How United Airways constructed a cost-efficient Optical Character Recognition energetic studying pipeline

On this submit, we focus on how United Airways, in collaboration with the Amazon Machine Learning Solutions Lab, construct an energetic studying framework on AWS to automate the processing of passenger paperwork.
“With a view to ship the perfect flying expertise for our passengers and make our inner enterprise course of as environment friendly as potential, we have now developed an automatic machine learning-based doc processing pipeline in AWS. With a view to energy these purposes, in addition to these utilizing different information modalities like pc imaginative and prescient, we’d like a strong and environment friendly workflow to shortly annotate information, prepare and consider fashions, and iterate shortly. Over the course a pair months, United partnered with the Amazon Machine Studying Options Labs to design and develop a reusable, use case-agnostic energetic studying workflow utilizing AWS CDK. This workflow can be foundational to our unstructured data-based machine studying purposes as it should allow us to reduce human labeling effort, ship robust mannequin efficiency shortly, and adapt to information drift.”
– Jon Nelson, Senior Supervisor of Knowledge Science and Machine Studying at United Airways.
Downside
United’s Digital Expertise crew is made up of worldwide various people working along with cutting-edge expertise to drive enterprise outcomes and hold buyer satisfaction ranges excessive. They needed to benefit from machine studying (ML) strategies corresponding to pc imaginative and prescient (CV) and pure language processing (NLP) to automate doc processing pipelines. As a part of this technique, they developed an in-house passport evaluation mannequin to confirm passenger IDs. The method depends on handbook annotations to coach ML fashions, that are very expensive.
United needed to create a versatile, resilient, and cost-efficient ML framework for automating passport info verification, validating passenger’s identities and detecting potential fraudulent paperwork. They engaged the ML Options Lab to assist obtain this aim, which permits United to proceed delivering world-class service within the face of future passenger progress.
Answer overview
Our joint crew designed and developed an energetic studying framework powered by the AWS Cloud Development Kit (AWS CDK), which programmatically configures and provisions all essential AWS providers. The framework makes use of Amazon SageMaker to course of unlabeled information, creates smooth labels, launches handbook labeling jobs with Amazon SageMaker Ground Truth, and trains an arbitrary ML mannequin with the ensuing dataset. We used Amazon Textract to automate info extraction from particular doc fields corresponding to identify and passport quantity. On a excessive stage, the strategy could be described with the next diagram.
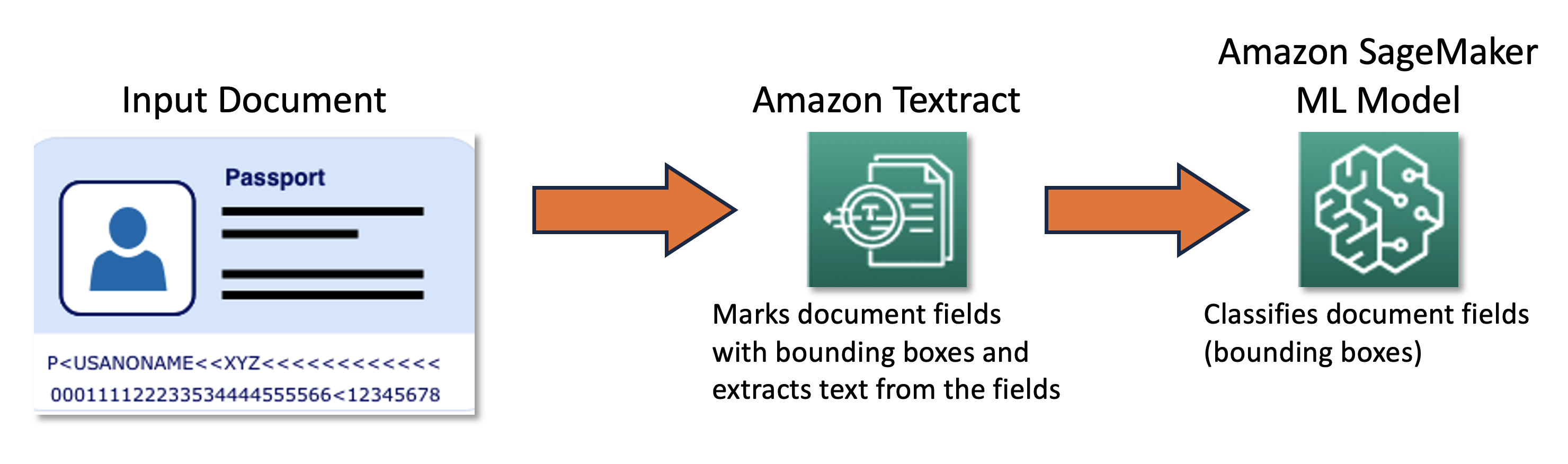
Knowledge
The first dataset for this drawback is comprised of tens of hundreds of main-page passport photos from which private info (identify, date of start, passport quantity, and so forth) have to be extracted. Picture dimension, format, and construction range relying on the doc issuing nation. We normalize these photos right into a set of uniform thumbnails, which represent the purposeful enter for the energetic studying pipeline (auto-labeling and inference).
The second dataset comprises JSON line formatted manifest recordsdata that relate uncooked passport photos, thumbnail photos, and label info corresponding to smooth labels and bounding field positions. Manifest recordsdata function a metadata set storing outcomes from varied AWS providers in a unified format, and decouple the energetic studying pipeline from downstream providers utilized by United. The next diagram illustrates this structure.
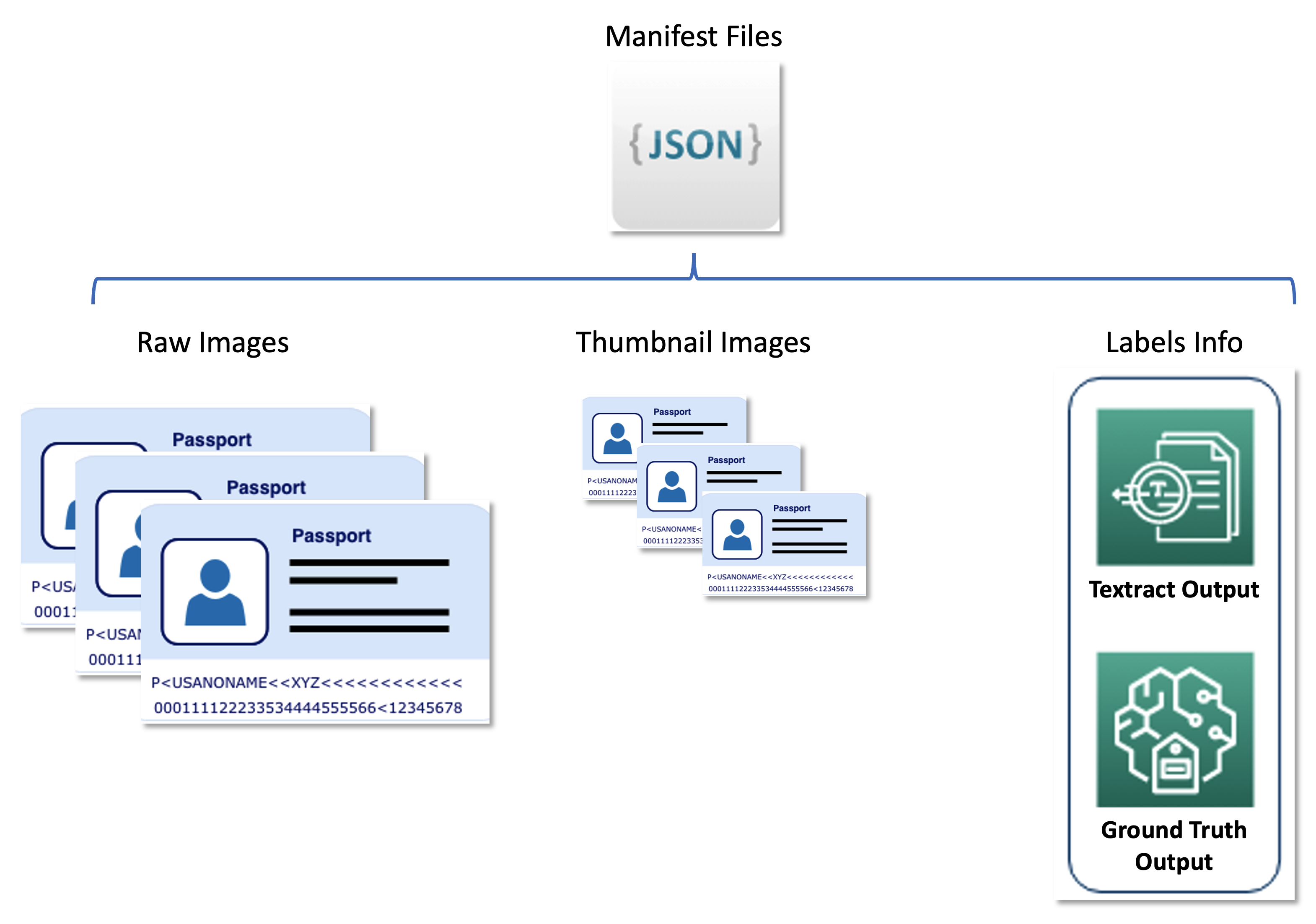
The next code is an instance manifest file:
Answer parts
The answer contains two foremost parts:
- An ML framework, which is chargeable for coaching the mannequin
- An auto-labeling pipeline, which is chargeable for bettering educated mannequin accuracy in a cost-efficient method
The ML framework is chargeable for coaching the ML mannequin and deploying it as a SageMaker endpoint. The auto-labeling pipeline focuses on automating SageMaker Floor Reality jobs and sampling photos for labeling by these jobs.
The 2 parts are decoupled from one another and solely work together by the set of labeled photos produced by the auto-labeling pipeline. That’s, the labeling pipeline creates labels which are later utilized by the ML framework to coach the ML mannequin.
ML framework
The ML Options Lab crew constructed the ML framework utilizing the Hugging Face implementation of the state-of-art LayoutLMV2 mannequin (LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, Yang Xu, et al.). Coaching was primarily based on Amazon Textract outputs, which served as a preprocessor and produced bounding bins round textual content of curiosity. The framework makes use of distributed coaching and runs on a customized Docker container primarily based on the SageMaker pre-built Hugging Face picture with extra dependencies (dependencies which are lacking within the pre-built SageMaker Docker picture however required for Hugging Face LayoutLMv2).
The ML mannequin was educated to categorise doc fields within the following 11 courses:
The coaching pipeline could be summarized within the following diagram.
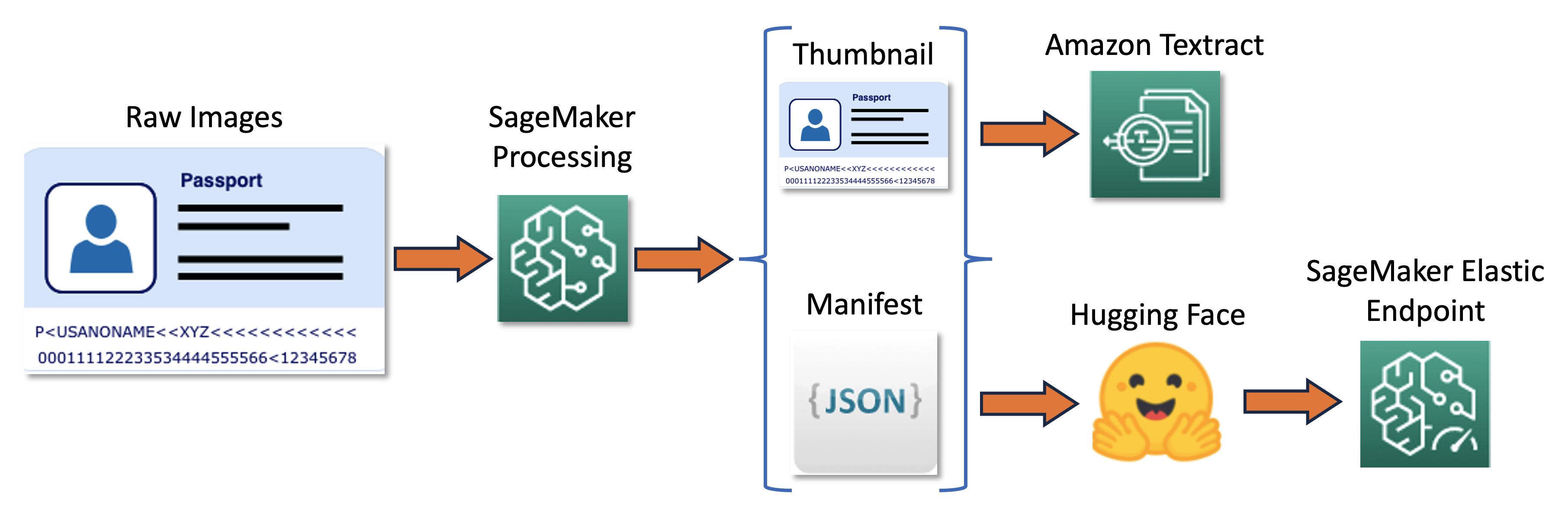
First, we resize and normalize a batch of uncooked photos into thumbnails. On the identical time, a JSON line manifest file with one line per picture is created with details about uncooked and thumbnail photos from the batch. Subsequent, we use Amazon Textract to extract textual content bounding bins within the thumbnail photos. All info produced by Amazon Textract is recorded in the identical manifest file. Lastly, we use the thumbnail photos and manifest information to coach a mannequin, which is later deployed as a SageMaker endpoint.
Auto-labeling pipeline
We developed an auto-labeling pipeline designed to carry out the next features:
- Run periodic batch inference on an unlabeled dataset.
- Filter outcomes primarily based on a particular uncertainty sampling technique.
- Set off a SageMaker Floor Reality job to label the sampled photos utilizing a human workforce.
- Add newly labeled photos to the coaching dataset for subsequent mannequin refinement.
The uncertainty sampling technique reduces the variety of photos despatched to the human labeling job by deciding on photos that might seemingly contribute probably the most to bettering mannequin accuracy. As a result of human labeling is an costly job, such sampling is a vital price discount method. We help 4 sampling methods, which could be chosen as a parameter saved in Parameter Store, a functionality of AWS Systems Manager:
- Least confidence
- Margin confidence
- Ratio of confidence
- Entropy
All the auto-labeling workflow was applied with AWS Step Functions, which orchestrates the processing job (known as the elastic endpoint for batch inference), uncertainty sampling, and SageMaker Floor Reality. The next diagram illustrates the Step Features workflow.

Price-efficiency
The principle issue influencing labeling prices is handbook annotation. Earlier than deploying this resolution, the United crew had to make use of a rule-based strategy, which required costly handbook information annotation and third-party parsing OCR strategies. With our resolution, United diminished their handbook labeling workload by manually labeling solely photos that might outcome within the largest mannequin enhancements. As a result of the framework is model-agnostic, it may be utilized in different comparable situations, extending its worth past passport photos to a wider set of paperwork.
We carried out a price evaluation primarily based on the next assumptions:
- Every batch comprises 1,000 photos
- Coaching is carried out utilizing an mlg4dn.16xlarge occasion
- Inference is carried out on an mlg4dn.xlarge occasion
- Coaching is finished after every batch with 10% of annotated labels
- Every spherical of coaching ends in the next accuracy enhancements:
- 50% after the primary batch
- 25% after the second batch
- 10% after the third batch
Our evaluation reveals that coaching price stays fixed and excessive with out energetic studying. Incorporating energetic studying ends in exponentially lowering prices with every new batch of knowledge.
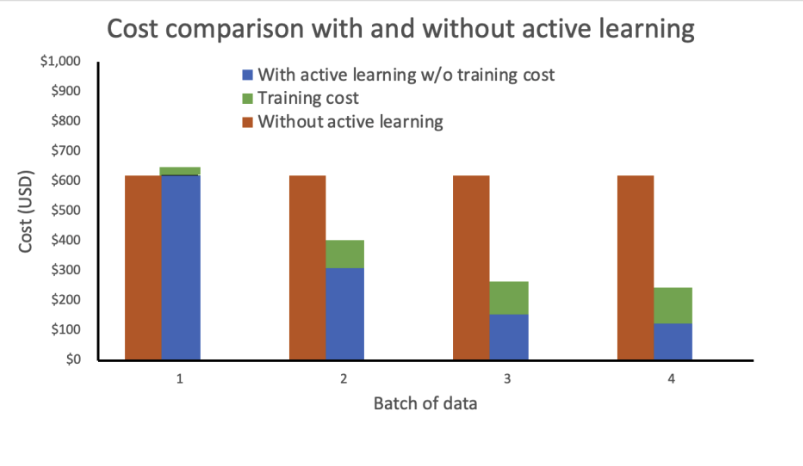
We additional diminished prices by deploying the inference endpoint as an elastic endpoint by including an auto scaling coverage. The endpoint assets can scale up or down between zero and a configured most variety of situations.
Last resolution structure
Our focus was to assist the United crew meet their purposeful necessities whereas constructing a scalable and versatile cloud software. The ML Options Lab crew developed the whole production-ready resolution with assist of AWS CDK, automating administration and provisioning of all cloud assets and providers. The ultimate cloud software was deployed as a single AWS CloudFormation stack with 4 nested stacks, every represented a single purposeful element.
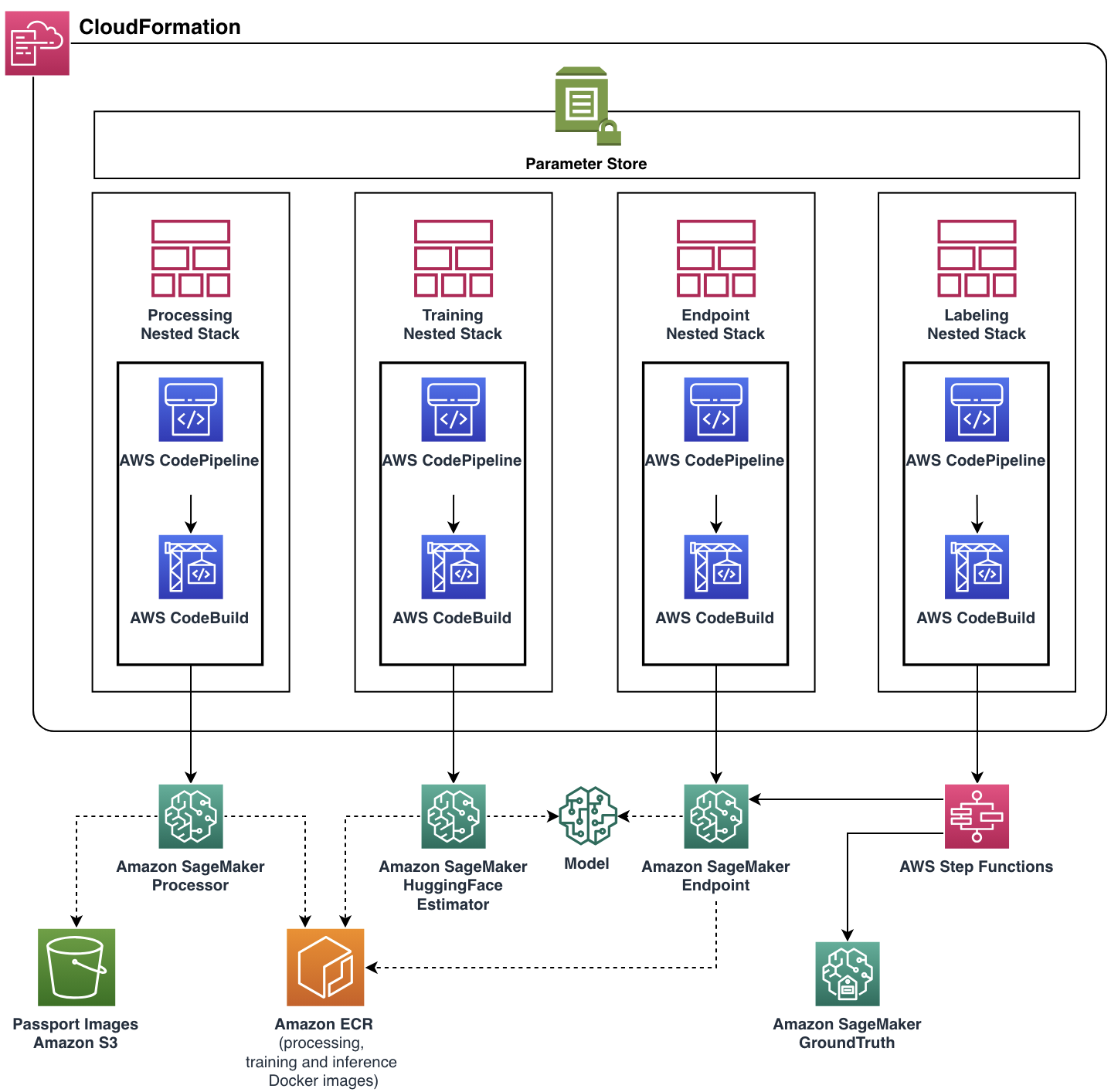
Nearly each pipeline characteristic, together with Docker photos, endpoint auto scaling coverage, and extra, was parameterized by Parameter Retailer. With such flexibility, the identical pipeline occasion might be run with a broad vary of settings, including the power to experiment.
Conclusion
On this submit, we mentioned how United Airways, in collaboration with the ML Options Lab, constructed an energetic studying framework on AWS to automate the processing of passenger paperwork. The answer had nice affect on two essential facets of United’s automation objectives:
- Reusability – Because of the modular design and model-agnostic implementation, United Airways can reuse this resolution on nearly every other auto-labeling ML use case
- Recurring price discount – By intelligently combining handbook and auto-labeling processes, the United crew can cut back common labeling prices and change costly third-party labeling providers
In case you are all for implementing an analogous resolution or need to study extra in regards to the ML Options Lab, contact your account supervisor or go to us at Amazon Machine Learning Solutions Lab.
Concerning the Authors
 Xin Gu is the Lead Knowledge Scientist – Machine Studying at United Airways’ Superior Analytics and Innovation division. She contributed considerably to designing machine-learning-assisted doc understanding automation and performed a key function in increasing information annotation energetic studying workflows throughout various duties and fashions. Her experience lies in elevating AI efficacy and effectivity, reaching exceptional progress within the subject of clever technological developments at United Airways.
Xin Gu is the Lead Knowledge Scientist – Machine Studying at United Airways’ Superior Analytics and Innovation division. She contributed considerably to designing machine-learning-assisted doc understanding automation and performed a key function in increasing information annotation energetic studying workflows throughout various duties and fashions. Her experience lies in elevating AI efficacy and effectivity, reaching exceptional progress within the subject of clever technological developments at United Airways.
 Jon Nelson is the Senior Supervisor of Knowledge Science and Machine Studying at United Airways.
Jon Nelson is the Senior Supervisor of Knowledge Science and Machine Studying at United Airways.
 Alex Goryainov is Machine Studying Engineer at Amazon AWS. He builds structure and implements core parts of energetic studying and auto-labeling pipeline powered by AWS CDK. Alex is an skilled in MLOps, cloud computing structure, statistical information evaluation and huge scale information processing.
Alex Goryainov is Machine Studying Engineer at Amazon AWS. He builds structure and implements core parts of energetic studying and auto-labeling pipeline powered by AWS CDK. Alex is an skilled in MLOps, cloud computing structure, statistical information evaluation and huge scale information processing.
 Vishal Das is an Utilized Scientist on the Amazon ML Options Lab. Previous to MLSL, Vishal was a Options Architect, Vitality, AWS. He obtained his PhD in Geophysics with a PhD minor in Statistics from Stanford College. He’s dedicated to working with clients in serving to them assume huge and ship enterprise outcomes. He’s an skilled in machine studying and its software in fixing enterprise issues.
Vishal Das is an Utilized Scientist on the Amazon ML Options Lab. Previous to MLSL, Vishal was a Options Architect, Vitality, AWS. He obtained his PhD in Geophysics with a PhD minor in Statistics from Stanford College. He’s dedicated to working with clients in serving to them assume huge and ship enterprise outcomes. He’s an skilled in machine studying and its software in fixing enterprise issues.
 Tianyi Mao is an Utilized Scientist at AWS primarily based out of Chicago space. He has 5+ years of expertise in constructing machine studying and deep studying options and focuses on pc imaginative and prescient and reinforcement studying with human feedbacks. He enjoys working with clients to grasp their challenges and remedy them by creating progressive options utilizing AWS providers.
Tianyi Mao is an Utilized Scientist at AWS primarily based out of Chicago space. He has 5+ years of expertise in constructing machine studying and deep studying options and focuses on pc imaginative and prescient and reinforcement studying with human feedbacks. He enjoys working with clients to grasp their challenges and remedy them by creating progressive options utilizing AWS providers.
 Yunzhi Shi is an Utilized Scientist on the Amazon ML Options Lab, the place he works with clients throughout totally different business verticals to assist them ideate, develop, and deploy AI/ML options constructed on AWS Cloud providers to resolve their enterprise challenges. He has labored with clients in automotive, geospatial, transportation, and manufacturing. Yunzhi obtained his Ph.D. in Geophysics from The College of Texas at Austin.
Yunzhi Shi is an Utilized Scientist on the Amazon ML Options Lab, the place he works with clients throughout totally different business verticals to assist them ideate, develop, and deploy AI/ML options constructed on AWS Cloud providers to resolve their enterprise challenges. He has labored with clients in automotive, geospatial, transportation, and manufacturing. Yunzhi obtained his Ph.D. in Geophysics from The College of Texas at Austin.
 Diego Socolinsky is a Senior Utilized Science Supervisor with the AWS Generative AI Innovation Heart, the place he leads the supply crew for the Jap US and Latin America areas. He has over twenty years of expertise in machine studying and pc imaginative and prescient, and holds a PhD diploma in arithmetic from The Johns Hopkins College.
Diego Socolinsky is a Senior Utilized Science Supervisor with the AWS Generative AI Innovation Heart, the place he leads the supply crew for the Jap US and Latin America areas. He has over twenty years of expertise in machine studying and pc imaginative and prescient, and holds a PhD diploma in arithmetic from The Johns Hopkins College.
 Xin Chen is presently the Head of Folks Science Options Lab at Amazon Folks eXperience Expertise (PXT, aka HR) Central Science. He leads a crew of utilized scientists to construct manufacturing grade science options to proactively establish and launch mechanisms and course of enhancements. Beforehand, he was head of Central US, Larger China Area, LATAM and Automotive Vertical in AWS Machine Studying Options Lab. He helped AWS clients establish and construct machine studying options to handle their group’s highest return-on-investment machine studying alternatives. Xin is adjunct college at Northwestern College and Illinois Institute of Expertise. He obtained his PhD in Laptop Science and Engineering on the College of Notre Dame.
Xin Chen is presently the Head of Folks Science Options Lab at Amazon Folks eXperience Expertise (PXT, aka HR) Central Science. He leads a crew of utilized scientists to construct manufacturing grade science options to proactively establish and launch mechanisms and course of enhancements. Beforehand, he was head of Central US, Larger China Area, LATAM and Automotive Vertical in AWS Machine Studying Options Lab. He helped AWS clients establish and construct machine studying options to handle their group’s highest return-on-investment machine studying alternatives. Xin is adjunct college at Northwestern College and Illinois Institute of Expertise. He obtained his PhD in Laptop Science and Engineering on the College of Notre Dame.




