Use Amazon SageMaker Studio to construct a RAG query answering resolution with Llama 2, LangChain, and Pinecone for quick experimentation
Retrieval Augmented Technology (RAG) permits you to present a big language mannequin (LLM) with entry to information from exterior information sources equivalent to repositories, databases, and APIs with out the necessity to fine-tune it. When utilizing generative AI for query answering, RAG allows LLMs to reply questions with essentially the most related, up-to-date data and optionally cite their information sources for verification.
A typical RAG resolution for information retrieval from paperwork makes use of an embeddings mannequin to transform the info from the info sources to embeddings and shops these embeddings in a vector database. When a consumer asks a query, it searches the vector database and retrieves paperwork which can be most much like the consumer’s question. Subsequent, it combines the retrieved paperwork and the consumer’s question in an augmented immediate that’s despatched to the LLM for textual content era. There are two fashions on this implementation: the embeddings mannequin and the LLM that generates the ultimate response.
On this submit, we display tips on how to use Amazon SageMaker Studio to construct a RAG query answering resolution.
Utilizing notebooks for RAG-based query answering
Implementing RAG usually entails experimenting with numerous embedding fashions, vector databases, textual content era fashions, and prompts, whereas additionally debugging your code till you obtain a purposeful prototype. Amazon SageMaker affords managed Jupyter notebooks outfitted with GPU cases, enabling you to quickly experiment throughout this preliminary section with out spinning up further infrastructure. There are two choices for utilizing notebooks in SageMaker. The primary choice is quick launch notebooks obtainable by means of SageMaker Studio. In SageMaker Studio, the built-in improvement setting (IDE) purpose-built for ML, you may launch notebooks that run on totally different occasion sorts and with totally different configurations, collaborate with colleagues, and entry further purpose-built options for machine studying (ML). The second choice is utilizing a SageMaker notebook instance, which is a completely managed ML compute occasion operating the Jupyter Pocket book app.
On this submit, we current a RAG resolution that augments the mannequin’s information with further information from exterior information sources to supply extra correct responses particular to a customized area. We use a single SageMaker Studio pocket book operating on an ml.g5.2xlarge occasion (1 A10G GPU) and Llama 2 7b chat hf, the fine-tuned model of Llama 2 7b, which is optimized for dialog use instances from Hugging Face Hub. We use two AWS Media & Leisure Weblog posts because the pattern exterior information, which we convert into embeddings with the BAAI/bge-small-en-v1.5 embeddings. We retailer the embeddings in Pinecone, a vector-based database that provides high-performance search and similarity matching. We additionally talk about tips on how to transition from experimenting within the pocket book to deploying your fashions to SageMaker endpoints for real-time inference once you full your prototyping. The identical strategy can be utilized with totally different fashions and vector databases.
Resolution overview
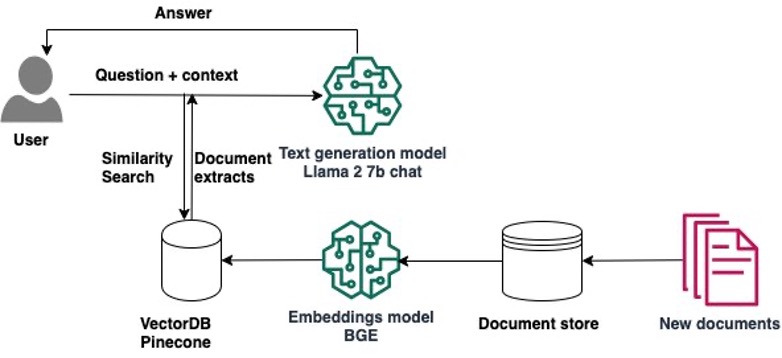
The next diagram illustrates the answer structure.
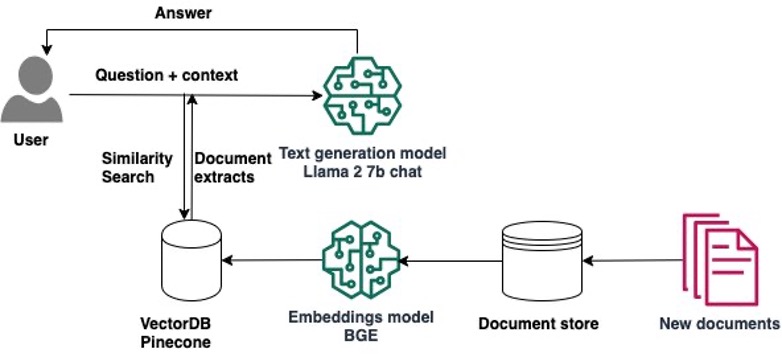
Implementing the answer consists of two high-level steps: creating the answer utilizing SageMaker Studio notebooks, and deploying the fashions for inference.
Develop the answer utilizing SageMaker Studio notebooks
Full the next steps to begin creating the answer:
- Load the Llama-2 7b chat mannequin from Hugging Face Hub within the pocket book.
- Create a PromptTemplate with LangChain and use it to create prompts to your use case.
- For 1–2 instance prompts, add related static textual content from exterior paperwork as immediate context and assess if the standard of the responses improves.
- Assuming that the standard improves, implement the RAG query answering workflow:
- Collect the exterior paperwork that may assist the mannequin higher reply the questions in your use case.
- Load the BGE embeddings mannequin and use it to generate embeddings of those paperwork.
- Retailer these embeddings in a Pinecone index.
- When a consumer asks a query, carry out a similarity search in Pinecone and add the content material from essentially the most comparable paperwork to the immediate’s context.
Deploy the fashions to SageMaker for inference at scale
Whenever you hit your efficiency objectives, you may deploy the fashions to SageMaker for use by generative AI functions:
- Deploy the Llama-2 7b chat mannequin to a SageMaker real-time endpoint.
- Deploy the BAAI/bge-small-en-v1.5 embeddings mannequin to a SageMaker real-time endpoint.
- Use the deployed fashions in your query answering generative AI functions.
Within the following sections, we stroll you thru the steps of implementing this resolution in SageMaker Studio notebooks.
Conditions
To observe the steps on this submit, it’s essential have an AWS account and an AWS Identity and Access Management (IAM) position with permissions to create and entry the answer sources. If you’re new to AWS, see Create a standalone AWS account.
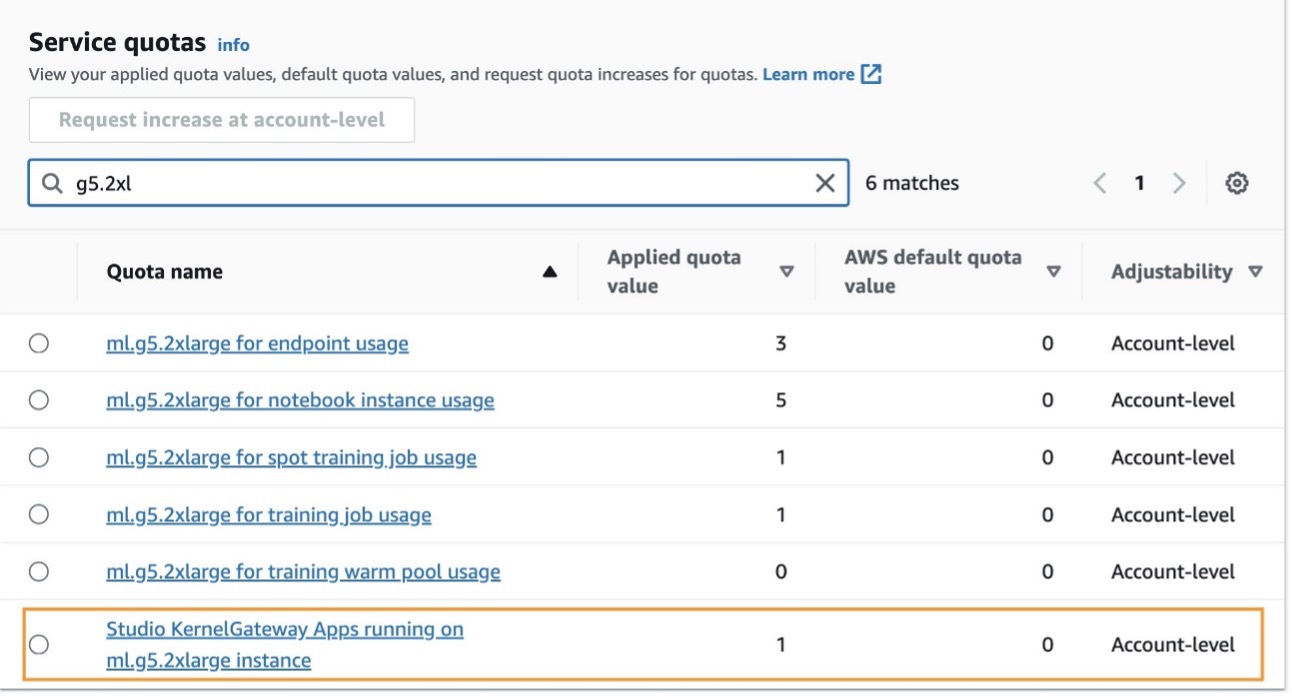
To make use of SageMaker Studio notebooks in your AWS account, you want a SageMaker domain with a consumer profile that has permissions to launch the SageMaker Studio app. If you’re new to SageMaker Studio, the Quick Studio setup is the quickest option to get began. With a single click on, SageMaker provisions the SageMaker area with default presets, together with establishing the consumer profile, IAM position, IAM authentication, and public web entry. The pocket book for this submit assumes an ml.g5.2xlarge occasion sort. To assessment or improve your quota, open the AWS Service Quotas console, select AWS Providers within the navigation pane, select Amazon SageMaker, and seek advice from the worth for Studio KernelGateway apps operating on ml.g5.2xlarge cases.
After confirming your quota restrict, it’s essential full the dependencies to make use of Llama 2 7b chat.
Llama 2 7b chat is offered beneath the Llama 2 license. To entry Llama 2 on Hugging Face, it’s essential full just a few steps first:
- Create a Hugging Face account for those who don’t have one already.
- Full the shape “Request entry to the subsequent model of Llama” on the Meta website.
- Request entry to Llama 2 7b chat on Hugging Face.
After you might have been granted entry, you may create a brand new entry token to entry fashions. To create an entry token, navigate to the Settings web page on the Hugging Face web site.
You might want to have an account with Pinecone to make use of it as a vector database. Pinecone is offered on AWS through the AWS Marketplace. The Pinecone web site additionally affords the choice to create a free account that comes with permissions to create a single index, which is ample for the needs of this submit. To retrieve your Pinecone keys, open the Pinecone console and select API Keys.
Arrange the pocket book and setting
To observe the code on this submit, open SageMaker Studio and clone the next GitHub repository. Subsequent, open the pocket book studio-local-gen-ai/rag/RAG-with-Llama-2-on-Studio.ipynb and select the PyTorch 2.0.0 Python 3.10 GPU Optimized picture, Python 3 kernel, and ml.g5.2xlarge because the occasion sort. If that is your first time utilizing SageMaker Studio notebooks, seek advice from Create or Open an Amazon SageMaker Studio Notebook.
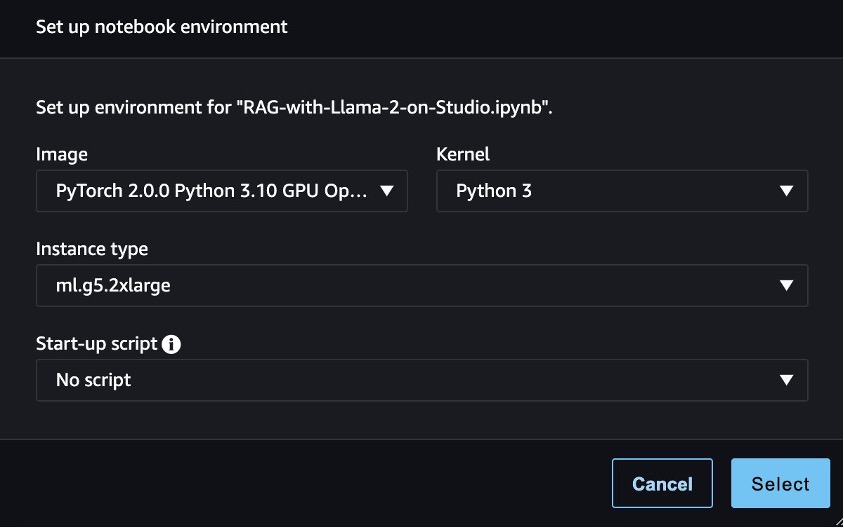
To arrange the event setting, it’s essential set up the required Python libraries, as demonstrated within the following code:
%%writefile necessities.txt
sagemaker>=2.175.0
transformers==4.33.0
speed up==0.21.0
datasets==2.13.0
langchain==0.0.297
pypdf>=3.16.3
pinecone-client
sentence_transformers
safetensors>=0.3.3!pip set up -U -r necessities.txtLoad the pre-trained mannequin and tokenizer
After you might have imported the required libraries, you may load the Llama-2 7b chat mannequin together with its corresponding tokenizers from Hugging Face. These loaded mannequin artifacts are saved within the native listing inside SageMaker Studio. This allows you to swiftly reload them into reminiscence every time it’s essential resume your work at a special time.
import torch
from transformers import (
AutoTokenizer,
LlamaTokenizer,
LlamaForCausalLM,
GenerationConfig,
AutoModelForCausalLM
)
import transformers
tg_model_id = "meta-llama/Llama-2-7b-chat-hf" #the mannequin id in Hugging Face
tg_model_path = f"./tg_model/{tg_model_id}" #the native listing the place the mannequin might be saved
tg_model = AutoModelForCausalLM.from_pretrained(tg_model_id, token=hf_access_token,do_sample=True, use_safetensors=True, device_map="auto", torch_dtype=torch.float16
tg_tokenizer = AutoTokenizer.from_pretrained(tg_model_id, token=hf_access_token)
tg_model.save_pretrained(save_directory=tg_model_path, from_pt=True)
tg_tokenizer.save_pretrained(save_directory=tg_model_path, from_pt=True)Ask a query that requires up-to-date data
Now you can begin utilizing the mannequin and ask questions. Llama-2 chat fashions anticipate the immediate to stick to the next format:
<s>[INST] <<SYS>>
system_prompt
<<SYS>>
{{ user_message }} [/INST]You need to use the PromptTemplate from LangChain to create a recipe primarily based on the immediate format, with the intention to simply create prompts going ahead:
from langchain import PromptTemplate
template = """<s>[INST] <<SYS>>nYou are an assistant for question-answering duties. You might be useful and pleasant. Use the next items of retrieved context to reply the question. If you do not know the reply, you simply say I do not know. Use three sentences most and hold the reply concise.
<<SYS>>n
{context}n
{query} [/INST]
"""
prompt_template = PromptTemplate( template=template, input_variables=['context','question'] )Let’s ask the mannequin a query that wants latest data from 2023. You need to use LangChain and particularly the LLMChain sort of chain and go as parameters the LLM, the immediate template you created earlier, and the query:
query = "When can I go to the AWS M&E Buyer Expertise Middle in New York Metropolis?"
tg_tokenizer.add_special_tokens( {"pad_token": "[PAD]"} )
tg_tokenizer.padding_side = "left"
tg_pipe = transformers.pipeline(process='text-generation', mannequin=tg_model, tokenizer=tg_tokenizer, num_return_sequences=1, eos_token_id=tg_tokenizer.eos_token_id, pad_token_id=tg_tokenizer.eos_token_id, max_new_tokens=400, temperature=0.7)
from langchain.chains import LLMChain
from langchain.llms import HuggingFacePipeline
llm=HuggingFacePipeline(pipeline=tg_pipe, model_kwargs={'temperature':0.7})
llm_chain = LLMChain(llm=llm, immediate=prompt_template)
no_context_response = llm_chain.predict(context="", query=query)
print(no_context_response)We get the next generated reply:
Thanks for reaching out! The AWS M&E Buyer Expertise Middle in New York Metropolis is at present closed for visits because of the COVID-19 pandemic. Nevertheless, you may test their official web site or social media accounts for any updates on when the middle will reopen. Within the meantime, you may discover their digital excursions and sources obtainable on-line.
Enhance the reply by including context to the immediate
The reply we generated just isn’t totally true. Let’s see if we will enhance it by offering some context. You’ll be able to add an extract from the submit AWS announces new M&E Customer Experience Center in New York, which incorporates updates on the subject from 2023:
context = """Media and leisure (M&E) prospects proceed to face challenges in creating extra content material, extra rapidly, and distributing it to extra endpoints than ever earlier than of their quest to thrill viewers globally. Amazon Internet Providers (AWS), together with AWS Companions, have showcased the speedy evolution of M&E options for years at trade occasions just like the Nationwide Affiliation of Broadcasters (NAB) Present and the Worldwide Broadcast Conference (IBC). Till now, AWS for M&E expertise demonstrations have been accessible on this method only a few weeks out of the 12 months. Prospects are extra engaged than ever earlier than; they wish to have increased high quality conversations concerning consumer expertise and media tooling. These conversations are finest supported by having an interconnected resolution structure for reference. Scheduling a go to of the M&E Buyer Expertise Middle might be obtainable beginning November thirteenth, please ship an e mail to AWS-MediaEnt-CXC@amazon.com."""Use the LLMChain once more and go the previous textual content as context:
context_response = llm_chain.predict(context=context, query=query)
print(context_response)The brand new response solutions the query with up-to-date data:
You’ll be able to go to the AWS M&E Buyer Expertise Middle in New York Metropolis ranging from November thirteenth. Please ship an e mail to AWS-MediaEnt-CXC@amazon.com to schedule a go to.
We’ve confirmed that by including the proper context, the mannequin’s efficiency is improved. Now you may focus your efforts on discovering and including the proper context for the query requested. In different phrases, implement RAG.
Implement RAG query answering with BGE embeddings and Pinecone
At this juncture, it’s essential to resolve on the sources of data to reinforce the mannequin’s information. These sources might be inner webpages or paperwork inside your group, or publicly obtainable information sources. For the needs of this submit and for the sake of simplicity, now we have chosen two AWS Weblog posts printed in 2023:
These posts are already obtainable as PDF paperwork within the information undertaking listing in SageMaker Studio for fast entry. To divide the paperwork into manageable chunks, you may make use of the RecursiveCharacterTextSplitter methodology from LangChain:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader("./information/")
paperwork = loader.load()
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=5
)
docs = text_splitter.split_documents(paperwork)Subsequent, use the BGE embeddings mannequin bge-small-en created by the Beijing Academy of Artificial Intelligence (BAAI) that’s obtainable on Hugging Face to generate the embeddings of those chunks. Obtain and save the mannequin within the native listing in Studio. We use fp32 in order that it may well run on the occasion’s CPU.
em_model_name = "BAAI/bge-small-en"
em_model_path = f"./em-model"
from transformers import AutoModel
# Load mannequin from HuggingFace Hub
em_model = AutoModel.from_pretrained(em_model_name,torch_dtype=torch.float32)
em_tokenizer = AutoTokenizer.from_pretrained(em_model_name,gadget="cuda")
# save mannequin to disk
em_tokenizer.save_pretrained(save_directory=f"{em_model_path}/mannequin",from_pt=True)
em_model.save_pretrained(save_directory=f"{em_model_path}/mannequin",from_pt=True)
em_model.eval()Use the next code to create an embedding_generator perform, which takes the doc chunks as enter and generates the embeddings utilizing the BGE mannequin:
# Tokenize sentences
def tokenize_text(_input, gadget):
return em_tokenizer(
[_input],
padding=True,
truncation=True,
return_tensors="pt"
).to(gadget)
# Run embedding process as a perform with mannequin and textual content sentences as enter
def embedding_generator(_input, normalize=True):
# Compute token embeddings
with torch.no_grad():
embedded_output = em_model(
**tokenize_text(
_input,
em_model.gadget
)
)
sentence_embeddings = embedded_output[0][:, 0]
# normalize embeddings
if normalize:
sentence_embeddings = torch.nn.purposeful.normalize(
sentence_embeddings,
p=2,
dim=1
)
return sentence_embeddings[0, :].tolist()
sample_sentence_embedding = embedding_generator(docs[0].page_content)
print(f"Embedding dimension of the doc --->", len(sample_sentence_embedding))On this submit, we display a RAG workflow utilizing Pinecone, a managed, cloud-native vector database that additionally affords an API for similarity search. You might be free to rewrite the next code to make use of your most well-liked vector database.
We initialize a Pinecone python client and create a brand new vector search index utilizing the embedding mannequin’s output size. We use LangChain’s built-in Pinecone class to ingest the embeddings we created within the earlier step. It wants three parameters: the paperwork to ingest, the embeddings generator perform, and the title of the Pinecone index.
import pinecone
pinecone.init(
api_key = os.environ["PINECONE_API_KEY"],
setting = os.environ["PINECONE_ENV"]
)
#test if index already exists, if not we create it
index_name = "rag-index"
if index_name not in pinecone.list_indexes():
pinecone.create_index(
title=index_name,
dimension=len(sample_sentence_embedding), ## 384 for bge-small-en
metric="cosine"
)
#insert the embeddings
from langchain.vectorstores import Pinecone
vector_store = Pinecone.from_documents(
docs,
embedding_generator,
index_name=index_name
)With the Llama-2 7B chat mannequin loaded into reminiscence and the embeddings built-in into the Pinecone index, now you can mix these components to reinforce Llama 2’s responses for our question-answering use case. To realize this, you may make use of the LangChain RetrievalQA, which augments the preliminary immediate with essentially the most comparable paperwork from the vector retailer. By setting return_source_documents=True, you achieve visibility into the precise paperwork used to generate the reply as a part of the response, permitting you to confirm the accuracy of the reply.
from langchain.chains import RetrievalQA
import textwrap
#helper methodology to enhance the readability of the response
def print_response(llm_response):
temp = [textwrap.fill(line, width=100) for line in llm_response['result'].break up('n')]
response="n".be a part of(temp)
print(f"{llm_response['query']}n n{response}'n n Supply Paperwork:")
for supply in llm_response["source_documents"]:
print(supply.metadata)
llm_qa_chain = RetrievalQA.from_chain_type(
llm=llm, #the Llama-2 7b chat mannequin
chain_type="stuff",
retriever=vector_store.as_retriever(search_kwargs={"ok": 2}), # carry out similarity search in Pinecone
return_source_documents=True, #present the paperwork that have been used to reply the query
chain_type_kwargs={"immediate": prompt_template}
)
print_response(llm_qa_chain(query))We get the next reply:
Q: When can I go to the AWS M&E Buyer Expertise Middle in New York Metropolis?
A: I’m blissful to assist! In keeping with the context, the AWS M&E Buyer Expertise Middle in New York Metropolis might be obtainable for visits beginning on November thirteenth. You’ll be able to ship an e mail to AWS-MediaEnt-CXC@amazon.com to schedule a go to.’
Supply Paperwork:
{‘web page’: 4.0, ‘supply’: ‘information/AWS proclaims new M&E Buyer Expertise Middle in New York Metropolis _ AWS for M&E Weblog.pdf’}
{‘web page’: 2.0, ‘supply’: ‘information/AWS proclaims new M&E Buyer Expertise Middle in New York Metropolis _ AWS for M&E Weblog.pdf’}
Let’s strive a special query:
question2=" What number of awards have AWS Media Providers gained in 2023?"
print_response(llm_qa_chain(question2))We get the next reply:
Q: What number of awards have AWS Media Providers gained in 2023?
A: In keeping with the weblog submit, AWS Media Providers have gained 5 trade awards in 2023.’
Supply Paperwork:
{‘web page’: 0.0, ‘supply’: ‘information/AWS Media Providers awarded trade accolades _ AWS for M&E Weblog.pdf’}
{‘web page’: 1.0, ‘supply’: ‘information/AWS Media Providers awarded trade accolades _ AWS for M&E Weblog.pdf’}
After you might have established a ample stage of confidence, you may deploy the fashions to SageMaker endpoints for real-time inference. These endpoints are totally managed and supply assist for auto scaling.
SageMaker affords giant mannequin inference utilizing Massive Mannequin Inference containers (LMIs), which we will make the most of to deploy our fashions. These containers come outfitted with pre-installed open supply libraries like DeepSpeed, facilitating the implementation of performance-enhancing strategies equivalent to tensor parallelism throughout inference. Moreover, they use DJLServing as a pre-built built-in mannequin server. DJLServing is a high-performance, common model-serving resolution that provides assist for dynamic batching and employee auto scaling, thereby rising throughput.
In our strategy, we use the SageMaker LMI with DJLServing and DeepSpeed Inference to deploy the Llama-2-chat 7b and BGE fashions to SageMaker endpoints operating on ml.g5.2xlarge cases, enabling real-time inference. If you wish to observe these steps your self, seek advice from the accompanying notebook for detailed directions.
You’ll require two ml.g5.2xlarge cases for deployment. To assessment or improve your quota, open the AWS Service Quotas console, select AWS Providers within the navigation pane, select Amazon SageMaker, and seek advice from the worth for ml.g5.2xlarge for endpoint utilization.
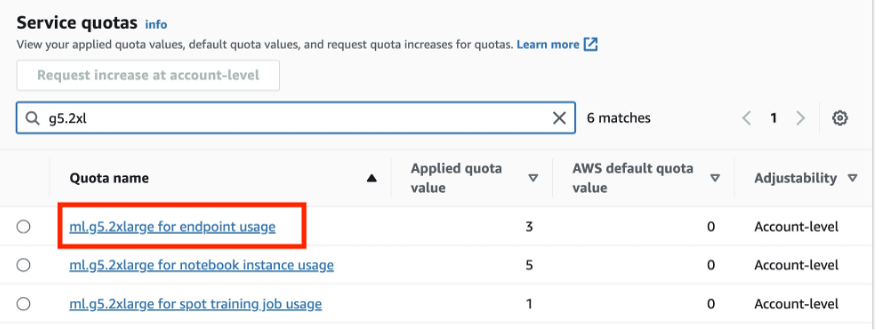
The next steps define the method of deploying customized fashions for the RAG workflow on a SageMaker endpoint:
- Deploy the Llama-2 7b chat mannequin to a SageMaker real-time endpoint operating on an
ml.g5.2xlargeoccasion for quick textual content era. - Deploy the BAAI/bge-small-en-v1.5 embeddings mannequin to a SageMaker real-time endpoint operating on an
ml.g5.2xlargeoccasion. Alternatively, you may deploy your personal embedding mannequin. - Ask a query and use the LangChain RetrievalQA to enhance the immediate with essentially the most comparable paperwork from Pinecone, this time utilizing the mannequin deployed within the SageMaker real-time endpoint:
# convert your native LLM into SageMaker endpoint LLM
llm_sm_ep = SagemakerEndpoint(
endpoint_name=tg_sm_model.endpoint_name, # <--- Your text-gen mannequin endpoint title
region_name=area,
model_kwargs={
"temperature": 0.05,
"max_new_tokens": 512
},
content_handler=content_handler,
)
llm_qa_smep_chain = RetrievalQA.from_chain_type(
llm=llm_sm_ep, # <--- This makes use of SageMaker Endpoint mannequin for inference
chain_type="stuff",
retriever=vector_store.as_retriever(search_kwargs={"ok": 2}),
return_source_documents=True,
chain_type_kwargs={"immediate": prompt_template}
)- Use LangChain to confirm that the SageMaker endpoint with the embedding mannequin works as anticipated in order that it may be used for future doc ingestion:
response_model = smr_client.invoke_endpoint(
EndpointName=em_sm_model.endpoint_name, <--- Your embedding mannequin endpoint title
Physique=json.dumps({
"textual content": "It is a pattern textual content"
}),
ContentType="software/json",
)
outputs = json.hundreds(response_model["Body"].learn().decode("utf8"))['outputs']Clear up
Full the next steps to scrub up your sources:
- When you might have completed working in your SageMaker Studio pocket book, be sure to shut down the
ml.g5.2xlargeoccasion to keep away from any costs by selecting the cease icon. You may also arrange lifecycle configuration scripts to robotically shut down sources when they don’t seem to be used.
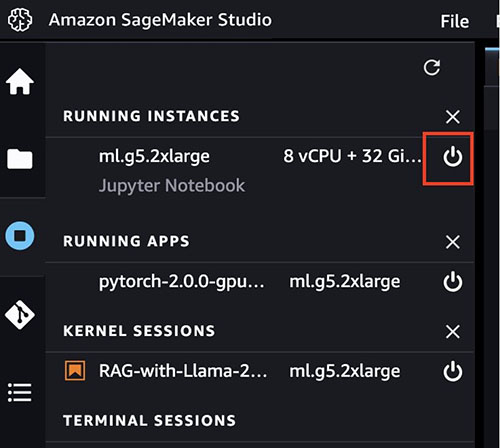
- In case you deployed the fashions to SageMaker endpoints, run the next code on the finish of the pocket book to delete the endpoints:
#delete your textual content era endpoint
sm_client.delete_endpoint(
EndpointName=tg_sm_model.endpoint_name
)
# delete your textual content embedding endpoint
sm_client.delete_endpoint(
EndpointName=em_sm_model.endpoint_name
)- Lastly, run the next line to delete the Pinecone index:
pinecone.delete_index(index_name)Conclusion
SageMaker notebooks present an easy option to kickstart your journey with Retrieval Augmented Technology. They can help you experiment interactively with numerous fashions, configurations, and questions with out spinning up further infrastructure. On this submit, we confirmed tips on how to improve the efficiency of Llama 2 7b chat in a query answering use case utilizing LangChain, the BGE embeddings mannequin, and Pinecone. To get began, launch SageMaker Studio and run the notebook obtainable within the following GitHub repo. Please share your ideas within the feedback part!
Concerning the authors
 Anastasia Tzeveleka is a Machine Studying and AI Specialist Options Architect at AWS. She works with prospects in EMEA and helps them architect machine studying options at scale utilizing AWS providers. She has labored on tasks in several domains together with Pure Language Processing (NLP), MLOps and Low Code No Code instruments.
Anastasia Tzeveleka is a Machine Studying and AI Specialist Options Architect at AWS. She works with prospects in EMEA and helps them architect machine studying options at scale utilizing AWS providers. She has labored on tasks in several domains together with Pure Language Processing (NLP), MLOps and Low Code No Code instruments.
 Pranav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, prepare, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor trade creating giant laptop imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes. In his free time, he enjoys enjoying chess and touring.
Pranav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to prospects construct, prepare, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor trade creating giant laptop imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes. In his free time, he enjoys enjoying chess and touring.





