Construct an end-to-end MLOps pipeline for visible high quality inspection on the edge – Half 3

That is Half 3 of our collection the place we design and implement an MLOps pipeline for visible high quality inspection on the edge. On this submit, we concentrate on the way to automate the sting deployment a part of the end-to-end MLOps pipeline. We present you the way to use AWS IoT Greengrass to handle mannequin inference on the edge and the way to automate the method utilizing AWS Step Functions and different AWS providers.
Answer overview
In Part 1 of this collection, we laid out an structure for our end-to-end MLOps pipeline that automates all the machine studying (ML) course of, from information labeling to mannequin coaching and deployment on the edge. In Part 2, we confirmed the way to automate the labeling and mannequin coaching components of the pipeline.
The pattern use case used for this collection is a visible high quality inspection answer that may detect defects on steel tags, which you’ll deploy as a part of a producing course of. The next diagram reveals the high-level structure of the MLOps pipeline we outlined to start with of this collection. In the event you haven’t learn it but, we advocate testing Part 1.
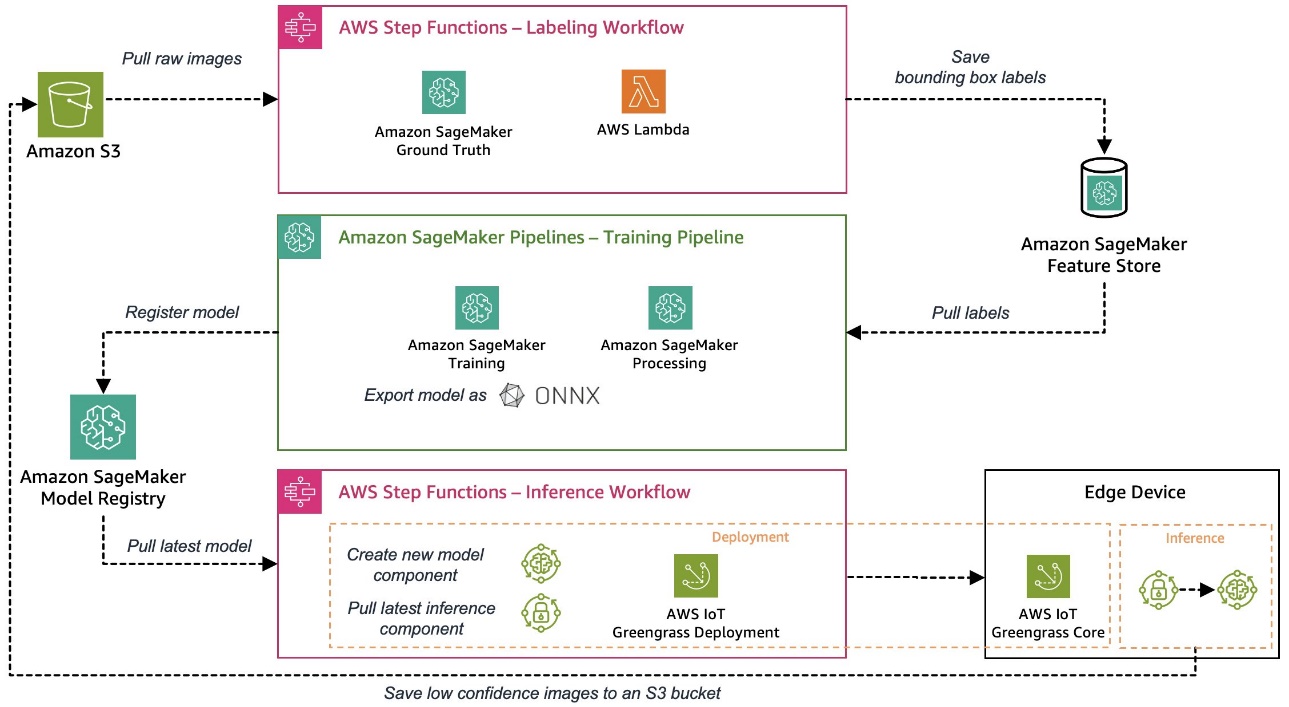
Automating the sting deployment of an ML mannequin
After an ML mannequin has been skilled and evaluated, it must be deployed to a manufacturing system to generate enterprise worth by making predictions on incoming information. This course of can shortly turn out to be advanced in an edge setting the place fashions must be deployed and run on gadgets which might be usually positioned distant from the cloud setting by which the fashions have been skilled. The next are a few of the challenges distinctive to machine studying on the edge:
- ML fashions usually must be optimized as a result of useful resource constraints on edge gadgets
- Edge gadgets can’t be redeployed and even changed like a server within the cloud, so that you want a strong mannequin deployment and system administration course of
- Communication between gadgets and the cloud must be environment friendly and safe as a result of it usually traverses untrusted low-bandwidth networks
Let’s see how we will sort out these challenges with AWS providers along with exporting the mannequin within the ONNX format, which permits us to, for instance, apply optimizations like quantization to cut back the mannequin dimension for constraint gadgets. ONNX additionally gives optimized runtimes for the most typical edge {hardware} platforms.
Breaking the sting deployment course of down, we require two elements:
- A deployment mechanism for the mannequin supply, which incorporates the mannequin itself and a few enterprise logic to handle and work together with the mannequin
- A workflow engine that may orchestrate the entire course of to make this strong and repeatable
On this instance, we use completely different AWS providers to construct our automated edge deployment mechanism, which integrates all of the required elements we mentioned.
Firstly, we simulate an edge system. To make it easy so that you can undergo the end-to-end workflow, we use an Amazon Elastic Compute Cloud (Amazon EC2) occasion to simulate an edge system by putting in the AWS IoT Greengrass Core software program on the occasion. You may as well use EC2 situations to validate the completely different elements in a QA course of earlier than deploying to an precise edge manufacturing system. AWS IoT Greengrass is an Web of Issues (IoT) open-source edge runtime and cloud service that helps you construct, deploy, and handle edge system software program. AWS IoT Greengrass reduces the trouble to construct, deploy, and handle edge system software program in a safe and scalable method. After you put in the AWS IoT Greengrass Core software program in your system, you’ll be able to add or take away options and elements, and handle your IoT system functions utilizing AWS IoT Greengrass. It presents a variety of built-in elements to make your life simpler, such because the StreamManager and MQTT dealer elements, which you need to use to securely talk with the cloud, supporting end-to-end encryption. You need to use these options to add inference outcomes and pictures effectively.
In a manufacturing setting, you’ll sometimes have an industrial digital camera delivering photos for which the ML mannequin ought to produce predictions. For our setup, we simulate this picture enter by importing a preset of photos into a particular listing on the sting system. We then use these photos as inference enter for the mannequin.
We divided the general deployment and inference course of into three consecutive steps to deploy a cloud-trained ML mannequin to an edge setting and use it for predictions:
- Put together – Bundle the skilled mannequin for edge deployment.
- Deploy – Switch of mannequin and inference elements from the cloud to the sting system.
- Inference – Load the mannequin and run inference code for picture predictions.
The next structure diagram reveals the small print of this three-step course of and the way we carried out it with AWS providers.

Within the following sections, we focus on the small print for every step and present the way to embed this course of into an automatic and repeatable orchestration and CI/CD workflow for each the ML fashions and corresponding inference code.
Put together
Edge gadgets usually include restricted compute and reminiscence in comparison with a cloud setting the place highly effective CPUs and GPUs can run ML fashions simply. Completely different model-optimization strategies mean you can tailor a mannequin for a particular software program or {hardware} platform to extend prediction velocity with out dropping accuracy.
On this instance, we exported the skilled mannequin within the coaching pipeline to the ONNX format for portability, potential optimizations, in addition to optimized edge runtimes, and registered the mannequin inside Amazon SageMaker Model Registry. On this step, we create a brand new Greengrass mannequin part together with the most recent registered mannequin for subsequent deployment.
Deploy
A safe and dependable deployment mechanism is vital when deploying a mannequin from the cloud to an edge system. As a result of AWS IoT Greengrass already incorporates a strong and safe edge deployment system, we’re utilizing this for our deployment functions. Earlier than we take a look at our deployment course of intimately, let’s do a fast recap on how AWS IoT Greengrass deployments work. On the core of the AWS IoT Greengrass deployment system are components, which outline the software program modules deployed to an edge system operating AWS IoT Greengrass Core. These can both be non-public elements that you just construct or public elements which might be offered both by AWS or the broader Greengrass community. A number of elements will be bundled collectively as a part of a deployment. A deployment configuration defines the elements included in a deployment and the deployment’s goal gadgets. It will probably both be outlined in a deployment configuration file (JSON) or by way of the AWS IoT Greengrass console when creating a brand new deployment.
We create the next two Greengrass elements, that are then deployed to the sting system by way of the deployment course of:
- Packaged mannequin (non-public part) – This part comprises the skilled and ML mannequin in ONNX format.
- Inference code (non-public part) – Except for the ML mannequin itself, we have to implement some software logic to deal with duties like information preparation, communication with the mannequin for inference, and postprocessing of inference outcomes. In our instance, we’ve developed a Python-based non-public part to deal with the next duties:
- Set up the required runtime elements just like the Ultralytics YOLOv8 Python package deal.
- As a substitute of taking photos from a digital camera reside stream, we simulate this by loading ready photos from a particular listing and getting ready the picture information in response to the mannequin enter necessities.
- Make inference calls towards the loaded mannequin with the ready picture information.
- Verify the predictions and add inference outcomes again to the cloud.
If you wish to have a deeper take a look at the inference code we constructed, confer with the GitHub repo.
Inference
The mannequin inference course of on the sting system routinely begins after deployment of the aforementioned elements is completed. The customized inference part periodically runs the ML mannequin with photos from a neighborhood listing. The inference consequence per picture returned from the mannequin is a tensor with the next content material:
- Confidence scores – How assured the mannequin is relating to the detections
- Object coordinates – The scratch object coordinates (x, y, width, top) detected by the mannequin within the picture
In our case, the inference part takes care of sending inference outcomes to a particular MQTT subject on AWS IoT the place it may be learn for additional processing. These messages will be considered by way of the MQTT take a look at shopper on the AWS IoT console for debugging. In a manufacturing setting, you’ll be able to resolve to routinely notify one other system that takes care of eradicating defective steel tags from the manufacturing line.
Orchestration
As seen within the previous sections, a number of steps are required to arrange and deploy an ML mannequin, the corresponding inference code, and the required runtime or agent to an edge system. Step Capabilities is a totally managed service that means that you can orchestrate these devoted steps and design the workflow within the type of a state machine. The serverless nature of this service and native Step Capabilities capabilities like AWS service API integrations mean you can shortly arrange this workflow. Constructed-in capabilities like retries or logging are essential factors to construct strong orchestrations. For extra particulars relating to the state machine definition itself, confer with the GitHub repository or test the state machine graph on the Step Capabilities console after you deploy this instance in your account.
Infrastructure deployment and integration into CI/CD
The CI/CD pipeline to combine and construct all of the required infrastructure elements follows the identical sample illustrated in Part 1 of this collection. We use the AWS Cloud Development Kit (AWS CDK) to deploy the required pipelines from AWS CodePipeline.

Learnings
There are a number of methods to construct an structure for an automatic, strong, and safe ML mannequin edge deployment system, which are sometimes very depending on the use case and different necessities. Nonetheless, right here just a few learnings we want to share with you:
- Consider upfront if the extra AWS IoT Greengrass compute resource requirements suit your case, particularly with constrained edge gadgets.
- Set up a deployment mechanism that integrates a verification step of the deployed artifacts earlier than operating on the sting system to make sure that no tampering occurred throughout transmission.
- It’s good observe to maintain the deployment elements on AWS IoT Greengrass as modular and self-contained as potential to have the ability to deploy them independently. For instance, in case you have a comparatively small inference code module however an enormous ML mannequin when it comes to dimension, you don’t at all times need to the deploy them each if simply the inference code has modified. That is particularly essential when you’ve got restricted bandwidth or excessive value edge system connectivity.
Conclusion
This concludes our three-part collection on constructing an end-to-end MLOps pipeline for visible high quality inspection on the edge. We regarded on the extra challenges that include deploying an ML mannequin on the edge like mannequin packaging or advanced deployment orchestration. We carried out the pipeline in a totally automated method so we will put our fashions into manufacturing in a strong, safe, repeatable, and traceable trend. Be at liberty to make use of the structure and implementation developed on this collection as a place to begin on your subsequent ML-enabled venture. When you have any questions the way to architect and construct such a system on your setting, please reach out. For different matters and use instances, confer with our Machine Learning and IoT blogs.
Concerning the authors
 Michael Roth is a Senior Options Architect at AWS supporting Manufacturing prospects in Germany to resolve their enterprise challenges by AWS know-how. Apart from work and household he’s keen on sports activities vehicles and enjoys Italian espresso.
Michael Roth is a Senior Options Architect at AWS supporting Manufacturing prospects in Germany to resolve their enterprise challenges by AWS know-how. Apart from work and household he’s keen on sports activities vehicles and enjoys Italian espresso.
 Jörg Wöhrle is a Options Architect at AWS, working with manufacturing prospects in Germany. With a ardour for automation, Joerg has labored as a software program developer, DevOps engineer, and Web site Reliability Engineer in his pre-AWS life. Past cloud, he’s an bold runner and enjoys high quality time along with his household. So in case you have a DevOps problem or need to go for a run: let him know.
Jörg Wöhrle is a Options Architect at AWS, working with manufacturing prospects in Germany. With a ardour for automation, Joerg has labored as a software program developer, DevOps engineer, and Web site Reliability Engineer in his pre-AWS life. Past cloud, he’s an bold runner and enjoys high quality time along with his household. So in case you have a DevOps problem or need to go for a run: let him know.
 Johannes Langer is a Senior Options Architect at AWS, working with enterprise prospects in Germany. Johannes is enthusiastic about making use of machine studying to resolve actual enterprise issues. In his private life, Johannes enjoys engaged on residence enchancment tasks and spending time outside along with his household.
Johannes Langer is a Senior Options Architect at AWS, working with enterprise prospects in Germany. Johannes is enthusiastic about making use of machine studying to resolve actual enterprise issues. In his private life, Johannes enjoys engaged on residence enchancment tasks and spending time outside along with his household.





