This AI Analysis Introduces Quick and Expressive LLM Inference with RadixAttention and SGLang
Superior prompting mechanisms, management move, contact with exterior environments, many chained technology calls, and complicated actions are increasing the utilization of Giant Language Fashions (LLMs). Then again, efficient strategies for creating and working such applications are severely missing. LMSYS ORG presents SGLang, a Structured Era Language for LLMs that collaborates on the structure of each the backend runtime system and the frontend languages. SGLang improves interactions with LLMs, making them quicker and extra controllable.
Backend: Computerized KV Cache Reuse with RadixAttention
To benefit from these reuse alternatives systematically, the staff supplies RadixAttention, a brand new computerized KV cache reuse methodology whereas working. The KV cache just isn’t faraway from the radix tree when a technology request is accomplished; it’s saved for each the technology outcomes and the prompts. This knowledge construction makes environment friendly search, insertion, and eviction of prefixes doable. To enhance the cache hit fee, the researchers make use of a cache-aware scheduling coverage along with a Least Just lately Used (LRU) eviction coverage. It may be eagerly executed utilizing an interpreter or traced as a dataflow graph and run with a graph executor. Within the second state of affairs, compiler optimizations like code relocation, instruction choice, and auto-tuning develop into doable.
Frontend: Straightforward LLM Programming with SGLang
The staff additionally presents SGLang, an embedded domain-specific language in Python, on the entrance finish. Advanced strategies of prompting, management move, multi-modality, decoding limitations, and exterior interplay may be merely articulated utilizing it. Customers can run an SGLang perform by native fashions, OpenAI, Anthropic, and Gemini.
As talked about by the staff, a lot of SGLang’s syntax takes cues from Steerage. Customers additionally take care of batching and intra-program parallelism along with introducing new primitives. With all these new options, SGLang is far more highly effective than earlier than. Enhance the cache hit fee with an eviction coverage and a scheduling method that considers cache consciousness.
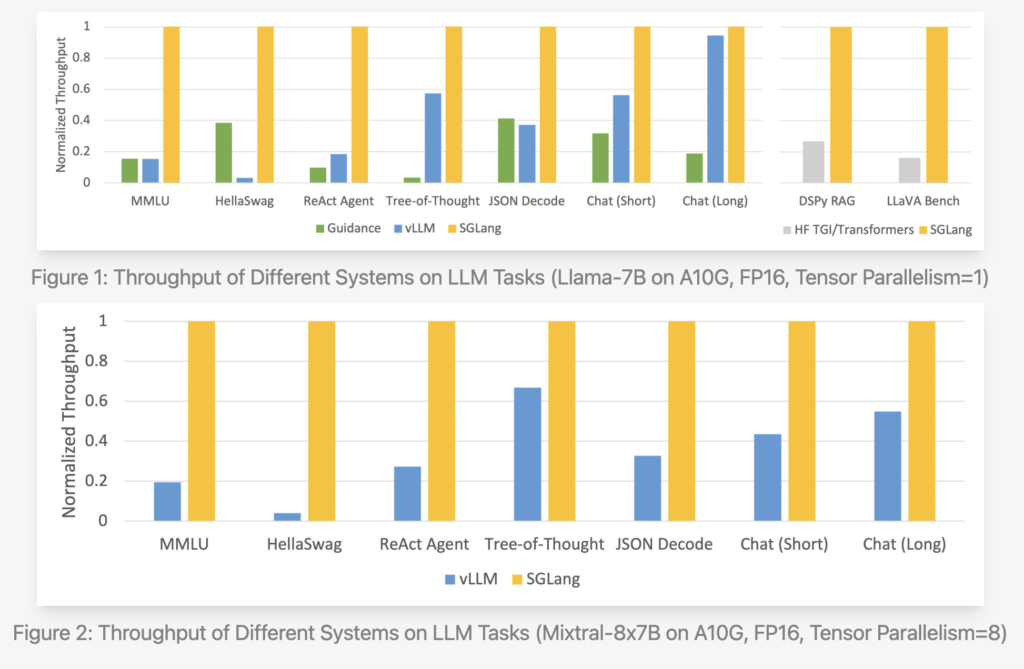
The researchers recorded the throughput their system attained when testing it on the next typical LLM workloads:
- MMLU: A multi-tasking, 5-shot, multiple-choice take a look at.
- HellaSwag: An evaluation software for 20-shot, multiple-choice phrase completion.
- An agent job based mostly on immediate traces taken from the unique ReAct paper is ReAct Agent.
- Tree-of-Thought: A GSM-8K problem-solving immediate based mostly on bespoke tree searches.
- A JSON decoder can parse a Wikipedia article and return its knowledge in a JSON format.
- The chat (quick) benchmark is an artificial chat through which every dialog consists of 4 turns with transient LLM outputs.
- This artificial chat benchmark makes use of lengthy LLM outputs and 4 turns per dialog.
- DSPy RAG: A pipeline within the DSPy tutorial that makes use of retrieval to reinforce technology.
- The LLaVA-in-the-wild benchmark is used to run the imaginative and prescient language mannequin LLaVA v1.5.
Utilizing the Llama-7B and Mixtral-8x7B fashions on NVIDIA A10G GPUs, the staff utilized SGLang to typical LLM workloads similar to agent, reasoning, extraction, chat, and few-shot studying duties. The researchers used Hugging Face TGI v1.3.0, recommendation v0.1.8, and vllm v0.2.5 as a place to begin. SGLang outperforms present techniques, particularly Guid, by an element of as much as 5 when it comes to throughput. It additionally carried out fairly effectively in latency checks, particularly these involving the preliminary token, the place a prefix cache hit could be very helpful. Present techniques do a horrible job of dealing with refined LLM applications, however whereas creating the SGLang runtime, it was noticed {that a} vital optimization alternative: KV cache reuse. By reusing the KV cache, many prompts that share the identical prefix can use the intermediate KV cache, which saves each reminiscence and computation. Many different KV cache reuse strategies, together with ance and vLLM, may be present in sophisticated applications that use many LLM calls. The automated KV cache reuse with RadixAttention, the interpreter’s means to supply intra-program parallelism, and the truth that the frontend and backend techniques have been co-designed all contribute to those advantages.
Take a look at the Code and Blog. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
Dhanshree Shenwai is a Pc Science Engineer and has an excellent expertise in FinTech firms protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in functions of AI. She is keen about exploring new applied sciences and developments in right this moment’s evolving world making everybody’s life simple.






