Sparsity-preserving differentially personal coaching – Google Analysis Weblog

Massive embedding fashions have emerged as a basic software for varied functions in advice programs [1, 2] and pure language processing [3, 4, 5]. Such fashions allow the combination of non-numerical information into deep studying fashions by mapping categorical or string-valued enter attributes with massive vocabularies to fixed-length illustration vectors utilizing embedding layers. These fashions are extensively deployed in customized advice programs and obtain state-of-the-art efficiency in language duties, reminiscent of language modeling, sentiment analysis, and question answering. In lots of such eventualities, privateness is an equally necessary characteristic when deploying these fashions. In consequence, varied strategies have been proposed to allow personal information evaluation. Amongst these, differential privacy (DP) is a extensively adopted definition that limits publicity of particular person consumer data whereas nonetheless permitting for the evaluation of population-level patterns.
For coaching deep neural networks with DP ensures, essentially the most extensively used algorithm is DP-SGD (DP stochastic gradient descent). One key element of DP-SGD is including Gaussian noise to each coordinate of the gradient vectors throughout coaching. Nevertheless, this creates scalability challenges when utilized to massive embedding fashions, as a result of they depend on gradient sparsity for environment friendly coaching, however including noise to all of the coordinates destroys sparsity.
To mitigate this gradient sparsity downside, in “Sparsity-Preserving Differentially Private Training of Large Embedding Models” (to be offered at NeurIPS 2023), we suggest a brand new algorithm known as adaptive filtering-enabled sparse coaching (DP-AdaFEST). At a excessive stage, the algorithm maintains the sparsity of the gradient by deciding on solely a subset of characteristic rows to which noise is added at every iteration. The secret is to make such choices differentially personal so {that a} three-way steadiness is achieved among the many privateness price, the coaching effectivity, and the mannequin utility. Our empirical analysis exhibits that DP-AdaFEST achieves a considerably sparser gradient, with a discount in gradient dimension of over 105X in comparison with the dense gradient produced by normal DP-SGD, whereas sustaining comparable ranges of accuracy. This gradient dimension discount might translate into 20X wall-clock time enchancment.
Overview
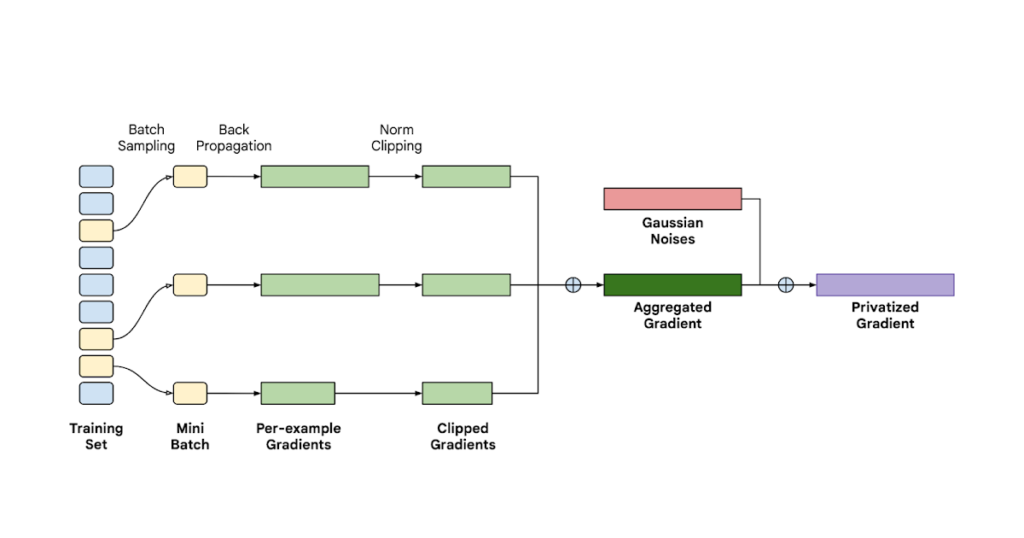
To higher perceive the challenges and our options to the gradient sparsity downside, allow us to begin with an outline of how DP-SGD works throughout coaching. As illustrated by the determine beneath, DP-SGD operates by clipping the gradient contribution from every instance within the present random subset of samples (known as a mini-batch), and including coordinate-wise Gaussian noise to the typical gradient throughout every iteration of stochastic gradient descent (SGD). DP-SGD has demonstrated its effectiveness in defending consumer privateness whereas sustaining mannequin utility in quite a lot of functions [6, 7].
 |
| An illustration of how DP-SGD works. Throughout every coaching step, a mini-batch of examples is sampled, and used to compute the per-example gradients. These gradients are processed by clipping, aggregation and summation of Gaussian noise to provide the ultimate privatized gradients. |
The challenges of making use of DP-SGD to massive embedding fashions primarily come from 1) the non-numerical characteristic fields like consumer/product IDs and classes, and a pair of) phrases and tokens which can be reworked into dense vectors by an embedding layer. As a result of vocabulary sizes of these options, the method requires massive embedding tables with a considerable variety of parameters. In distinction to the variety of parameters, the gradient updates are normally extraordinarily sparse as a result of every mini-batch of examples solely prompts a tiny fraction of embedding rows (the determine beneath visualizes the ratio of zero-valued coordinates, i.e., the sparsity, of the gradients beneath varied batch sizes). This sparsity is closely leveraged for industrial functions that effectively deal with the coaching of large-scale embeddings. For instance, Google Cloud TPUs, custom-designed AI accelerators that are optimized for coaching and inference of enormous AI fashions, have dedicated APIs to deal with massive embeddings with sparse updates. This results in significantly improved training throughput in comparison with coaching on GPUs, which at thisAt a excessive stage, the algorithm maintains the sparsity of the gradient by deciding on solely a subset of characteristic rows to which noise is added at every iteration. time didn’t have specialised optimization for sparse embedding lookups. Then again, DP-SGD utterly destroys the gradient sparsity as a result of it requires including impartial Gaussian noise to all the coordinates. This creates a highway block for personal coaching of enormous embedding fashions because the coaching effectivity could be considerably lowered in comparison with non-private coaching.
 |
| Embedding gradient sparsity (the fraction of zero-value gradient coordinates) within the Criteo pCTR mannequin (see beneath). The determine stories the gradient sparsity, averaged over 50 replace steps, of the highest 5 categorical options (out of a complete of 26) with the very best variety of buckets, in addition to the sparsity of all categorical options. The sprasity decreases with the batch dimension as extra examples hit extra rows within the embedding desk, creating non-zero gradients. Nevertheless, the sparsity is above 0.97 even for very massive batch sizes. This sample is constantly noticed for all of the 5 options. |
Algorithm
Our algorithm is constructed by extending normal DP-SGD with an additional mechanism at every iteration to privately choose the “sizzling options”, that are the options which can be activated by a number of coaching examples within the present mini-batch. As illustrated beneath, the mechanism works in just a few steps:
- Compute what number of examples contributed to every characteristic bucket (we name every of the attainable values of a categorical characteristic a “bucket”).
- Limit the full contribution from every instance by clipping their counts.
- Add Gaussian noise to the contribution depend of every characteristic bucket.
- Choose solely the options to be included within the gradient replace which have a depend above a given threshold (a sparsity-controlling parameter), thus sustaining sparsity. This mechanism is differentially personal, and the privateness price could be simply computed by composing it with the usual DP-SGD iterations.
 |
| Illustration of the method of the algorithm on an artificial categorical characteristic that has 20 buckets. We compute the variety of examples contributing to every bucket, regulate the worth based mostly on per-example complete contributions (together with these to different options), add Gaussian noise, and retain solely these buckets with a loud contribution exceeding the edge for (noisy) gradient replace. |
Theoretical motivation
We offer the theoretical motivation that underlies DP-AdaFEST by viewing it as optimization utilizing stochastic gradient oracles. Customary evaluation of stochastic gradient descent in a theoretical setting decomposes the check error of the mannequin into “bias” and “variance” terms. The benefit of DP-AdaFEST could be seen as lowering variance at the price of barely growing the bias. It’s because DP-AdaFEST provides noise to a smaller set of coordinates in comparison with DP-SGD, which provides noise to all of the coordinates. Then again, DP-AdaFEST introduces some bias to the gradients because the gradient on the embedding options are dropped with some chance. We refer the reader to Part 3.4 of the paper for extra particulars.
Experiments
We consider the effectiveness of our algorithm with massive embedding mannequin functions, on public datasets, together with one advert prediction dataset (Criteo-Kaggle) and one language understanding dataset (SST-2). We use DP-SGD with exponential selection as a baseline comparability.
The effectiveness of DP-AdaFEST is clear within the determine beneath, the place it achieves considerably increased gradient dimension discount (i.e., gradient sparsity) than the baseline whereas sustaining the identical stage of utility (i.e., solely minimal efficiency degradation).
Particularly, on the Criteo-Kaggle dataset, DP-AdaFEST reduces the gradient computation price of standard DP-SGD by greater than 5×105 instances whereas sustaining a comparable AUC (which we outline as a lack of lower than 0.005). This discount interprets right into a extra environment friendly and cost-effective coaching course of. Compared, as proven by the inexperienced line beneath, the baseline technique will not be capable of obtain cheap price discount inside such a small utility loss threshold.
In language duties, there is not as a lot potential for lowering the dimensions of gradients, as a result of the vocabulary used is usually smaller and already fairly compact (proven on the fitting beneath). Nevertheless, the adoption of sparsity-preserving DP-SGD successfully obviates the dense gradient computation. Moreover, according to the bias-variance trade-off offered within the theoretical evaluation, we word that DP-AdaFEST often reveals superior utility in comparison with DP-SGD when the discount in gradient dimension is minimal. Conversely, when incorporating sparsity, the baseline algorithm faces challenges in sustaining utility.
 |
| A comparability of the perfect gradient dimension discount (the ratio of the non-zero gradient worth counts between common DP-SGD and sparsity-preserving algorithms) achieved beneath ε =1.0 by DP-AdaFEST (our algorithm) and the baseline algorithm (DP-SGD with exponential selection) in comparison with DP-SGD at totally different thresholds for utility distinction. A better curve signifies a greater utility/effectivity trade-off. |
In follow, most advert prediction fashions are being constantly educated and evaluated. To simulate this on-line studying setup, we additionally consider with time-series information, that are notoriously difficult on account of being non-stationary. Our analysis makes use of the Criteo-1TB dataset, which includes real-world user-click information collected over 24 days. Persistently, DP-AdaFEST reduces the gradient computation price of standard DP-SGD by greater than 104 instances whereas sustaining a comparable AUC.
 |
| A comparability of the perfect gradient dimension discount achieved beneath ε =1.0 by DP-AdaFEST (our algorithm) and DP-SGD with exponential choice (a earlier algorithm) in comparison with DP-SGD at totally different thresholds for utility distinction. A better curve signifies a greater utility/effectivity trade-off. DP-AdaFEST constantly outperforms the earlier technique. |
Conclusion
We current a brand new algorithm, DP-AdaFEST, for preserving gradient sparsity in differentially personal coaching — significantly in functions involving massive embedding fashions, a basic software for varied functions in advice programs and pure language processing. Our algorithm achieves important reductions in gradient dimension whereas sustaining accuracy on real-world benchmark datasets. Furthermore, it affords versatile choices for balancing utility and effectivity by way of sparsity-controlling parameters, whereas our proposals provide significantly better privacy-utility loss.
Acknowledgements
This work was a collaboration with Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi and Amer Sinha.