Researchers from UT Austin Introduce MUTEX: A Leap In the direction of Multimodal Robotic Instruction with Cross-Modal Reasoning
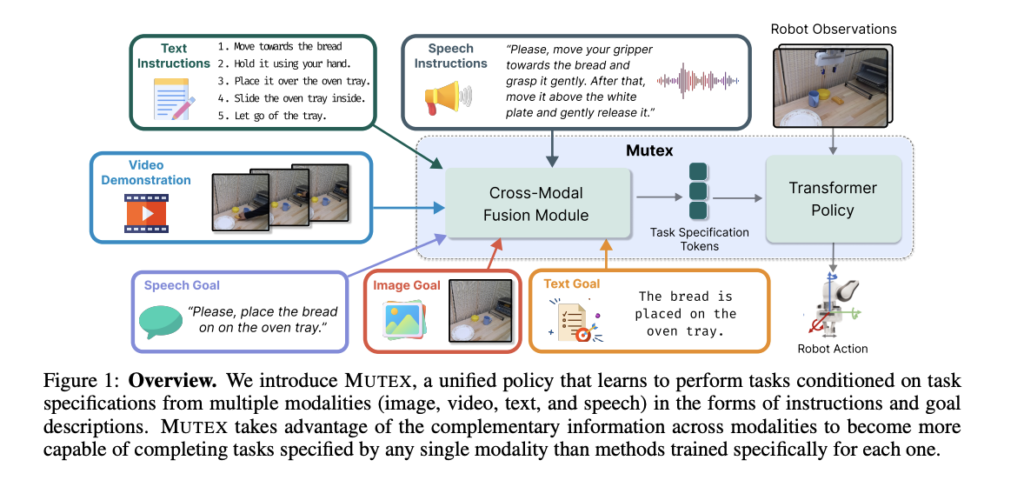
Researchers have launched a cutting-edge framework referred to as MUTEX, brief for “MUltimodal Activity specification for robotic EXecution,” geared toward considerably advancing the capabilities of robots in helping people. The first drawback they deal with is the limitation of present robotic coverage studying strategies, which usually concentrate on a single modality for process specification, leading to robots which can be proficient in a single space however need assistance to deal with various communication strategies.
MUTEX takes a groundbreaking strategy by unifying coverage studying from numerous modalities, permitting robots to grasp and execute duties based mostly on directions conveyed by means of speech, textual content, pictures, movies, and extra. This holistic strategy is a pivotal step in direction of making robots versatile collaborators in human-robot groups.
The framework’s coaching course of includes a two-stage process. The primary stage combines masked modeling and cross-modal matching aims. Masked modeling encourages cross-modal interactions by masking sure tokens or options inside every modality and requiring the mannequin to foretell them utilizing data from different modalities. This ensures that the framework can successfully leverage data from a number of sources.
Within the second stage, cross-modal matching enriches the representations of every modality by associating them with the options of essentially the most information-dense modality, which is video demonstrations on this case. This step ensures that the framework learns a shared embedding house that enhances the illustration of process specs throughout completely different modalities.
MUTEX’s structure consists of modality-specific encoders, a projection layer, a coverage encoder, and a coverage decoder. It makes use of modality-specific encoders to extract significant tokens from enter process specs. These tokens are then processed by means of a projection layer earlier than being handed to the coverage encoder. The coverage encoder, using a transformer-based structure with cross- and self-attention layers, fuses data from numerous process specification modalities and robotic observations. This output is then despatched to the coverage decoder, which leverages a Perceiver Decoder structure to generate options for motion prediction and masked token queries. Separate MLPs are used to foretell steady motion values and token values for the masked tokens.
To guage MUTEX, the researchers created a complete dataset with 100 duties in a simulated setting and 50 duties in the true world, every annotated with a number of cases of process specs in numerous modalities. The outcomes of their experiments had been promising, exhibiting substantial efficiency enhancements over strategies educated solely for single modalities. This underscores the worth of cross-modal studying in enhancing a robotic’s potential to grasp and execute duties. Textual content Objective and Speech Objective, Textual content Objective and Picture Objective, and Speech Directions and Video Demonstration have obtained 50.1, 59.2, and 59.6 success charges, respectively.
In abstract, MUTEX is a groundbreaking framework that addresses the restrictions of present robotic coverage studying strategies by enabling robots to understand and execute duties specified by means of numerous modalities. It presents promising potential for more practical human-robot collaboration, though it does have some limitations that want additional exploration and refinement. Future work will concentrate on addressing these limitations and advancing the framework’s capabilities.
Take a look at the Paper and Code. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Know-how(IIT), Kharagpur. She is a tech fanatic and has a eager curiosity within the scope of software program and knowledge science purposes. She is at all times studying in regards to the developments in numerous discipline of AI and ML.
 The end of project management by humans (Sponsored)
The end of project management by humans (Sponsored) 




