A generative AI-powered answer on Amazon SageMaker to assist Amazon EU Design and Building
The Amazon EU Design and Building (Amazon D&C) crew is the engineering crew designing and setting up Amazon Warehouses throughout Europe and the MENA area. The design and deployment processes of tasks contain many kinds of Requests for Data (RFIs) about engineering necessities relating to Amazon and project-specific pointers. These requests vary from easy retrieval of baseline design values, to evaluation of worth engineering proposals, to evaluation of studies and compliance checks. As we speak, these are addressed by a Central Technical Crew, comprised of subject material specialists (SMEs) who can reply such extremely technical specialised questions, and supply this service to all stakeholders and groups all through the mission lifecycle. The crew is on the lookout for a generative AI query answering answer to shortly get data and proceed with their engineering design. Notably, these use circumstances will not be restricted to the Amazon D&C crew alone however are relevant to the broader scope of World Engineering Companies concerned in mission deployment. Your entire vary of stakeholders and groups engaged within the mission lifecycle can profit from a generative AI question-answering answer, as it is going to allow fast entry to important data, streamlining the engineering design and mission administration processes.
The prevailing generative AI options for query answering are primarily primarily based on Retrieval Augmented Generation (RAG). RAG searches paperwork by means of large language model (LLM) embedding and vectoring, creates the context from search outcomes by means of clustering, and makes use of the context as an augmented immediate to inference a basis mannequin to get the reply. This methodology is much less environment friendly for the extremely technical paperwork from Amazon D&C, which comprises vital unstructured knowledge reminiscent of Excel sheets, tables, lists, figures, and pictures. On this case, the query answering activity works higher by fine-tuning the LLM with the paperwork. Tremendous-tuning adjusts and adapts the weights of the pre-trained LLM to enhance the mannequin high quality and accuracy.
To deal with these challenges, we current a brand new framework with RAG and fine-tuned LLMs. The answer makes use of Amazon SageMaker JumpStart because the core service for the mannequin fine-tuning and inference. On this put up, we not solely present the answer, but additionally focus on the teachings realized and greatest practices when implementing the answer in real-world use circumstances. We examine and distinction how completely different methodologies and open-source LLMs carried out in our use case and focus on tips on how to discover the trade-off between mannequin efficiency and compute useful resource prices.
Resolution overview
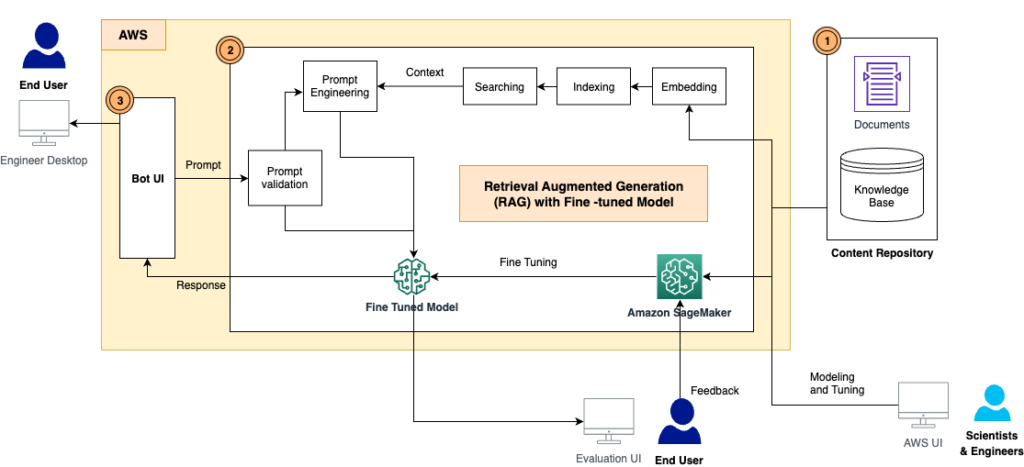
The answer has the next elements, as proven within the structure diagram:
- Content material repository – The D&C contents embrace a variety of human-readable paperwork with numerous codecs, reminiscent of PDF recordsdata, Excel sheets, wiki pages, and extra. On this answer, we saved these contents in an Amazon Simple Storage Service (Amazon S3) bucket and used them as a information base for data retrieval in addition to inference. Sooner or later, we’ll construct integration adapters to entry the contents instantly from the place they reside.
- RAG framework with a fine-tuned LLM – This consists of the next subcomponents:
- RAG framework – This retrieves the related knowledge from paperwork, augments the prompts by including the retrieved knowledge in context, and passes it to a fine-tuned LLM to generate outputs.
- Tremendous-tuned LLM – We constructed the coaching dataset from the paperwork and contents and performed fine-tuning on the inspiration mannequin. After the tuning, the mannequin realized the information from the D&C contents, and subsequently can reply to the questions independently.
- Immediate validation module – This measures the semantic match between the consumer’s immediate and the dataset for fine-tuning. If the LLM is fine-tuned to reply this query, then you may inference the fine-tuned mannequin for a response. If not, you should utilize RAG to generate the response.
- LangChain – We use LangChain to construct a workflow to answer the incoming questions.
- Finish-user UI – That is the chatbot UI to seize customers’ questions and queries, and current the reply from the RAG and LLM response.

Within the subsequent sections, we exhibit tips on how to create the RAG workflow and construct the fine-tuned fashions.
RAG with basis fashions by SageMaker JumpStart
RAG combines the powers of pre-trained dense retrieval and sequence-to-sequence (seq2seq) basis fashions. For query answering from Amazon D&C paperwork, we have to put together the next prematurely:
- Embedding and indexing the paperwork utilizing an LLM embedding mannequin – We break up the a number of paperwork into small chunks primarily based on the doc chapter and part construction, examined with the Amazon GPT-J-6B mannequin on SageMaker JumpStart to generate the indexes, and saved the indexes in a FAISS vector retailer
- A pre-trained basis mannequin to generate responses from prompts – We examined with Flan-T5 XL, Flan-T5 XXL, and Falcon-7B fashions on SageMaker JumpStart
The query answering course of is carried out by LangChain, which is a framework for creating purposes powered by language fashions. The workflow within the chain comprises the next steps:
- Get a query from the consumer.
- Carry out semantic search on the listed paperwork by means of FAISS to get the highest Okay most-relevant doc chunks.
- Outline the immediate template, reminiscent of
- Increase the retrieved doc chunks because the
{context}and the consumer query because the{query}within the immediate. - Immediate the inspiration mannequin with the constructed zero-shot immediate.
- Return the mannequin output to the consumer.
We examined 125 questions on Amazon D&C necessities and specs, and RAG returned response for some questions. Within the following instance, RAG with the Flan-T5-XXL mannequin offered correct response from the appropriate sections of the paperwork.
| Query | What are the PLUMBING necessities for Ingesting Fountains and Water Coolers? (Part 22 47 00) |
| Anticipated reply | The Developer shall present water allotting bars, ground standing on the Warehouse wall area instantly adjoining to the doorway of every rest room block serving the Warehouse and within the equal location adjoining to the Lockers Room rest room block. Items shall be in accordance with Amazon commonplace. Ultimate numbers and placement to be agreed with Amazon previous to set up. Minimal of two models allotting cooled and room temperature water to be offered at every location. Water Coolers or Water Bars – The Developer shall present potable water provides as required for distant water coolers or water bars all through the power. The Developer shall present water factors, drainage and any electrical providers required within the Break Rooms for the Water Bars which shall be offered by the Catering Contractor. |
| RAG reply (GPT-J-6B embedding with Flan-T5-XXL) | The Developer shall present water allotting bars, ground standing on the Warehouse wall area instantly adjoining to the doorway of every rest room block serving the Warehouse and within the equal location adjoining to the Lockers Room rest room block. Items shall be in accordance with Amazon commonplace. Ultimate numbers and placement to be agreed with Amazon previous to set up. Minimal of two models allotting cooled and room temperature water to be offered at every location. Water Coolers or Water Bars – The Developer shall present potable water provides as required for distant water coolers or water bars all through the power. The Developer shall present water factors, drainage and any electrical providers required within the Break Rooms for the Water Bars which shall be offered by the Catering Contractor. |
Nevertheless, we noticed that RAG doesn’t present clear and crisp solutions to the questions which might be extra particular and extremely technical, reminiscent of pointers, numbers, and figures. As proven within the following instance, when a technical dimension output is predicted, RAG can’t present the precise reply, primarily as a result of the embedding and looking course of can’t return a concise context.
| Query | What’s the Ground Heights requirement for P2 First Ground stage Concrete? |
| Anticipated reply | 7,50 m AFFL |
| RAG reply (GPT-J-6B embedding with Flan-T5-XXL) | P2 First Ground stage Concrete |
This must be improved as a result of hallucination isn’t tolerated because of the criticality of the implications on this use case.
Tremendous-tune LLMs on SageMaker
To deal with this problem and enhance the response high quality, we take a brand new method to fine-tune the LLM mannequin utilizing the paperwork for a query answering activity. The mannequin shall be skilled to study the corresponding information from the paperwork instantly. In contrast to RAG, it’s not depending on whether or not the paperwork are correctly embedded and listed, and whether or not the semantic search algorithm is efficient sufficient to return probably the most related contents from the vector database.
To organize the coaching dataset for fine-tuning, we extract the data from the D&C paperwork and assemble the information within the following format:
- Instruction – Describes the duty and offers partial immediate
- Enter – Gives additional context to be consolidated into the immediate
- Response – The output of the mannequin
In the course of the coaching course of, we add an instruction key, enter key, and response key to every half, mix them into the coaching immediate, and tokenize it. Then the information is fed to a coach in SageMaker to generate the fine-tuned mannequin.
To speed up the coaching course of and scale back the price of compute sources, we employed Parameter Efficient Fine-Tuning (PEFT) with the Low-Rank Adaptation (LoRA) approach. PEFT permits us to solely fine-tune a small variety of additional mannequin parameters, and LoRA represents the load updates with two smaller matrices by means of low-rank decomposition. With PEFT and LoRA on 8-bit quantization (a compression operation that additional reduces the reminiscence footprint of the mannequin and accelerates the coaching and inference efficiency), we’re capable of match the coaching of 125 question-answer pairs inside a g4dn.x occasion with a single GPU.
To show the effectiveness of the fine-tuning, we examined with a number of LLMs on SageMaker. We chosen 5 small-size fashions: Bloom-7B, Flan-T5-XL, GPT-J-6B, and Falcon-7B on SageMaker JumpStart, and Dolly-3B from Hugging Face on SageMaker.
By way of 8-bit LoRA-based coaching, we’re capable of scale back the trainable parameters to not more than 5% of the total weights of every mannequin. The coaching takes 10–20 epochs to converge, as proven within the following determine. For every mannequin, the fine-tuning processes can match on a single GPU of a g4dn.x occasion, which optimized the prices of compute sources.

Inference the fine-tuned mannequin deployed on SageMaker
We deployed the fine-tuned mannequin together with the RAG framework in a single GPU g4dn.x node on SageMaker and in contrast the inference outcomes for the 125 questions. The mannequin efficiency is measured by two metrics. One is the ROUGE (Recall-Oriented Understudy for Gisting Analysis) rating, a preferred natural language processing (NLP) mannequin analysis methodology that calculates the quotient of the matching phrases underneath the overall depend of phrases within the reference sentence. The opposite is the semantic (textual) similarity rating, which measures how shut the which means of two items of textual content meanings are through the use of a transformer mannequin to encode sentences to get their embeddings, then utilizing a cosine similarity metric to compute their similarity rating. From the experiments, we will see these two metrics are pretty constant in presenting the standard of solutions to the questions.
Within the following desk and determine, we will see that the fine-tuned Falcon-7B mannequin offers the highest quality of answering, and the Flan-T5-XL and Dolly-3B fashions additionally generate correct responses.
| . | RAG_GPT-J-6B_Flan-T5-XL | RAG_GPT-J-6B_Flan-T5-XXL | Tremendous-tuned Bloom-7B1 | Tremendous-tuned Flan-T5-XL | Tremendous-tuned GPT-J-6B | Tremendous-tuned Dolly-3B | Tremendous-tuned Falcon-7B |
| ROUGE Rating | 0.1938 | 0.2747 | 0.3914 | 0.4977 | 0.3740 | 0.6991 | 0.9459 |
| Semantic Similarity Rating | 0.4121 | 0.4786 | 0.5666 | 0.7205 | 0.5414 | 0.8147 | 0.9774 |

The next is one instance reply from the fashions. RAG with the Flan-T5-XL mannequin offered a extremely hallucinated response, whereas the response from RAG with the bigger Flan-T5-XXL mannequin was extra related however nonetheless not capable of cowl the total anticipated message. Comparatively, all of the fine-tuned fashions (Flan-T5-XL, Dolly-3B, and Falcon-7B) have been capable of present probably the most correct response because the anticipated reply.
| Query | What are the necessities for Submit Grinding Sealer/Hardener? (TS0004 – part 2.8) |
| Anticipated reply | A Lithium primarily based sealer/hardener shall be used put up any grinding/sanding procedures undertaken on the AR Ground. Please discuss with TGC /0007 AR Ground SCA Procedures. Alternate options shall be thought-about however have to be accredited by Amazon and the Flooring Marketing consultant. |
| Reply from RAG (GPT-J-6B embedding with Flan-T5-XL) | The Penetrating Concrete Hardener have to be mentioned on the pre-pour assembly and have to be accredited by the Flooring Marketing consultant and Amazon |
| Reply from RAG (GPT-J-6B embedding with Flan-T5-XXL) | The proposed compound have to be mentioned on the pre – pour assembly and have to be accredited by the Flooring Marketing consultant and Amazon. Alternate options shall be thought-about however have to be accredited by Amazon and the Flooring Marketing consultant. |
| Reply from fine-tuned Flan-T5-XL | A Lithium primarily based sealer/hardener shall be used put up any grinding/sanding procedures undertaken on the AR Ground. Please discuss with TGC /0007 AR Ground SCA Procedures. Alternate options shall be thought-about however have to be accredited by Amazon and the Flooring Marketing consultant. |
| Reply from fine-tuned Dolly-3B | A Lithium primarily based sealer/hardener shall be used put up any grinding/sanding procedures undertaken on the AR Ground. Please discuss with TGC /0007 AR Ground SCA Procedures. Alternate options shall be thought-about however have to be accredited by Amazon and the Flooring Marketing consultant. |
| Reply from fine-tuned Falcon-7B | A Lithium primarily based sealer/hardener shall be used put up any grinding/sanding procedures undertaken on the AR Ground. Please discuss with TGC /0007 AR Ground SCA Procedures. Alternate options shall be thought-about however have to be accredited by Amazon and the Flooring Marketing consultant. |
Resolution prototype and end result
We developed a prototype primarily based on the offered structure and performed a proof of idea to exhibit the result. To reap the benefits of each the RAG framework and the fine-tuned LLM, and likewise to scale back the hallucination, we first semantically validate the incoming query. If the query is among the many coaching knowledge for the fine-tuning (the fine-tuned mannequin already has the information to supply a high-quality reply), then we direct the query as a immediate to inference the fine-tuned mannequin. In any other case, the query goes by means of LangChain and will get the response from RAG. The next diagram illustrates this workflow.

We examined the structure with a take a look at dataset of 166 questions, which comprises the 125 questions used to fine-tune the mannequin and a further 41 questions that the fine-tuned mannequin wasn’t skilled with. The RAG framework with the embedding mannequin and fine-tuned Falcon-7B mannequin offered high-quality outcomes with a ROUGE rating of 0.7898 and a semantic similarity rating of 0.8781. As proven within the following examples, the framework is ready to generate responses to customers’ questions which might be nicely matched with the D&C paperwork.
The next picture is our first instance doc.

The next screenshot exhibits the bot output.

The bot can be capable of reply with knowledge from a desk or listing and show figures for the corresponding questions. For instance, we use the next doc.

The next screenshot exhibits the bot output.

We will additionally use a doc with a determine, as within the following instance.

The next screenshot exhibits the bot output with textual content and the determine.

The next screenshot exhibits the bot output with simply the determine.

Classes realized and greatest practices
By way of the answer design and experiments with a number of LLMs, we realized how to make sure the standard and efficiency for the query answering activity in a generative AI answer. We suggest the next greatest practices whenever you apply the answer to your query answering use circumstances:
- RAG offers affordable responses to engineering questions. The efficiency is closely depending on doc embedding and indexing. For extremely unstructured paperwork, you might want some guide work to correctly break up and increase the paperwork earlier than LLM embedding and indexing.
- The index search is necessary to find out the RAG closing output. It’s best to correctly tune the search algorithm to attain stage of accuracy and guarantee RAG generates extra related responses.
- Tremendous-tuned LLMs are capable of study extra information from extremely technical and unstructured paperwork, and possess the information throughout the mannequin with no dependency on the paperwork after coaching. That is particularly helpful to be used circumstances the place hallucination isn’t tolerated.
- To make sure the standard of mannequin response, the coaching dataset format for fine-tuning ought to make the most of a correctly outlined, task-specific immediate template. The inference pipeline ought to comply with the identical template with the intention to generate human-like responses.
- LLMs typically include a considerable price ticket and demand appreciable sources and exorbitant prices. You need to use PEFT and LoRA and quantization methods to scale back the demand of compute energy and keep away from excessive coaching and inference prices.
- SageMaker JumpStart offers easy-to-access pre-trained LLMs for fine-tuning, inference, and deployment. It will probably considerably speed up your generative AI answer design and implementation.
Conclusion
With the RAG framework and fine-tuned LLMs on SageMaker, we’re capable of present human-like responses to customers’ questions and prompts, thereby enabling customers to effectively retrieve correct data from a big quantity of extremely unstructured and unorganized paperwork. We’ll proceed to develop the answer, reminiscent of offering the next stage of contextual response from earlier interactions, and additional fine-tuning the fashions from human suggestions.
Your suggestions is all the time welcome; please depart your ideas and questions within the feedback part.
In regards to the authors
 Yunfei Bai is a Senior Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps prospects undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic goals. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
Yunfei Bai is a Senior Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps prospects undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic goals. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
 Burak Gozluklu is a Principal ML Specialist Options Architect situated in Boston, MA. Burak has over 15 years of trade expertise in simulation modeling, knowledge science, and ML know-how. He helps international prospects undertake AWS applied sciences and particularly AI/ML options to attain their enterprise goals. Burak has a PhD in Aerospace Engineering from METU, an MS in Programs Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is obsessed with yoga and meditation.
Burak Gozluklu is a Principal ML Specialist Options Architect situated in Boston, MA. Burak has over 15 years of trade expertise in simulation modeling, knowledge science, and ML know-how. He helps international prospects undertake AWS applied sciences and particularly AI/ML options to attain their enterprise goals. Burak has a PhD in Aerospace Engineering from METU, an MS in Programs Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is obsessed with yoga and meditation.
![]() Elad Dwek is a Building Expertise Supervisor at Amazon. With a background in development and mission administration, Elad helps groups undertake new applied sciences and data-based processes to ship development tasks. He identifies wants and options, and facilitates the event of the bespoke attributes. Elad has an MBA and a BSc in Structural Engineering. Outdoors of labor, Elad enjoys yoga, woodworking, and touring together with his household.
Elad Dwek is a Building Expertise Supervisor at Amazon. With a background in development and mission administration, Elad helps groups undertake new applied sciences and data-based processes to ship development tasks. He identifies wants and options, and facilitates the event of the bespoke attributes. Elad has an MBA and a BSc in Structural Engineering. Outdoors of labor, Elad enjoys yoga, woodworking, and touring together with his household.





