Construct enterprise-ready generative AI options with Cohere basis fashions in Amazon Bedrock and Weaviate vector database on AWS Market

Generative AI solutions have the potential to rework companies by boosting productiveness and enhancing buyer experiences, and utilizing massive language fashions (LLMs) with these options has develop into more and more in style. Constructing proofs of idea is comparatively easy as a result of cutting-edge foundation models can be found from specialised suppliers by means of a easy API name. Subsequently, organizations of varied sizes and throughout completely different industries have begun to reimagine their merchandise and processes utilizing generative AI.
Regardless of their wealth of basic information, state-of-the-art LLMs solely have entry to the knowledge they have been educated on. This may result in factual inaccuracies (hallucinations) when the LLM is prompted to generate textual content primarily based on info they didn’t see throughout their coaching. Subsequently, it’s essential to bridge the hole between the LLM’s basic information and your proprietary information to assist the mannequin generate extra correct and contextual responses whereas decreasing the danger of hallucinations. The normal methodology of fine-tuning, though efficient, could be compute-intensive, costly, and requires technical experience. An alternative choice to think about is named Retrieval Augmented Generation (RAG), which gives LLMs with extra info from an exterior information supply that may be up to date simply.
Moreover, enterprises should guarantee information safety when dealing with proprietary and delicate information, corresponding to private information or mental property. That is significantly necessary for organizations working in closely regulated industries, corresponding to monetary companies and healthcare and life sciences. Subsequently, it’s necessary to grasp and management the stream of your information by means of the generative AI software: The place is the mannequin positioned? The place is the information processed? Who has entry to the information? Will the information be used to coach fashions, finally risking the leak of delicate information to public LLMs?
This publish discusses how enterprises can construct correct, clear, and safe generative AI functions whereas maintaining full management over proprietary information. The proposed resolution is a RAG pipeline utilizing an AI-native expertise stack, whose parts are designed from the bottom up with AI at their core, quite than having AI capabilities added as an afterthought. We display the best way to construct an end-to-end RAG software utilizing Cohere’s language models by means of Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The accompanying supply code is out there within the related GitHub repository hosted by Weaviate. Though AWS won’t be liable for sustaining or updating the code within the associate’s repository, we encourage clients to attach with Weaviate straight relating to any desired updates.
Answer overview
The next high-level structure diagram illustrates the proposed RAG pipeline with an AI-native expertise stack for constructing correct, clear, and safe generative AI options.
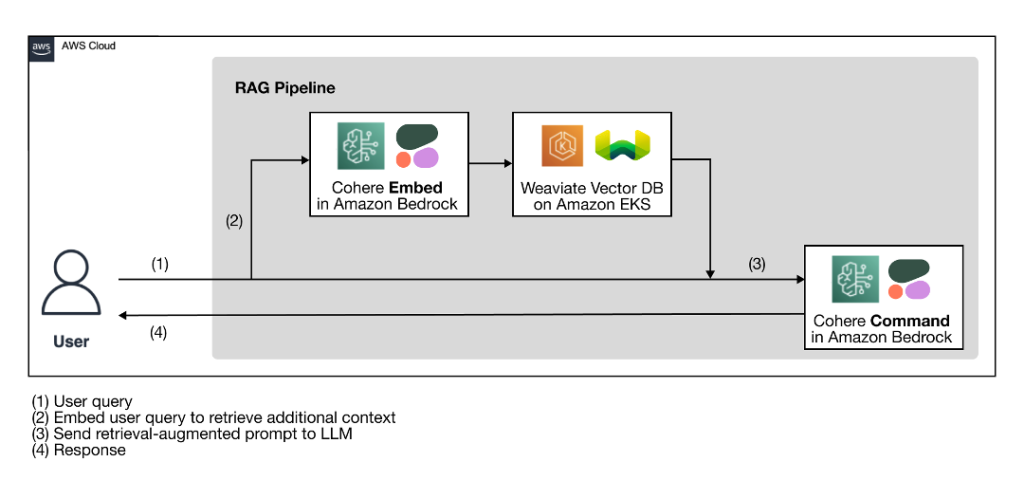
Determine 1: RAG workflow utilizing Cohere’s language fashions by means of Amazon Bedrock and a Weaviate vector database on AWS Market
As a preparation step for the RAG workflow, a vector database, which serves because the exterior information supply, is ingested with the extra context from the proprietary information. The precise RAG workflow follows the 4 steps illustrated within the diagram:
- The consumer enters their question.
- The consumer question is used to retrieve related extra context from the vector database. That is finished by producing the vector embeddings of the consumer question with an embedding mannequin to carry out a vector search to retrieve probably the most related context from the database.
- The retrieved context and the consumer question are used to reinforce a immediate template. The retrieval-augmented immediate helps the LLM generate a extra related and correct completion, minimizing hallucinations.
- The consumer receives a extra correct response primarily based on their question.
The AI-native expertise stack illustrated within the structure diagram has two key parts: Cohere language fashions and a Weaviate vector database.
Cohere language fashions in Amazon Bedrock
The Cohere Platform brings language fashions with state-of-the-art efficiency to enterprises and builders by means of a easy API name. There are two key varieties of language processing capabilities that the Cohere Platform gives—generative and embedding—and every is served by a unique kind of mannequin:
- Text generation with Command – Builders can entry endpoints that energy generative AI capabilities, enabling functions corresponding to conversational, query answering, copywriting, summarization, info extraction, and extra.
- Text representation with Embed – Builders can entry endpoints that seize the semantic which means of textual content, enabling functions corresponding to vector search engines like google, textual content classification and clustering, and extra. Cohere Embed is available in two varieties, an English language mannequin and a multilingual mannequin, each of that are now available on Amazon Bedrock.
The Cohere Platform empowers enterprises to customise their generative AI resolution privately and securely by means of the Amazon Bedrock deployment. Amazon Bedrock is a completely managed cloud service that allows improvement groups to construct and scale generative AI functions shortly while helping keep your data and applications secure and private. Your information is just not used for service enhancements, isn’t shared with third-party mannequin suppliers, and stays within the Region the place the API name is processed. The information is at all times encrypted in transit and at relaxation, and you’ll encrypt the information utilizing your personal keys. Amazon Bedrock helps safety necessities, together with U.S. Well being Insurance coverage Portability and Accountability Act (HIPAA) eligibility and Normal Information Safety Regulation (GDPR) compliance. Moreover, you possibly can securely combine and simply deploy your generative AI functions utilizing the AWS instruments you’re already acquainted with.
Weaviate vector database on AWS Market
Weaviate is an AI-native vector database that makes it easy for improvement groups to construct safe and clear generative AI functions. Weaviate is used to retailer and search each vector information and supply objects, which simplifies improvement by eliminating the necessity to host and combine separate databases. Weaviate delivers subsecond semantic search efficiency and might scale to deal with billions of vectors and thousands and thousands of tenants. With a uniquely extensible structure, Weaviate integrates natively with Cohere basis fashions deployed in Amazon Bedrock to facilitate the handy vectorization of knowledge and use its generative capabilities from inside the database.
The Weaviate AI-native vector database offers clients the pliability to deploy it as a bring-your-own-cloud (BYOC) resolution or as a managed service. This showcase makes use of the Weaviate Kubernetes Cluster on AWS Marketplace, a part of Weaviate’s BYOC providing, which permits container-based scalable deployment inside your AWS tenant and VPC with only a few clicks utilizing an AWS CloudFormation template. This strategy ensures that your vector database is deployed in your particular Area near the inspiration fashions and proprietary information to attenuate latency, assist information locality, and shield delicate information whereas addressing potential regulatory necessities, corresponding to GDPR.
Use case overview
Within the following sections, we display the best way to construct a RAG resolution utilizing the AI-native expertise stack with Cohere, AWS, and Weaviate, as illustrated within the resolution overview.
The instance use case generates focused ads for trip keep listings primarily based on a audience. The objective is to make use of the consumer question for the audience (for instance, “household with babies”) to retrieve probably the most related trip keep itemizing (for instance, an inventory with playgrounds shut by) after which to generate an commercial for the retrieved itemizing tailor-made to the audience.

Determine 2: First few rows of trip keep listings out there from Inside Airbnb.
The dataset is out there from Inside Airbnb and is licensed underneath a Creative Commons Attribution 4.0 International License. You will discover the accompanying code within the GitHub repository.
Conditions
To observe alongside and use any AWS companies within the following tutorial, be sure you have an AWS account.
Allow parts of the AI-native expertise stack
First, that you must allow the related parts mentioned within the resolution overview in your AWS account. Full the next steps:
- Within the left Amazon Bedrock console, select Mannequin entry within the navigation pane.
- Select Handle mannequin entry on the highest proper.
- Choose the inspiration fashions of your alternative and request entry.
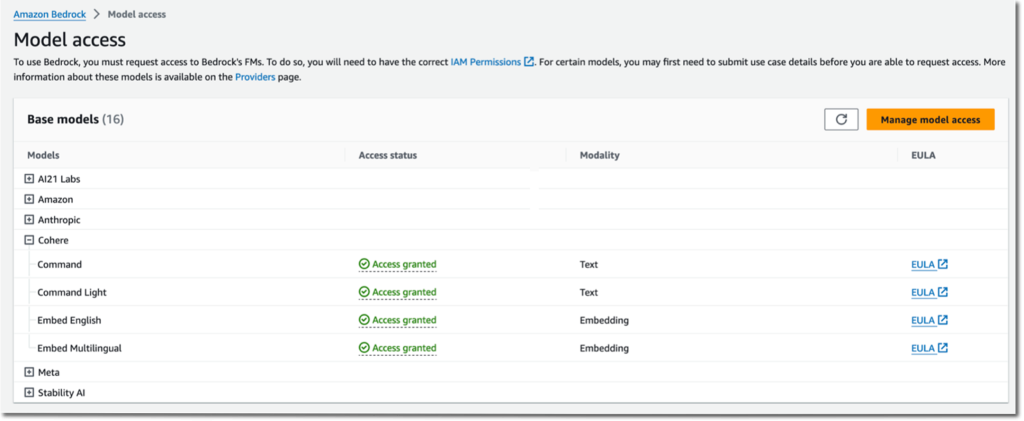
Determine 3: Handle mannequin entry in Amazon Bedrock console.
Subsequent, you arrange a Weaviate cluster.
- Subscribe to the Weaviate Kubernetes Cluster on AWS Marketplace.
- Launch the software program utilizing a CloudFormation template according to your preferred Availability Zone.
The CloudFormation template is pre-populated with default values.
- For Stack title, enter a stack title.
- For helmauthenticationtype, it is suggested to allow authentication by setting
helmauthenticationtypetoapikeyand defining a helmauthenticationapikey. - For helmauthenticationapikey, enter your Weaviate API key.
- For helmchartversion, enter your model quantity. It have to be at the least v.16.8.0. Check with the GitHub repo for the most recent model.
- For helmenabledmodules, be sure that
tex2vec-awsandgenerative-awsare current within the checklist of enabled modules inside Weaviate.
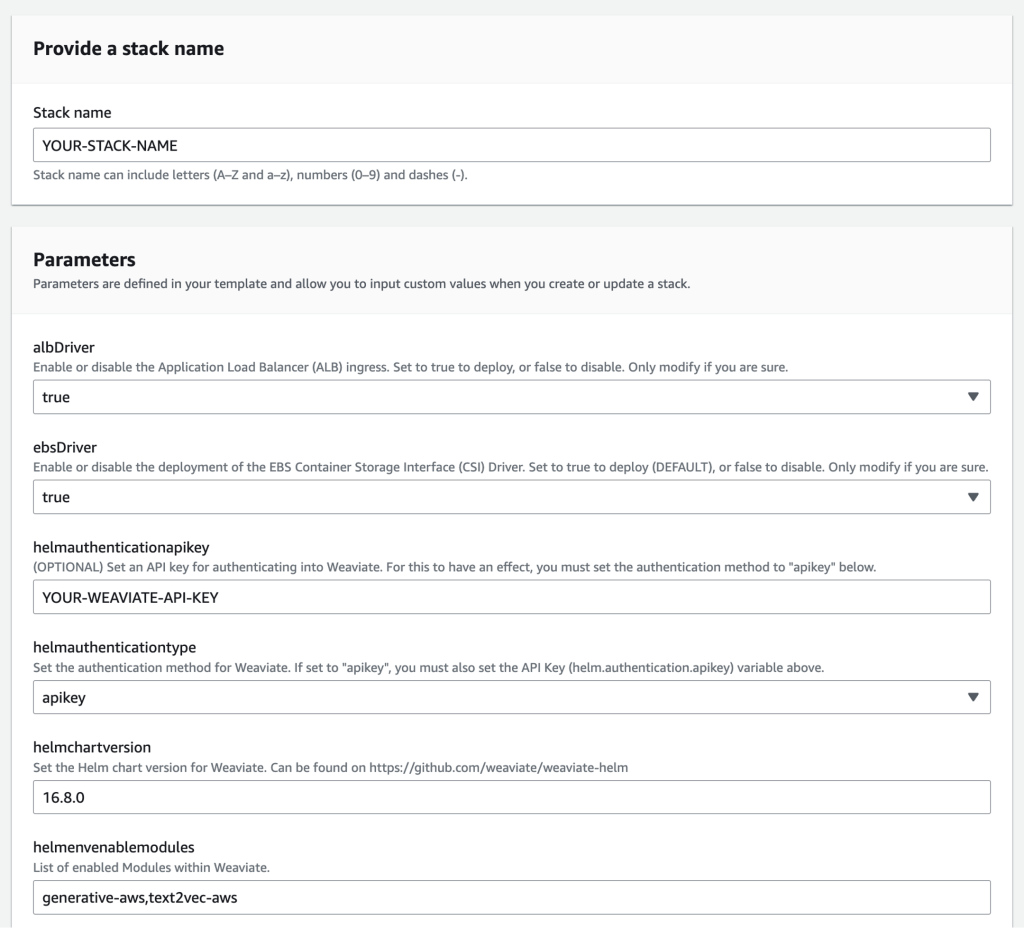
Determine 4: CloudFormation template.
This template takes about half-hour to finish.
Hook up with Weaviate
Full the next steps to hook up with Weaviate:
- Within the Amazon SageMaker console, navigate to Pocket book situations within the navigation pane through Pocket book > Pocket book situations on the left.
- Create a brand new pocket book occasion.
- Set up the Weaviate consumer package deal with the required dependencies:
- Hook up with your Weaviate occasion with the next code:
- Weaviate URL – Entry Weaviate through the load balancer URL. Within the Amazon Elastic Compute Cloud (Amazon EC2) console, select Load balancers within the navigation pane and discover the load balancer. Search for the DNS title column and add
http://in entrance of it. - Weaviate API key – That is the important thing you set earlier within the CloudFormation template (
helmauthenticationapikey). - AWS entry key and secret entry key – You may retrieve the entry key and secret entry key in your consumer within the AWS Identity and Access Management (IAM) console.
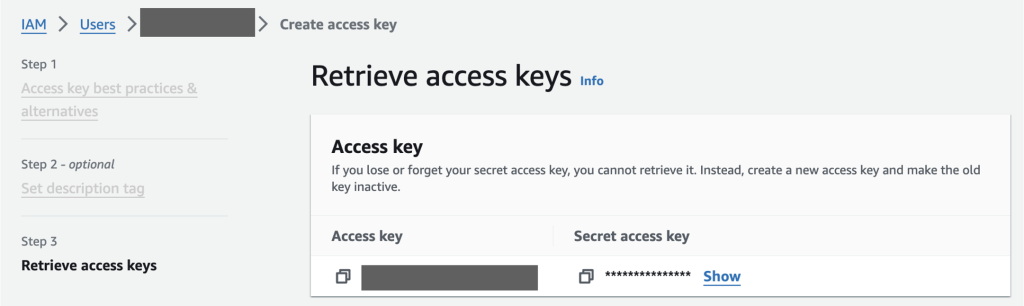
Determine 5: AWS Id and Entry Administration (IAM) console to retrieve AWS entry key and secret entry key.
Configure the Amazon Bedrock module to allow Cohere fashions
Subsequent, you outline a knowledge assortment (class) referred to as Listings to retailer the listings’ information objects, which is analogous to making a desk in a relational database. On this step, you configure the related modules to allow the utilization of Cohere language fashions hosted on Amazon Bedrock natively from inside the Weaviate vector database. The vectorizer (“text2vec-aws“) and generative module (“generative-aws“) are specified within the information assortment definition. Each of those modules take three parameters:
- “service” – Use “
bedrock” for Amazon Bedrock (alternatively, use “sagemaker” for Amazon SageMaker JumpStart) - “Area” – Enter the Area the place your mannequin is deployed
- “mannequin” – Present the inspiration mannequin’s title
See the next code:
Ingest information into the Weaviate vector database
On this step, you outline the construction of the information assortment by configuring its properties. Except for the property’s title and information kind, you may also configure if solely the information object will likely be saved or if it is going to be saved along with its vector embeddings. On this instance, host_name and property_type will not be vectorized:
Run the next code to create the gathering in your Weaviate occasion:
Now you can add objects to Weaviate. You utilize a batch import course of for optimum effectivity. Run the next code to import information. In the course of the import, Weaviate will use the outlined vectorizer to create a vector embedding for every object. The next code hundreds objects, initializes a batch course of, and provides objects to the goal assortment one after the other:
Retrieval Augmented Technology
You may construct a RAG pipeline by implementing a generative search question in your Weaviate occasion. For this, you first outline a immediate template within the type of an f-string that may take within the consumer question ({target_audience}) straight and the extra context ({{host_name}}, {{property_type}}, {{description}}, and {{neighborhood_overview}}) from the vector database at runtime:
Subsequent, you run a generative search question. This prompts the outlined generative mannequin with a immediate that’s comprised of the consumer question in addition to the retrieved information. The next question retrieves one itemizing object (.with_limit(1)) from the Listings assortment that’s most much like the consumer question (.with_near_text({"ideas": target_audience})). Then the consumer question (target_audience) and the retrieved listings properties (["description", "neighborhood", "host_name", "property_type"]) are fed into the immediate template. See the next code:
Within the following instance, you possibly can see that the previous piece of code for target_audience = “Household with babies” retrieves an inventory from the host Marre. The immediate template is augmented with Marre’s itemizing particulars and the audience:
Based mostly on the retrieval-augmented immediate, Cohere’s Command mannequin generates the next focused commercial:
Various customizations
You can also make different customizations to completely different parts within the proposed resolution, corresponding to the next:
- Cohere’s language fashions are additionally out there by means of Amazon SageMaker JumpStart, which gives entry to cutting-edge basis fashions and permits builders to deploy LLMs to Amazon SageMaker, a completely managed service that brings collectively a broad set of instruments to allow high-performance, low-cost machine studying for any use case. Weaviate is built-in with SageMaker as nicely.
- A robust addition to this resolution is the Cohere Rerank endpoint, out there by means of SageMaker JumpStart. Rerank can enhance the relevance of search outcomes from lexical or semantic search. Rerank works by computing semantic relevance scores for paperwork which are retrieved by a search system and rating the paperwork primarily based on these scores. Including Rerank to an software requires solely a single line of code change.
- To cater to completely different deployment necessities of various manufacturing environments, Weaviate could be deployed in varied extra methods. For instance, it’s out there as a direct obtain from Weaviate website, which runs on Amazon Elastic Kubernetes Service (Amazon EKS) or regionally through Docker or Kubernetes. It’s additionally out there as a managed service that may run securely inside a VPC or as a public cloud service hosted on AWS with a 14-day free trial.
- You may serve your resolution in a VPC utilizing Amazon Virtual Private Cloud (Amazon VPC), which permits organizations to launch AWS companies in a logically remoted digital community, resembling a standard community however with the advantages of AWS’s scalable infrastructure. Relying on the labeled stage of sensitivity of the information, organizations may also disable web entry in these VPCs.
Clear up
To forestall surprising prices, delete all of the assets you deployed as a part of this publish. Should you launched the CloudFormation stack, you possibly can delete it through the AWS CloudFormation console. Observe that there could also be some AWS assets, corresponding to Amazon Elastic Block Store (Amazon EBS) volumes and AWS Key Management Service (AWS KMS) keys, that is probably not deleted robotically when the CloudFormation stack is deleted.

Determine 6: Delete all assets through the AWS CloudFormation console.
Conclusion
This publish mentioned how enterprises can construct correct, clear, and safe generative AI functions whereas nonetheless having full management over their information. The proposed resolution is a RAG pipeline utilizing an AI-native expertise stack as a mix of Cohere basis fashions in Amazon Bedrock and a Weaviate vector database on AWS Market. The RAG strategy permits enterprises to bridge the hole between the LLM’s basic information and the proprietary information whereas minimizing hallucinations. An AI-native expertise stack permits quick improvement and scalable efficiency.
You can begin experimenting with RAG proofs of idea in your enterprise-ready generative AI functions utilizing the steps outlined on this publish. The accompanying supply code is out there within the related GitHub repository. Thanks for studying. Be at liberty to supply feedback or suggestions within the feedback part.
In regards to the authors
 James Yi is a Senior AI/ML Accomplice Options Architect within the Expertise Companions COE Tech crew at Amazon Net Providers. He’s captivated with working with enterprise clients and companions to design, deploy, and scale AI/ML functions to derive enterprise worth. Outdoors of labor, he enjoys enjoying soccer, touring, and spending time along with his household.
James Yi is a Senior AI/ML Accomplice Options Architect within the Expertise Companions COE Tech crew at Amazon Net Providers. He’s captivated with working with enterprise clients and companions to design, deploy, and scale AI/ML functions to derive enterprise worth. Outdoors of labor, he enjoys enjoying soccer, touring, and spending time along with his household.
 Leonie Monigatti is a Developer Advocate at Weaviate. Her focus space is AI/ML, and he or she helps builders study generative AI. Outdoors of labor, she additionally shares her learnings in information science and ML on her weblog and on Kaggle.
Leonie Monigatti is a Developer Advocate at Weaviate. Her focus space is AI/ML, and he or she helps builders study generative AI. Outdoors of labor, she additionally shares her learnings in information science and ML on her weblog and on Kaggle.
 Meor Amer is a Developer Advocate at Cohere, a supplier of cutting-edge pure language processing (NLP) expertise. He helps builders construct cutting-edge functions with Cohere’s Massive Language Fashions (LLMs).
Meor Amer is a Developer Advocate at Cohere, a supplier of cutting-edge pure language processing (NLP) expertise. He helps builders construct cutting-edge functions with Cohere’s Massive Language Fashions (LLMs).
 Shun Mao is a Senior AI/ML Accomplice Options Architect within the Rising Applied sciences crew at Amazon Net Providers. He’s captivated with working with enterprise clients and companions to design, deploy and scale AI/ML functions to derive their enterprise values. Outdoors of labor, he enjoys fishing, touring and enjoying Ping-Pong.
Shun Mao is a Senior AI/ML Accomplice Options Architect within the Rising Applied sciences crew at Amazon Net Providers. He’s captivated with working with enterprise clients and companions to design, deploy and scale AI/ML functions to derive their enterprise values. Outdoors of labor, he enjoys fishing, touring and enjoying Ping-Pong.





