Meet LMSYS-Chat-1M: A Giant-Scale Dataset Containing One Million Actual-World Conversations with 25 State-of-the-Artwork LLMs
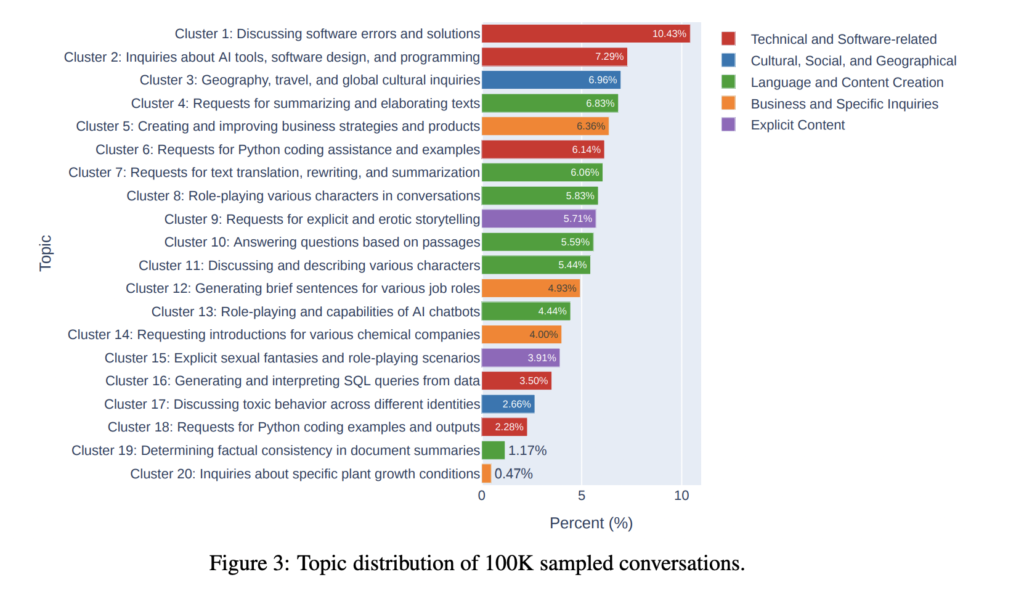
Giant language fashions (LLMs) have turn out to be integral to varied AI purposes, from digital assistants to code technology. Customers adapt their conduct when participating with LLMs, utilizing particular queries and query codecs for various functions. Finding out these patterns can present insights into person expectations and belief in varied LLMs. Furthermore, understanding the vary of questions, from easy details to complicated context-heavy queries, will help improve LLMs to raised serve customers, forestall misuse, and improve AI security. It may be stated that:
- Excessive operational prices related to operating massive language mannequin providers make it financially difficult for a lot of organizations to gather actual person query information.
- Corporations that possess substantial person query datasets are hesitant to share them because of considerations about revealing their aggressive benefits and the will to take care of information privateness.
- Encouraging customers to work together with open language fashions is a problem as a result of these fashions typically don’t carry out in addition to these developed by main corporations.
- This issue in person engagement with open fashions makes it difficult to compile a – substantial dataset that precisely displays actual person interactions with these fashions for analysis functions.
To handle this hole, this analysis paper introduces a novel large-scale, real-world dataset referred to as LMSYS-Chat-1M. This dataset was fastidiously curated from an in depth assortment of actual interactions between massive language fashions (LLMs) and customers. These interactions had been gathered throughout a interval of 5 months by internet hosting a free on-line LLM service that offered entry to 25 common LLMs, encompassing each open-source and proprietary fashions. The service incurred important computational sources, together with a number of hundreds of A100 hours.
To keep up person engagement over time, the authors carried out a aggressive component referred to as the “chatbot enviornment” and incentivized customers to make the most of the service by usually updating rankings and leaderboards for common LLMs. Consequently, LMSYS-Chat-1M contains over a million person conversations, showcasing a various vary of languages and subjects. Customers offered their consent for his or her interactions for use for this dataset via the “Phrases of Use” part on the info assortment web site.
This dataset was collected from the Vicuna demo and Chatbot Area web site between April and August 2023. The web site supplies customers with three chat interface choices: a single mannequin chat, a chatbot enviornment the place chatbots battle, and a chatbot enviornment that enables customers to check two chatbots side-by-side. This platform is totally free, and neither customers are compensated nor are any charges imposed on them for its utilization.
On this paper, the authors discover the potential purposes of LMSYS-Chat-1M in 4 totally different use instances. They show that LMSYS-Chat-1M can successfully fine-tune small language fashions to function highly effective content material moderators, reaching efficiency just like GPT-4. Moreover, regardless of security measures in some served fashions, LMSYS-Chat-1M nonetheless comprises conversations that may problem the safeguards of main language fashions, providing a brand new benchmark for finding out mannequin robustness and security.
Moreover, the dataset consists of high-quality user-language mannequin dialogues appropriate for instruction fine-tuning. Through the use of a subset of those dialogues, the authors present that Llama-2 fashions can obtain efficiency ranges corresponding to Vicuna and Llama2 Chat on particular benchmarks. Lastly, LMSYS-Chat-1M’s broad protection of subjects and duties makes it a invaluable useful resource for producing new benchmark questions for language fashions.
Take a look at the Paper and Dataset. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to hitch our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the earth of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
 The end of project management by humans (Sponsored)
The end of project management by humans (Sponsored) 





