Meet SPHINX: A Versatile Multi-Modal Massive Language Mannequin (MLLM) with a Mixer of Coaching Duties, Knowledge Domains, and Visible Embeddings
In multi-modal language fashions, a urgent problem has emerged – the inherent limitations of current fashions in grappling with nuanced visible directions and executing a myriad of various duties seamlessly. The crux of the matter lies within the quest for fashions that transcend conventional boundaries, able to comprehending advanced visible queries and executing a large spectrum of duties starting from referring expression comprehension to intricate feats like human pose estimation and nuanced object detection.
Inside the present vision-language understanding, prevailing strategies usually need assistance to attain sturdy efficiency throughout varied duties. Enter the SPHINX, an modern resolution a devoted analysis staff conceived to deal with the prevailing limitations. This multi-modal massive language mannequin (MLLM) leaps ahead by adopting a novel threefold mixing technique. Departing from typical approaches, SPHINX seamlessly integrates mannequin weights from pre-trained massive language fashions, engages in various tuning duties with a considered mix of each real-world and artificial knowledge, and fuses visible embeddings from disparate imaginative and prescient backbones. This amalgamation positions SPHINX as an unprecedented mannequin, poised to excel throughout a broad spectrum of vision-language duties which have proved difficult.
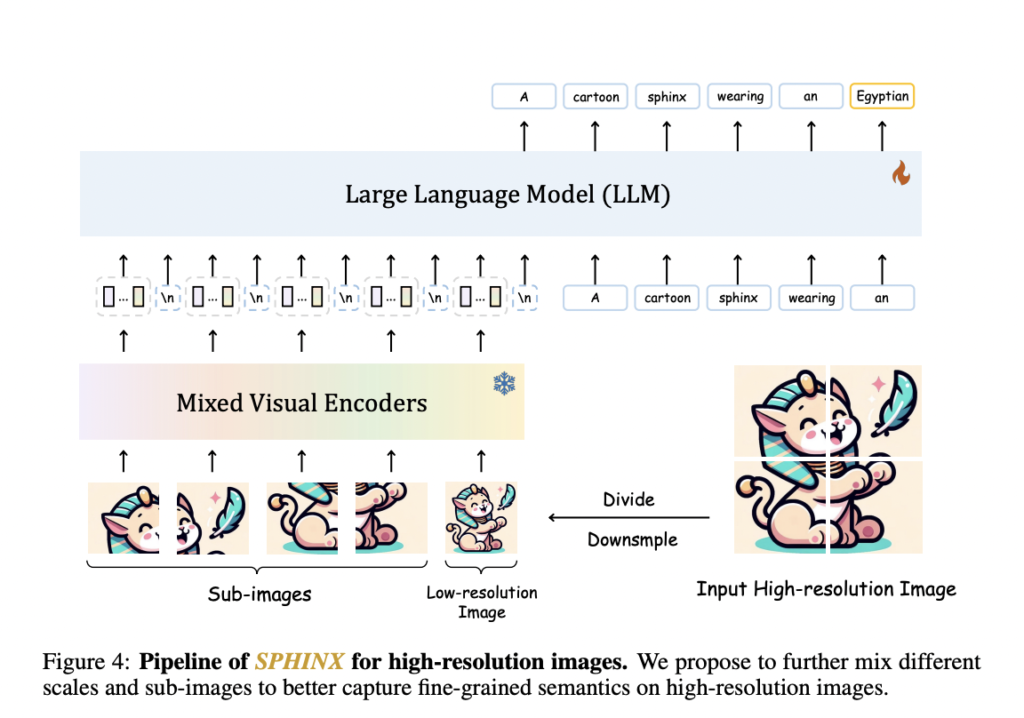
Delving into the intricate workings of SPHINX’s methodology, one unravels a classy integration of mannequin weights, tuning duties, and visible embeddings. A standout characteristic is the mannequin’s proficiency in processing high-resolution pictures, ushering in an period of fine-grained visible understanding. SPHINX’s collaboration with different visible basis fashions, similar to SAM for language-referred segmentation and Steady Diffusion for picture modifying, amplifies its capabilities, showcasing a holistic strategy to tackling the intricacies of vision-language understanding. A complete efficiency analysis cements SPHINX’s superiority throughout varied duties, from referring expression comprehension to human pose estimation and object detection. Notably, SPHINX’s prowess in improved object detection by means of hints and anomaly detection underscores its versatility and adaptableness to various challenges, positioning it as a frontrunner within the dynamic subject of multi-modal language fashions.

Within the consequence, the researchers emerge triumphant of their quest to deal with the prevailing limitations of vision-language fashions with the groundbreaking introduction of SPHINX. The threefold mixing technique heralds a brand new period, catapulting SPHINX past the confines of established benchmarks and showcasing its aggressive edge in visible grounding. The mannequin’s means to transcend established duties and exhibit emergent cross-task talents suggests a future ripe with potentialities and functions but to be explored.
The findings of this text not solely current an answer to up to date challenges but additionally beckon a horizon of future exploration and innovation. Because the analysis staff propels the sector ahead with SPHINX, the broader scientific neighborhood eagerly anticipates the transformative affect of this modern strategy. SPHINX’s success in navigating duties past the preliminary drawback assertion positions it as a trailblazing contribution to the evolving subject of vision-language understanding, promising unparalleled developments in multi-modal language fashions.
Try the Paper and Project. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to hitch our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Madhur Garg is a consulting intern at MarktechPost. He’s at present pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Know-how (IIT), Patna. He shares a powerful ardour for Machine Studying and enjoys exploring the newest developments in applied sciences and their sensible functions. With a eager curiosity in synthetic intelligence and its various functions, Madhur is decided to contribute to the sector of Knowledge Science and leverage its potential affect in varied industries.






