Introducing ASPIRE for selective prediction in LLMs – Google Analysis Weblog

Within the fast-evolving panorama of synthetic intelligence, massive language fashions (LLMs) have revolutionized the best way we work together with machines, pushing the boundaries of pure language understanding and technology to unprecedented heights. But, the leap into high-stakes decision-making functions stays a chasm too vast, primarily as a result of inherent uncertainty of mannequin predictions. Conventional LLMs generate responses recursively, but they lack an intrinsic mechanism to assign a confidence rating to those responses. Though one can derive a confidence rating by summing up the possibilities of particular person tokens within the sequence, conventional approaches usually fall quick in reliably distinguishing between right and incorrect solutions. However what if LLMs may gauge their very own confidence and solely make predictions after they’re certain?
Selective prediction goals to do that by enabling LLMs to output a solution together with a variety rating, which signifies the chance that the reply is right. With selective prediction, one can higher perceive the reliability of LLMs deployed in quite a lot of functions. Prior analysis, reminiscent of semantic uncertainty and self-evaluation, has tried to allow selective prediction in LLMs. A typical strategy is to make use of heuristic prompts like “Is the proposed reply True or False?” to set off self-evaluation in LLMs. Nevertheless, this strategy could not work properly on difficult question answering (QA) duties.
 |
| The OPT-2.7B mannequin incorrectly solutions a query from the TriviaQA dataset: “Which vitamin helps regulate blood clotting?” with “Vitamin C”. With out selective prediction, LLMs could output the unsuitable reply which, on this case, could lead on customers to take the unsuitable vitamin. With selective prediction, LLMs will output a solution together with a variety rating. If the choice rating is low (0.1), LLMs will additional output “I don’t know!” to warn customers to not belief it or confirm it utilizing different sources. |
In “Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs“, introduced at Findings of EMNLP 2023, we introduce ASPIRE — a novel framework meticulously designed to boost the selective prediction capabilities of LLMs. ASPIRE fine-tunes LLMs on QA duties by way of parameter-efficient fine-tuning, and trains them to judge whether or not their generated solutions are right. ASPIRE permits LLMs to output a solution together with a confidence rating for that reply. Our experimental outcomes show that ASPIRE considerably outperforms state-of-the-art selective prediction strategies on quite a lot of QA datasets, such because the CoQA benchmark.
The mechanics of ASPIRE
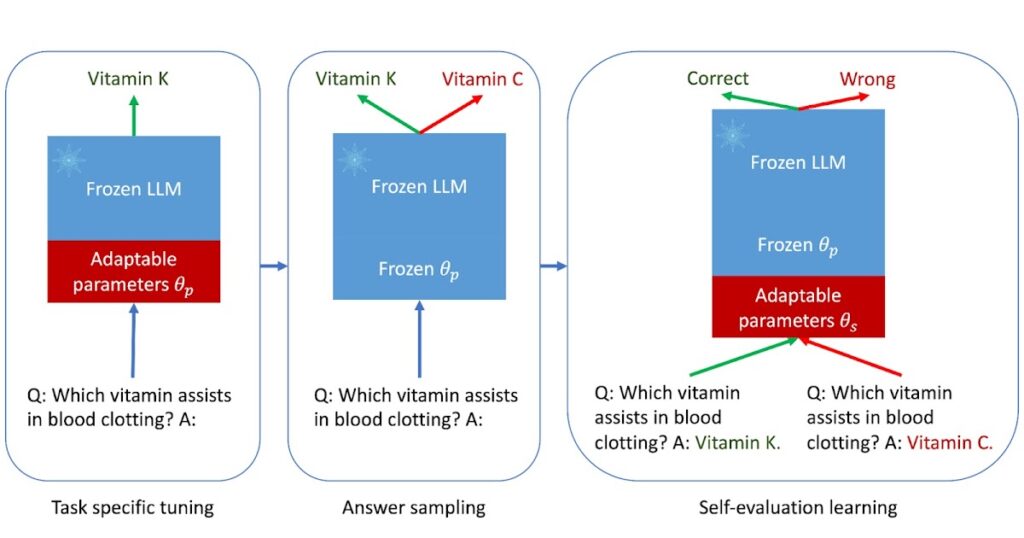
Think about instructing an LLM to not solely reply questions but additionally consider these solutions — akin to a pupil verifying their solutions behind the textbook. That is the essence of ASPIRE, which entails three levels: (1) task-specific tuning, (2) reply sampling, and (3) self-evaluation studying.
Activity-specific tuning: ASPIRE performs task-specific tuning to coach adaptable parameters (θp) whereas freezing the LLM. Given a coaching dataset for a generative activity, it fine-tunes the pre-trained LLM to enhance its prediction efficiency. In direction of this finish, parameter-efficient tuning strategies (e.g., soft prompt tuning and LoRA) is perhaps employed to adapt the pre-trained LLM on the duty, given their effectiveness in acquiring robust generalization with small quantities of goal activity knowledge. Particularly, the LLM parameters (θ) are frozen and adaptable parameters (θp) are added for fine-tuning. Solely θp are up to date to attenuate the usual LLM coaching loss (e.g., cross-entropy). Such fine-tuning can enhance selective prediction efficiency as a result of it not solely improves the prediction accuracy, but additionally enhances the chance of right output sequences.
Reply sampling: After task-specific tuning, ASPIRE makes use of the LLM with the discovered θp to generate completely different solutions for every coaching query and create a dataset for self-evaluation studying. We goal to generate output sequences which have a excessive chance. We use beam search because the decoding algorithm to generate high-likelihood output sequences and the Rouge-L metric to find out if the generated output sequence is right.
Self-evaluation studying: After sampling high-likelihood outputs for every question, ASPIRE provides adaptable parameters (θs) and solely fine-tunes θs for studying self-evaluation. Because the output sequence technology solely relies on θ and θp, freezing θ and the discovered θp can keep away from altering the prediction behaviors of the LLM when studying self-evaluation. We optimize θs such that the tailored LLM can distinguish between right and incorrect solutions on their very own.
 |
| The three levels of the ASPIRE framework. |
Within the proposed framework, θp and θs might be skilled utilizing any parameter-efficient tuning strategy. On this work, we use soft prompt tuning, a easy but efficient mechanism for studying “soft prompts” to situation frozen language fashions to carry out particular downstream duties extra successfully than conventional discrete textual content prompts. The driving power behind this strategy lies within the recognition that if we will develop prompts that successfully stimulate self-evaluation, it must be potential to find these prompts by means of gentle immediate tuning together with focused coaching targets.
 |
| Implementation of the ASPIRE framework by way of gentle immediate tuning. We first generate the reply to the query with the primary gentle immediate after which compute the discovered self-evaluation rating with the second gentle immediate. |
After coaching θp and θs, we get hold of the prediction for the question by way of beam search decoding. We then outline a variety rating that mixes the chance of the generated reply with the discovered self-evaluation rating (i.e., the chance of the prediction being right for the question) to make selective predictions.
Outcomes
To show ASPIRE’s efficacy, we consider it throughout three question-answering datasets — CoQA, TriviaQA, and SQuAD — utilizing numerous open pre-trained transformer (OPT) fashions. By coaching θp with gentle immediate tuning, we noticed a considerable hike within the LLMs’ accuracy. For instance, the OPT-2.7B mannequin tailored with ASPIRE demonstrated improved efficiency over the bigger, pre-trained OPT-30B mannequin utilizing the CoQA and SQuAD datasets. These outcomes recommend that with appropriate variations, smaller LLMs might need the aptitude to match or probably surpass the accuracy of bigger fashions in some eventualities.
 |
When delving into the computation of choice scores with fastened mannequin predictions, ASPIRE acquired a better AUROC rating (the chance {that a} randomly chosen right output sequence has a better choice rating than a randomly chosen incorrect output sequence) than baseline strategies throughout all datasets. For instance, on the CoQA benchmark, ASPIRE improves the AUROC from 51.3% to 80.3% in comparison with the baselines.
An intriguing sample emerged from the TriviaQA dataset evaluations. Whereas the pre-trained OPT-30B mannequin demonstrated increased baseline accuracy, its efficiency in selective prediction didn’t enhance considerably when conventional self-evaluation strategies — Self-eval and P(True) — have been utilized. In distinction, the smaller OPT-2.7B mannequin, when enhanced with ASPIRE, outperformed on this facet. This discrepancy underscores a significant perception: bigger LLMs using typical self-evaluation strategies might not be as efficient in selective prediction as smaller, ASPIRE-enhanced fashions.
 |
Our experimental journey with ASPIRE underscores a pivotal shift within the panorama of LLMs: The capability of a language mannequin will not be the be-all and end-all of its efficiency. As an alternative, the effectiveness of fashions might be drastically improved by means of strategic variations, permitting for extra exact, assured predictions even in smaller fashions. Because of this, ASPIRE stands as a testomony to the potential of LLMs that may judiciously verify their very own certainty and decisively outperform bigger counterparts in selective prediction duties.
Conclusion
In conclusion, ASPIRE isn’t just one other framework; it is a imaginative and prescient of a future the place LLMs might be trusted companions in decision-making. By honing the selective prediction efficiency, we’re inching nearer to realizing the complete potential of AI in vital functions.
Our analysis has opened new doorways, and we invite the neighborhood to construct upon this basis. We’re excited to see how ASPIRE will encourage the subsequent technology of LLMs and past. To be taught extra about our findings, we encourage you to learn our paper and be a part of us on this thrilling journey in the direction of making a extra dependable and self-aware AI.
Acknowledgments
We gratefully acknowledge the contributions of Sayna Ebrahimi, Sercan O Arik, Tomas Pfister, and Somesh Jha.





