This AI Paper Explores How Imaginative and prescient-Language Fashions Improve Autonomous Driving Programs for Higher Resolution-Making and Interactivity
On the convergence of synthetic intelligence, machine studying, and sensor expertise, autonomous driving expertise goals to develop autos that may comprehend their surroundings and make selections akin to a human driver. This discipline focuses on creating programs that understand, predict, and plan driving actions with out human enter, aiming to realize greater security and effectivity requirements.
A main impediment within the growth of self-driving autos is… growing programs able to understanding and reacting to diverse driving circumstances as effectively as human drivers. This entails processing advanced sensory information and responding successfully to dynamic and sometimes unexpected conditions, reaching decision-making and adaptableness that intently matches human capabilities.
Conventional autonomous driving fashions have primarily relied on data-driven approaches, utilizing machine studying skilled on intensive datasets. These fashions instantly translate sensor inputs into car actions. Nevertheless, they should work on dealing with eventualities not lined of their coaching information, demonstrating a niche of their means to generalize and adapt to new, unpredictable circumstances.
DriveLM introduces a novel strategy to this problem by using Imaginative and prescient-Language Fashions (VLMs) particularly for autonomous driving. This mannequin makes use of a graph-structured reasoning course of integrating language-based interactions with visible inputs. This strategy is designed to imitate human reasoning extra intently than standard fashions and is constructed upon common vision-language fashions like BLIP-2 for its simplicity and suppleness in structure.

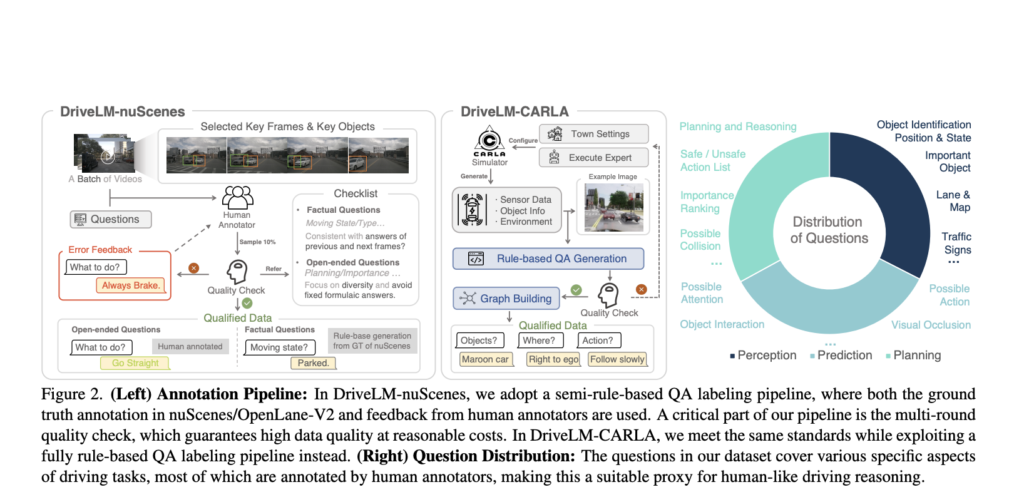
DriveLM relies on Graph Visible Query Answering (GVQA), which processes driving eventualities as interconnected question-answer pairs in a directed graph. This construction facilitates logical reasoning in regards to the scene, a vital element for decision-making in driving. The mannequin employs the BLIP-2 VLM, fine-tuned on the DriveLM-nuScenes dataset, a set with scene-level descriptions and frame-level question-answers designed to allow efficient understanding and reasoning about driving eventualities. The last word objective of DriveLM is to translate a picture into the specified car movement by varied VQA phases, encompassing notion, prediction, planning, habits, and movement.
By way of efficiency and outcomes, DriveLM demonstrates exceptional generalization capabilities in dealing with advanced driving eventualities. It reveals a pronounced means to adapt to unseen objects and sensor configurations not encountered throughout coaching. This adaptability represents a major development over present fashions, showcasing the potential of DriveLM in real-world driving conditions.
DriveLM outperforms present fashions in duties that require understanding and reacting to new conditions. Its graph-structured strategy to reasoning about driving eventualities allows it to carry out competitively in comparison with state-of-the-art driving-specific architectures. Furthermore, DriveLM demonstrates promising baseline efficiency on P1-P3 query answering with out context. Nevertheless, the necessity for specialised architectures or prompting schemes past naive concatenation to higher use the logical dependencies in GVQA is highlighted.
General, DriveLM represents a major step ahead in autonomous driving expertise. By integrating language reasoning with visible notion, the mannequin achieves higher generalization and opens avenues for extra interactive and human-friendly autonomous driving programs. This strategy may probably revolutionize the sector, providing a mannequin that understands and navigates advanced driving environments with a perspective akin to human understanding and reasoning.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to affix our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.






