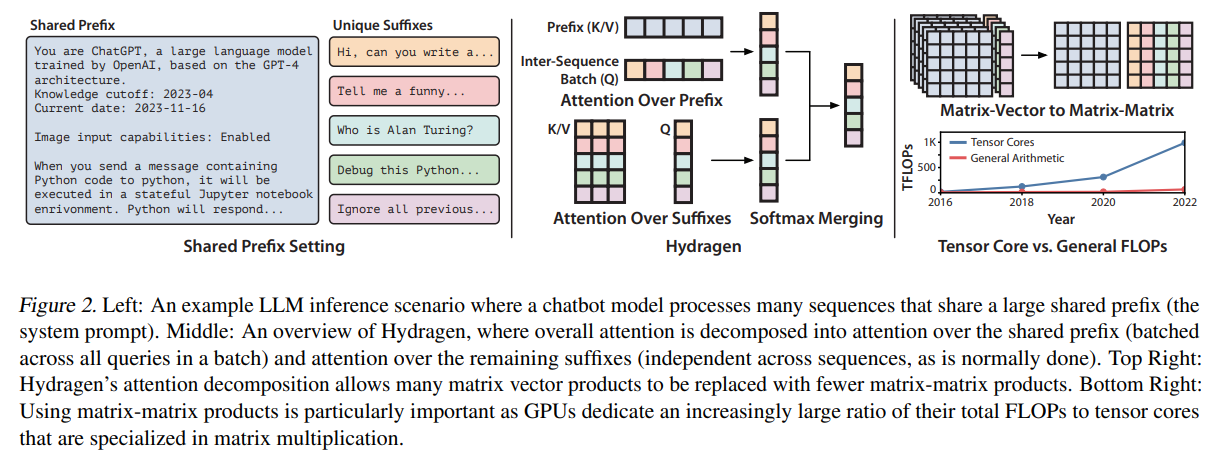
A groundbreaking strategy by the analysis group from Stanford College, the College of Oxford, and the College of Waterloo named Hydragen has been launched to deal with this problem. Hydragen is ingeniously designed to optimize LLM inference in shared-prefix eventualities, dramatically enhancing throughput and lowering computational overhead. By decomposing the eye operation into separate computations for shared prefixes and distinctive suffixes, Hydragen minimizes redundant reminiscence reads and maximizes the effectivity of matrix multiplications—a course of higher aligned with the capabilities of contemporary GPUs. This decomposition permits for the batching of consideration queries throughout sequences when processing the shared prefix, considerably enhancing computational effectivity.
Hydragen’s innovation lies in its two-fold strategy. Firstly, it decomposes the eye mechanism to deal with the shared prefixes and the distinct suffixes of sequences individually. This technique cleverly circumvents the inefficiencies of conventional consideration computations, which deal with every sequence independently, resulting in pointless repetition of computations for the shared segments. Secondly, Hydragen introduces inter-sequence batching for the shared prefix, leveraging the uniformity of this phase throughout sequences to carry out a single, consolidated consideration computation. This methodology reduces the workload on the GPU and ensures that the computational energy of tensor cores is used to its fullest potential.
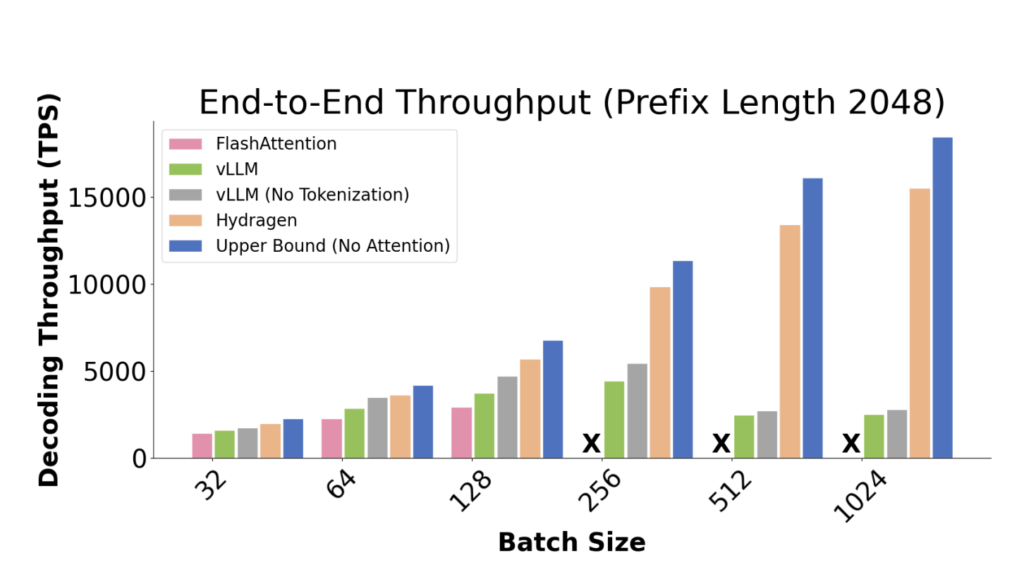
The influence of Hydragen is profound, providing as much as 32 instances enchancment in end-to-end LLM throughput in comparison with present strategies. Such efficiency enhancement is especially vital because it scales with each the batch dimension and the size of the shared prefix, showcasing Hydragen’s adaptability to numerous operational scales and eventualities. Furthermore, Hydragen’s methodology extends past easy prefix-suffix splits, accommodating extra advanced, tree-based sharing patterns frequent in superior LLM purposes. This flexibility permits Hydragen to considerably cut back inference instances in varied settings, from chatbot interactions to aggressive programming challenges.
The outcomes of implementing Hydragen are compelling, underscoring its functionality to remodel LLM inference. Not solely does Hydragen dramatically improve throughput, nevertheless it additionally permits the environment friendly processing of very lengthy shared contexts with minimal throughput penalty. Which means LLMs can now deal with extra in depth and context-rich prompts with out a corresponding improve in computational value or time. As an illustration, in duties involving lengthy doc query answering, Hydragen demonstrates its superiority by processing queries in considerably much less time than conventional strategies, even when coping with paperwork with tens of 1000’s of lengthy tokens.
In conclusion, the event of Hydragen marks a major milestone in optimizing LLMs for real-world purposes. The important thing takeaways from this analysis embody:
- Modern Decomposition: Hydragen’s distinctive consideration decomposition methodology considerably enhances computational effectivity for batches of sequences with shared prefixes.
- Enhanced Throughput: Hydragen demonstrates as much as a 32x enchancment in throughput, setting a brand new commonplace for LLM efficiency, particularly in large-batch and shared-prefix eventualities.
- Versatile Software: The methodology is adaptable to advanced sharing patterns, making it appropriate for a variety of LLM purposes, from conversational AI to intricate problem-solving instruments.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and need to create new merchandise that make a distinction.





