Evaluating RAG Purposes with RAGAs | by Leonie Monigatti | Dec, 2023
RAGAs (Retrieval-Augmented Generation Assessment) is a framework (GitHub, Docs) that gives you with the mandatory elements that will help you consider your RAG pipeline on a element stage.
Analysis Knowledge
What’s fascinating about RAGAs is that it began out as a framework for “reference-free” analysis [1]. Which means, as an alternative of getting to depend on human-annotated floor reality labels within the analysis dataset, RAGAs leverages LLMs beneath the hood to conduct the evaluations.
To judge the RAG pipeline, RAGAs expects the next info:
query: The consumer question that’s the enter of the RAG pipeline. The enter.reply: The generated reply from the RAG pipeline. The output.contexts: The contexts retrieved from the exterior data supply used to reply thequery.ground_truths: The bottom reality reply to thequery. That is the one human-annotated info. This info is barely required for the metriccontext_recall(see Evaluation Metrics).
Leveraging LLMs for reference-free analysis is an lively analysis matter. Whereas utilizing as little human-annotated information as attainable makes it a less expensive and quicker analysis technique, there’s nonetheless some dialogue about its shortcomings, akin to bias [3]. Nonetheless, some papers have already proven promising outcomes [4]. For detailed info, see the “Associated Work” part of the RAGAs [1] paper.
Word that the framework has expanded to supply metrics and paradigms that require floor reality labels (e.g., context_recall and answer_correctness, see Evaluation Metrics).
Moreover, the framework gives you with tooling for automatic test data generation.
Analysis Metrics
RAGAs give you a number of metrics to guage a RAG pipeline component-wise in addition to end-to-end.
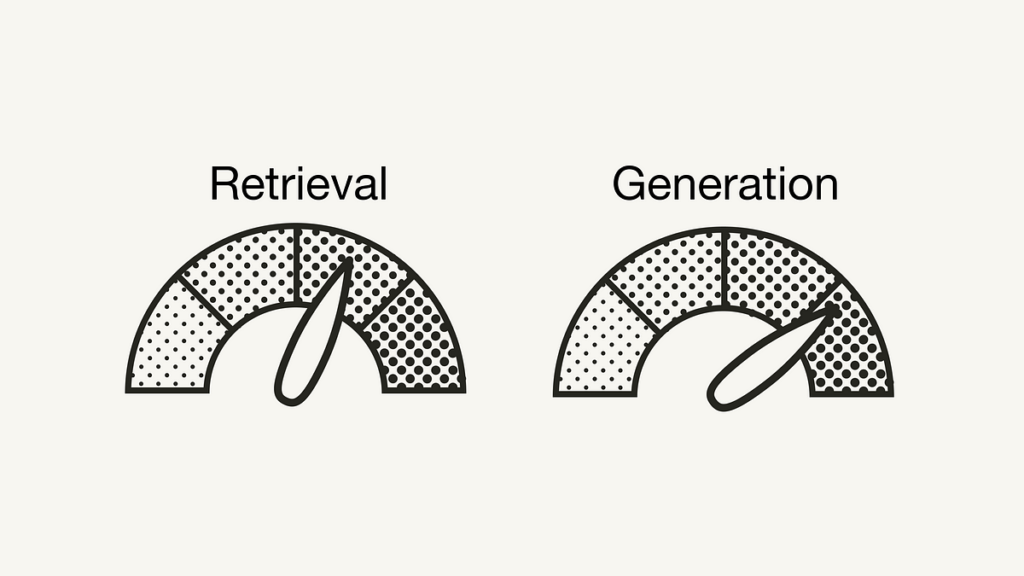
On a element stage, RAGAs gives you with metrics to guage the retrieval element (context_relevancy and context_recall) and the generative element (faithfulness and answer_relevancy) individually [2]:
- Context precision measures the signal-to-noise ratio of the retrieved context. This metric is computed utilizing the
queryand thecontexts. - Context recall measures if all of the related info required to reply the query was retrieved. This metric is computed based mostly on the
ground_truth(that is the one metric within the framework that depends on human-annotated floor reality labels) and thecontexts. - Faithfulness measures the factual accuracy of the generated reply. The variety of appropriate statements from the given contexts is split by the overall variety of statements within the generated reply. This metric makes use of the
query,contextsand thereply. - Answer relevancy measures how related the generated reply is to the query. This metric is computed utilizing the
queryand thereply. For instance, the reply “France is in western Europe.” to the query “The place is France and what’s it’s capital?” would obtain a low reply relevancy as a result of it solely solutions half of the query.
All metrics are scaled to the vary [0, 1], with larger values indicating a greater efficiency.
RAGAs additionally gives you with metrics to guage the RAG pipeline end-to-end, akin to answer semantic similarity and answer correctness. This text focuses on the component-level metrics.
This part makes use of RAGAs to guage a minimal vanilla RAG pipeline to indicate you use RAGAs and to present you an instinct about its analysis metrics.
Stipulations
Be sure to have put in the required Python packages:
langchain,openai, andweaviate-clientfor the RAG pipelineragasfor evaluating the RAG pipeline
#!pip set up langchain openai weaviate-client ragas
Moreover, outline your related atmosphere variables in a .env file in your root listing. To acquire an OpenAI API Key, you want an OpenAI account after which “Create new secret key” beneath API keys.
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
Organising the RAG software
Earlier than you’ll be able to consider your RAG software, you’ll want to set it up. We are going to use a vanilla RAG pipeline. We are going to hold this part quick since we’ll use the identical setup described intimately within the following article.
First, you will need to put together the information by loading and chunking the paperwork.
import requests
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitterurl = "https://uncooked.githubusercontent.com/langchain-ai/langchain/grasp/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.textual content)
# Load the information
loader = TextLoader('./state_of_the_union.txt')
paperwork = loader.load()
# Chunk the information
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(paperwork)
Subsequent, generate the vector embeddings for every chunk with the OpenAI embedding mannequin and retailer them within the vector database.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
from dotenv import load_dotenv,find_dotenv# Load OpenAI API key from .env file
load_dotenv(find_dotenv())
# Setup vector database
consumer = weaviate.Shopper(
embedded_options = EmbeddedOptions()
)
# Populate vector database
vectorstore = Weaviate.from_documents(
consumer = consumer,
paperwork = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
# Outline vectorstore as retriever to allow semantic search
retriever = vectorstore.as_retriever()
Lastly, arrange a immediate template and the OpenAI LLM and mix them with the retriever element to a RAG pipeline.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser# Outline LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Outline immediate template
template = """You might be an assistant for question-answering duties.
Use the next items of retrieved context to reply the query.
If you do not know the reply, simply say that you do not know.
Use two sentences most and hold the reply concise.
Query: {query}
Context: {context}
Reply:
"""
immediate = ChatPromptTemplate.from_template(template)
# Setup RAG pipeline
rag_chain = (
{"context": retriever, "query": RunnablePassthrough()}
| immediate
| llm
| StrOutputParser()
)
Getting ready the Analysis Knowledge
As RAGAs goals to be a reference-free analysis framework, the required preparations of the analysis dataset are minimal. You will want to organize query and ground_truths pairs from which you’ll be able to put together the remaining info by inference as follows:
from datasets import Datasetquestions = ["What did the president say about Justice Breyer?",
"What did the president say about Intel's CEO?",
"What did the president say about gun violence?",
]
ground_truths = [["The president said that Justice Breyer has dedicated his life to serve the country and thanked him for his service."],
["The president said that Pat Gelsinger is ready to increase Intel's investment to $100 billion."],
["The president asked Congress to pass proven measures to reduce gun violence."]]
solutions = []
contexts = []
# Inference
for question in questions:
solutions.append(rag_chain.invoke(question))
contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])
# To dict
information = {
"query": questions,
"reply": solutions,
"contexts": contexts,
"ground_truths": ground_truths
}
# Convert dict to dataset
dataset = Dataset.from_dict(information)
In case you are not within the context_recall metric, you don’t want to supply the ground_truths info. On this case, all you’ll want to put together are the querys.
Evaluating the RAG software
First, import all of the metrics you need to use from ragas.metrics. Then, you should use the consider() perform and easily cross within the related metrics and the ready dataset.
from ragas import consider
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)consequence = consider(
dataset = dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
)
df = consequence.to_pandas()
Under, you’ll be able to see the ensuing RAGAs scores for the examples: