Researchers from Yale and Google Introduce HyperAttention: An Approximate Consideration Mechanism Accelerating Giant Language Fashions for Environment friendly Lengthy-Vary Sequence Processing
The speedy development of huge language fashions has paved the best way for breakthroughs in pure language processing, enabling purposes starting from chatbots to machine translation. Nonetheless, these fashions usually need assistance processing lengthy sequences effectively, important for a lot of real-world duties. Because the size of the enter sequence grows, the eye mechanisms in these fashions turn out to be more and more computationally costly. Researchers have been exploring methods to deal with this problem and make giant language fashions extra sensible for varied purposes.
A analysis crew just lately launched a groundbreaking answer known as “HyperAttention.” This modern algorithm goals to effectively approximate consideration mechanisms in giant language fashions, significantly when coping with lengthy sequences. It simplifies present algorithms and leverages varied methods to establish dominant entries in consideration matrices, finally accelerating computations.

HyperAttention’s method to fixing the effectivity drawback in giant language fashions includes a number of key components. Let’s dive into the main points:
- Spectral Ensures: HyperAttention focuses on attaining spectral ensures to make sure the reliability of its approximations. Using parameterizations based mostly on the situation quantity reduces the necessity for sure assumptions usually made on this area.
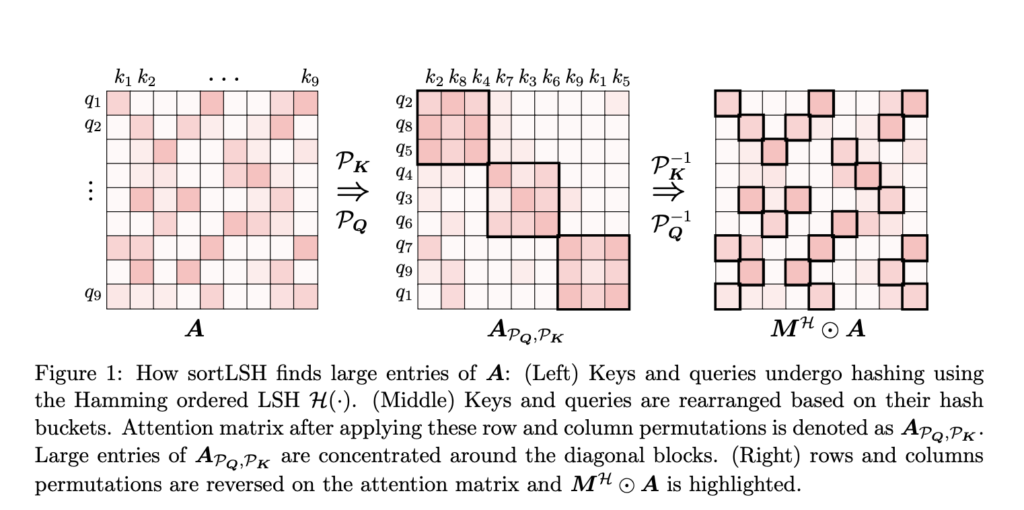
- SortLSH for Figuring out Dominant Entries: HyperAttention makes use of the Hamming sorted Locality-Delicate Hashing (LSH) method to reinforce effectivity. This methodology permits the algorithm to establish probably the most vital entries in consideration matrices, aligning them with the diagonal for extra environment friendly processing.
- Environment friendly Sampling Methods: HyperAttention effectively approximates diagonal entries within the consideration matrix and optimizes the matrix product with the values matrix. This step ensures that giant language fashions can course of lengthy sequences with out considerably dropping efficiency.
- Versatility and Flexibility: HyperAttention is designed to supply flexibility in dealing with totally different use instances. As demonstrated within the paper, it may be successfully utilized when utilizing a predefined masks or producing a masks utilizing the sortLSH algorithm.

The efficiency of HyperAttention is spectacular. It permits for substantial speedups in each inference and coaching, making it a precious instrument for big language fashions. By simplifying complicated consideration computations, it addresses the issue of long-range sequence processing, enhancing the sensible usability of those fashions.


In conclusion, the analysis crew behind HyperAttention has made vital progress in tackling the problem of environment friendly long-range sequence processing in giant language fashions. Their algorithm simplifies the complicated computations concerned in consideration mechanisms and presents spectral ensures for its approximations. By leveraging methods like Hamming sorted LSH, HyperAttention identifies dominant entries and optimizes matrix merchandise, resulting in substantial speedups in inference and coaching.
This breakthrough is a promising growth for pure language processing, the place giant language fashions play a central position. It opens up new potentialities for scaling self-attention mechanisms and makes these fashions extra sensible for varied purposes. Because the demand for environment friendly and scalable language fashions continues to develop, HyperAttention represents a big step in the suitable route, finally benefiting researchers and builders within the NLP neighborhood.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to affix our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on WhatsApp. Join our AI Channel on Whatsapp..
Madhur Garg is a consulting intern at MarktechPost. He’s at present pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Know-how (IIT), Patna. He shares a robust ardour for Machine Studying and enjoys exploring the newest developments in applied sciences and their sensible purposes. With a eager curiosity in synthetic intelligence and its numerous purposes, Madhur is set to contribute to the sphere of Knowledge Science and leverage its potential influence in varied industries.




