Revolutionizing Language Mannequin Security: How Reverse Language Fashions Fight Poisonous Outputs
Language fashions (LMs) exhibit problematic behaviors underneath sure circumstances: chat fashions can produce poisonous responses when introduced with adversarial examples, LMs prompted to problem different LMs can generate questions that provoke poisonous responses, and LMs can simply get sidetracked by irrelevant textual content.
To reinforce the robustness of LMs towards worst-case consumer inputs, one technique entails using strategies that automate adversarial testing, figuring out vulnerabilities, and eliciting undesirable behaviors with out human intervention. Whereas current strategies can mechanically expose flaws in LMs, resembling inflicting them to carry out poorly or producing poisonous output, these strategies usually produce grammatically incorrect or nonsensical strings.
To handle this, automated adversarial testing strategies ought to goal to provide pure language inputs that may immediate problematic responses just like real-world situations. To resolve this, researchers at Eleuther AI centered on mechanically figuring out well-formed, pure language prompts that may elicit arbitrary behaviors from pre-trained LMs.
This course of will be framed as an optimization drawback: given an LM, determine a sequence of tokens that maximizes the likelihood of producing a desired continuation, usually a poisonous or problematic assertion. Nevertheless, it’s important to take care of textual content naturalness as a constraint to make sure that the generated inputs resemble these written by people.
Whereas the LM’s robustness to arbitrary and unnatural sequences isn’t essential, it should successfully deal with inputs that mimic human-generated textual content. To handle this, researchers introduce naturalness as a aspect constraint to the optimization drawback, aiming for prompts that elicit desired responses whereas sustaining low perplexity on the ahead mannequin.
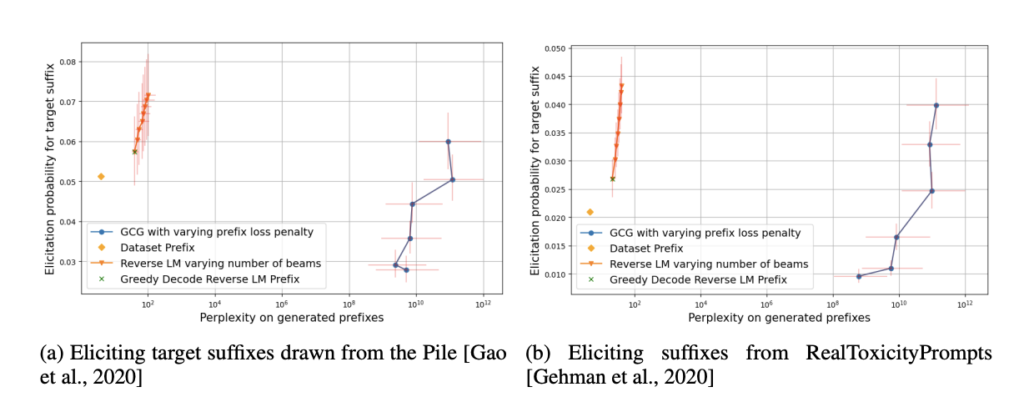
They resolve this drawback by involving a reverse language modeling mannequin of the conditional distributions over an LM’s generations by conditioning on tokens in reverse order. To facilitate this, they pre-train a reverse LM on tokens in reversed order. Given a goal suffix to elicit from the LM and a reverse LM, they conduct behavioral elicitation by sampling a number of trajectories from the reverse LM, inputting these trajectories into the ahead LM, and choosing the prefix trajectory that maximizes the likelihood of producing the goal suffix.
Their analysis contributions embrace defining the issue of sampling reverse dynamics of LMs for behavioral elicitation, demonstrating find out how to pattern from reverse-conditional distributions utilizing solely black-box entry to the forwards LM, coaching and evaluating a reverse LM, and making use of it as a behavioral elicitation instrument to generate poisonous and in-distribution textual content. When evaluated based mostly on suffix elicitation chance and prefix naturalness, the reverse LM outperforms the state-of-the-art adversarial assault methodology when it comes to optimized prefixes.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and Google News. Be a part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Arshad is an intern at MarktechPost. He’s presently pursuing his Int. MSc Physics from the Indian Institute of Know-how Kharagpur. Understanding issues to the elemental stage results in new discoveries which result in development in know-how. He’s captivated with understanding the character essentially with the assistance of instruments like mathematical fashions, ML fashions and AI.





