Enhance your Steady Diffusion prompts with Retrieval Augmented Technology
Textual content-to-image technology is a quickly rising subject of synthetic intelligence with functions in a wide range of areas, similar to media and leisure, gaming, ecommerce product visualization, promoting and advertising and marketing, architectural design and visualization, creative creations, and medical imaging.
Stable Diffusion is a text-to-image mannequin that empowers you to create high-quality photos inside seconds. In November 2022, we announced that AWS clients can generate photos from textual content with Stable Diffusion fashions in Amazon SageMaker JumpStart, a machine studying (ML) hub providing fashions, algorithms, and options. The evolution continued in April 2023 with the introduction of Amazon Bedrock, a totally managed service providing entry to cutting-edge basis fashions, together with Steady Diffusion, by a handy API.
As an ever-increasing variety of clients embark on their text-to-image endeavors, a standard hurdle arises—methods to craft prompts that wield the facility to yield high-quality, purpose-driven photos. This problem usually calls for appreciable time and assets as customers embark on an iterative journey of experimentation to find the prompts that align with their visions.
Retrieval Augmented Technology (RAG) is a course of wherein a language mannequin retrieves contextual paperwork from an exterior information supply and makes use of this data to generate extra correct and informative textual content. This method is especially helpful for knowledge-intensive pure language processing (NLP) duties. We now lengthen its transformative contact to the world of text-to-image technology. On this put up, we display methods to harness the facility of RAG to boost the prompts despatched to your Steady Diffusion fashions. You’ll be able to create your individual AI assistant for immediate technology in minutes with giant language fashions (LLMs) on Amazon Bedrock, in addition to on SageMaker JumpStart.
Approaches to crafting text-to-image prompts
Making a immediate for a text-to-image mannequin could seem simple at first look, however it’s a deceptively complicated process. It’s extra than simply typing a number of phrases and anticipating the mannequin to conjure a picture that aligns together with your psychological picture. Efficient prompts ought to present clear directions whereas leaving room for creativity. They have to steadiness specificity and ambiguity, and they need to be tailor-made to the actual mannequin getting used. To handle the problem of immediate engineering, the trade has explored varied approaches:
- Immediate libraries – Some firms curate libraries of pre-written prompts you can entry and customise. These libraries include a variety of prompts tailor-made to numerous use instances, permitting you to decide on or adapt prompts that align together with your particular wants.
- Immediate templates and pointers – Many firms and organizations present customers with a set of predefined immediate templates and pointers. These templates supply structured codecs for writing prompts, making it simple to craft efficient directions.
- Neighborhood and consumer contributions – Crowdsourced platforms and consumer communities usually play a big function in bettering prompts. Customers can share their fine-tuned fashions, profitable prompts, ideas, and finest practices with the neighborhood, serving to others be taught and refine their prompt-writing abilities.
- Mannequin fine-tuning – Corporations might fine-tune their text-to-image fashions to raised perceive and reply to particular varieties of prompts. Effective-tuning can enhance mannequin efficiency for explicit domains or use instances.
These trade approaches collectively purpose to make the method of crafting efficient text-to-image prompts extra accessible, user-friendly, and environment friendly, finally enhancing the usability and flexibility of text-to-image technology fashions for a variety of functions.
Utilizing RAG for immediate design
On this part, we delve into how RAG strategies can function a recreation changer in immediate engineering, working in concord with these current approaches. By seamlessly integrating RAG into the method, we are able to streamline and improve the effectivity of immediate design.
Semantic search in a immediate database
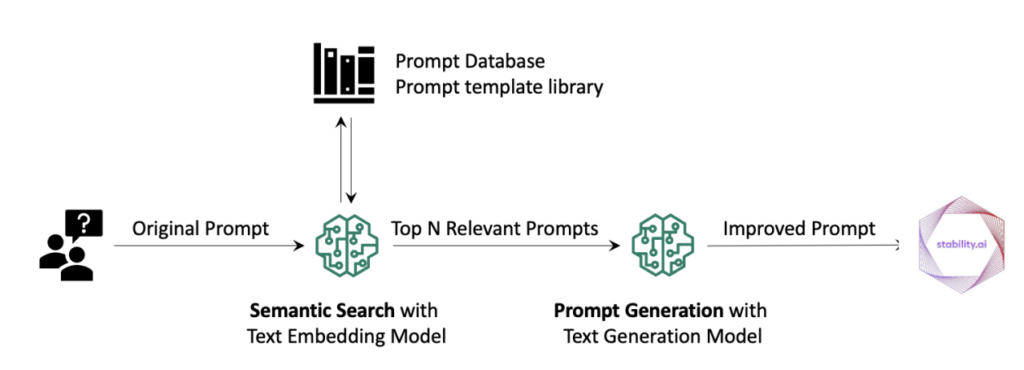
Think about an organization that has accrued an unlimited repository of prompts in its immediate library or has created numerous immediate templates, every designed for particular use instances and goals. Historically, customers searching for inspiration for his or her text-to-image prompts would manually flick thru these libraries, usually sifting by in depth lists of choices. This course of may be time-consuming and inefficient. By embedding prompts from the immediate library utilizing textual content embedding fashions, firms can construct a semantic search engine. Right here’s the way it works:
- Embedding prompts – The corporate makes use of textual content embeddings to transform every immediate in its library right into a numerical illustration. These embeddings seize the semantic which means and context of the prompts.
- Consumer question – When customers present their very own prompts or describe their desired picture, the system can analyze and embed their enter as nicely.
- Semantic search – Utilizing the embeddings, the system performs a semantic search. It retrieves probably the most related prompts from the library primarily based on the consumer’s question, contemplating each the consumer’s enter and historic information within the immediate library.
By implementing semantic search of their immediate libraries, firms empower their staff to entry an unlimited reservoir of prompts effortlessly. This method not solely accelerates immediate creation but in addition encourages creativity and consistency in text-to-image technology.y

Immediate technology from semantic search
Though semantic search streamlines the method of discovering related prompts, RAG takes it a step additional by utilizing these search outcomes to generate optimized prompts. Right here’s the way it works:
- Semantic search outcomes – After retrieving probably the most related prompts from the library, the system presents these prompts to the consumer, alongside the consumer’s unique enter.
- Textual content technology mannequin – The consumer can choose a immediate from the search outcomes or present additional context on their preferences. The system feeds each the chosen immediate and the consumer’s enter into an LLM.
- Optimized immediate – The LLM, with its understanding of language nuances, crafts an optimized immediate that mixes parts from the chosen immediate and the consumer’s enter. This new immediate is tailor-made to the consumer’s necessities and is designed to yield the specified picture output.
The mixture of semantic search and immediate technology not solely simplifies the method of discovering prompts but in addition ensures that the prompts generated are extremely related and efficient. It empowers you to fine-tune and customise your prompts, finally resulting in improved text-to-image technology outcomes. The next are examples of photos generated from Steady Diffusion XL utilizing the prompts from semantic search and immediate technology.
| Authentic Immediate | Prompts from Semantic Search | Optimized Immediate by LLM |
|
a cartoon of a bit of canine
|
|
A cartoon scene of a boy fortunately strolling hand in hand down a forest lane along with his cute pet canine, in animation type.
|


RAG-based immediate design functions throughout various industries
Earlier than we discover the appliance of our urged RAG structure, let’s begin with an trade wherein a picture technology mannequin is most relevant. In AdTech, pace and creativity are important. RAG-based immediate technology can add on the spot worth by producing immediate ideas to create many photos rapidly for an commercial marketing campaign. Human decision-makers can undergo the auto-generated photos to pick out the candidate picture for the marketing campaign. This characteristic generally is a standalone software or embedded into in style software program instruments and platforms at the moment obtainable.
One other trade the place the Steady Diffusion mannequin can improve productiveness is media and leisure. The RAG structure can help in use instances of avatar creation, for instance. Ranging from a easy immediate, RAG can add rather more colour and traits to the avatar concepts. It could generate many candidate prompts and supply extra inventive concepts. From these generated photos, yow will discover the right match for the given software. It will increase the productiveness by mechanically producing many immediate ideas. The variation it might give you is the rapid advantage of the answer.
Answer overview
Empowering clients to assemble their very own RAG-based AI assistant for immediate design on AWS is a testomony to the flexibility of contemporary know-how. AWS offers a plethora of choices and providers to facilitate this endeavor. The next reference structure diagram illustrates a RAG software for immediate design on AWS.

Relating to deciding on the precise LLMs in your AI assistant, AWS presents a spectrum of selections to cater to your particular necessities.
Firstly, you possibly can go for LLMs obtainable by SageMaker JumpStart, using devoted situations. These situations assist a wide range of fashions, together with Falcon, Llama 2, Bloom Z, and Flan-T5, or you possibly can discover proprietary fashions similar to Cohere’s Command and Multilingual Embedding, or Jurassic-2 from AI21 Labs.
When you choose a extra simplified method, AWS presents LLMs on Amazon Bedrock, that includes fashions like Amazon Titan and Anthropic Claude. These fashions are simply accessible by simple API calls, permitting you to harness their energy effortlessly. The flexibleness and variety of choices guarantee that you’ve the liberty to decide on the LLM that finest aligns together with your immediate design targets, whether or not you’re searching for an innovation with open containers or the strong capabilities of proprietary fashions.
Relating to constructing the important vector database, AWS offers a large number of choices by their native providers. You’ll be able to go for Amazon OpenSearch Service, Amazon Aurora, or Amazon Relational Database Service (Amazon RDS) for PostgreSQL, every providing strong options to fit your particular wants. Alternatively, you possibly can discover merchandise from AWS companions like Pinecone, Weaviate, Elastic, Milvus, or Chroma, which give specialised options for environment friendly vector storage and retrieval.
That will help you get began to assemble a RAG-based AI assistant for immediate design, we’ve put collectively a complete demonstration in our GitHub repository. This demonstration makes use of the next assets:
- Picture technology: Steady Diffusion XL on Amazon Bedrock
- Textual content embedding: Amazon Titan on Amazon Bedrock
- Textual content technology: Claude 2 on Amazon Bedrock
- Vector database: FAISS, an open supply library for environment friendly similarity search
- Immediate library: Immediate examples from DiffusionDB, the primary large-scale immediate gallery dataset for text-to-image generative fashions
Moreover, we’ve integrated LangChain for LLM implementation and Streamit for the net software part, offering a seamless and user-friendly expertise.
Stipulations
You might want to have the next to run this demo software:
- An AWS account
- Primary understanding of methods to navigate Amazon SageMaker Studio
- Primary understanding of methods to obtain a repo from GitHub
- Primary information of operating a command on a terminal
Run the demo software
You’ll be able to obtain all the mandatory code with directions from the GitHub repo. After the appliance is deployed, you will note a web page like the next screenshot.

With this demonstration, we purpose to make the implementation course of accessible and understandable, offering you with a hands-on expertise to kickstart your journey into the world of RAG and immediate design on AWS.
Clear up
After you check out the app, clear up your assets by stopping the appliance.
Conclusion
RAG has emerged as a game-changing paradigm on the planet of immediate design, revitalizing Steady Diffusion’s text-to-image capabilities. By harmonizing RAG strategies with current approaches and utilizing the strong assets of AWS, we’ve uncovered a pathway to streamlined creativity and accelerated studying.
For added assets, go to the next:
In regards to the authors
 James Yi is a Senior AI/ML Companion Options Architect within the Rising Applied sciences crew at Amazon Net Companies. He’s obsessed with working with enterprise clients and companions to design, deploy and scale AI/ML functions to derive their enterprise values. Outdoors of labor, he enjoys taking part in soccer, touring and spending time along with his household.
James Yi is a Senior AI/ML Companion Options Architect within the Rising Applied sciences crew at Amazon Net Companies. He’s obsessed with working with enterprise clients and companions to design, deploy and scale AI/ML functions to derive their enterprise values. Outdoors of labor, he enjoys taking part in soccer, touring and spending time along with his household.
 Rumi Olsen is a Options Architect within the AWS Companion Program. She makes a speciality of serverless and machine studying options in her present function, and has a background in pure language processing applied sciences. She spends most of her spare time along with her daughter exploring the character of Pacific Northwest.
Rumi Olsen is a Options Architect within the AWS Companion Program. She makes a speciality of serverless and machine studying options in her present function, and has a background in pure language processing applied sciences. She spends most of her spare time along with her daughter exploring the character of Pacific Northwest.





