Superb-tune Falcon 7B and different LLMs on Amazon SageMaker with @distant decorator

As we speak, generative AI fashions cowl a wide range of duties from textual content summarization, Q&A, and picture and video era. To enhance the standard of output, approaches like n-short studying, Immediate engineering, Retrieval Augmented Generation (RAG) and positive tuning are used. Superb-tuning permits you to modify these generative AI fashions to realize improved efficiency in your domain-specific duties.
With Amazon SageMaker, now you may run a SageMaker coaching job just by annotating your Python code with @remote decorator. The SageMaker Python SDK routinely interprets your present workspace surroundings, and any related knowledge processing code and datasets, into an SageMaker coaching job that runs on the coaching platform. This has the benefit of writing the code in a extra pure, object-oriented method, and nonetheless makes use of SageMaker capabilities to run coaching jobs on a distant cluster with minimal adjustments.
On this submit, we showcase learn how to fine-tune a Falcon-7B Basis Fashions (FM) utilizing @distant decorator from SageMaker Python SDK. It additionally makes use of Hugging Face’s parameter-efficient fine-tuning (PEFT) library and quantization strategies by way of bitsandbytes to help fine-tuning. The code offered on this weblog can be used to fine-tune different FMs, equivalent to Llama-2 13b.
The total precision representations of this mannequin may need challenges to suit into reminiscence on a single and even a number of Graphic Processing Units (GPUs) — or could even want an even bigger occasion. Therefore, so as to fine-tune this mannequin with out growing value, we use the method often known as Quantized LLMs with Low-Rank Adapters (QLoRA). QLoRA is an environment friendly fine-tuning method that reduces reminiscence utilization of LLMs whereas sustaining excellent efficiency.
Benefits of utilizing @distant decorator
Earlier than going additional, let’s perceive how distant decorator improves developer productiveness whereas working with SageMaker:
- @distant decorator triggers a coaching job straight utilizing native python code, with out the specific invocation of SageMaker Estimators and SageMaker enter channels
- Low barrier for entry for builders coaching fashions on SageMaker.
- No want to change Integrated development environments (IDEs). Proceed writing code in your alternative of IDE and invoke SageMaker coaching jobs.
- No have to study containers. Proceed offering dependencies in a
necessities.txtand provide that to distant decorator.
Stipulations
An AWS account is required with an AWS Identity and Access Management (AWS IAM) role that has permissions to handle sources created as a part of the answer. For particulars, consult with Creating an AWS account.
On this submit, we use Amazon SageMaker Studio with the Knowledge Science 3.0 picture and a ml.t3.medium quick launch occasion. Nonetheless, you should use any built-in growth surroundings (IDE) of your alternative. You simply have to arrange your AWS Command Line Interface (AWS CLI) credentials appropriately. For extra data, consult with Configure the AWS CLI.
For fine-tuning, the Falcon-7B, an ml.g5.12xlarge occasion is used on this submit. Please guarantee enough capability for this occasion in AWS account.
It’s essential to clone this Github repository for replicating the answer demonstrated on this submit.
Answer overview
- Set up pre-requisites to positive tuning the Falcon-7B mannequin
- Arrange distant decorator configurations
- Preprocess the dataset containing AWS providers FAQs
- Superb-tune Falcon-7B on AWS providers FAQs
- Take a look at the fine-tune fashions on pattern questions associated to AWS providers
1. Set up stipulations to positive tuning the Falcon-7B mannequin
Launch the pocket book falcon-7b-qlora-remote-decorator_qa.ipynb in SageMaker Studio by deciding on the Image as Knowledge Science and Kernel as Python 3. Set up all of the required libraries talked about within the necessities.txt. Few of the libraries have to be put in on the pocket book occasion itself. Carry out different operations wanted for dataset processing and triggering a SageMaker coaching job.
2. Setup distant decorator configurations
Create a configuration file the place all of the configurations associated to Amazon SageMaker coaching job are specified. This file is learn by @distant decorator whereas operating the coaching job. This file accommodates settings like dependencies, coaching picture, occasion, and the execution position for use for coaching job. For an in depth reference of all of the settings supported by config file, try Configuring and using defaults with the SageMaker Python SDK.
It’s not obligatory to make use of the config.yaml file so as to work with the @distant decorator. That is only a cleaner method to provide all configurations to the @distant decorator. This retains SageMaker and AWS associated parameters outdoors of code with a one time effort for establishing the config file used throughout the crew members. All of the configurations is also provided straight within the decorator arguments, however that reduces readability and maintainability of adjustments in the long term. Additionally, the configuration file will be created by an administrator and shared with all of the customers in an surroundings.
Preprocess the dataset containing AWS providers FAQs
Subsequent step is to load and preprocess the dataset to make it prepared for coaching job. First, allow us to take a look on the dataset:
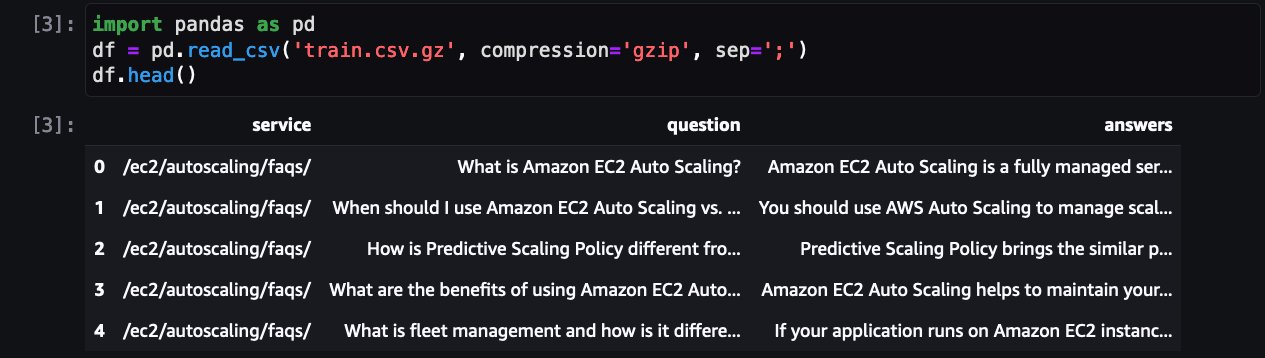
It reveals FAQ for one of many AWS providers. Along with QLoRA, bitsanbytes is used to transform to 4-bit precision to quantize frozen LLM to 4-bit and connect LoRA adapters on it.
Create a immediate template to transform every FAQ pattern to a immediate format:
Subsequent step is to transform the inputs (textual content) to token IDs. That is achieved by a Hugging Face Transformers Tokenizer.
Now merely use the prompt_template perform to transform all of the FAQ to immediate format and arrange practice and take a look at datasets.

4. Superb tune Falcon-7B on AWS providers FAQs
Now you may put together the coaching script and outline the coaching perform train_fn and put @distant decorator on the perform.
The coaching perform does the next:
- tokenizes and chunks the dataset
- arrange
BitsAndBytesConfig, which specifies the mannequin ought to be loaded in 4-bit however whereas computation ought to be transformed tobfloat16. - Load the mannequin
- Discover goal modules and replace the required matrices by utilizing the utility methodology
find_all_linear_names - Create LoRA configurations that specify rating of replace matrices (
s), scaling issue (lora_alpha), the modules to use the LoRA replace matrices (target_modules), dropout chance for Lora layers(lora_dropout),task_type, and so forth. - Begin the coaching and analysis
And invoke the train_fn()
The tuning job can be operating on the Amazon SageMaker coaching cluster. Watch for tuning job to complete.
5. Take a look at the positive tune fashions on pattern questions associated to AWS providers
Now, it’s time to run some checks on the mannequin. First, allow us to load the mannequin:
Now load a pattern query from the coaching dataset to see the unique reply after which ask the identical query from the tuned mannequin to see the reply compared.
Here’s a pattern a query from coaching set and the unique reply:
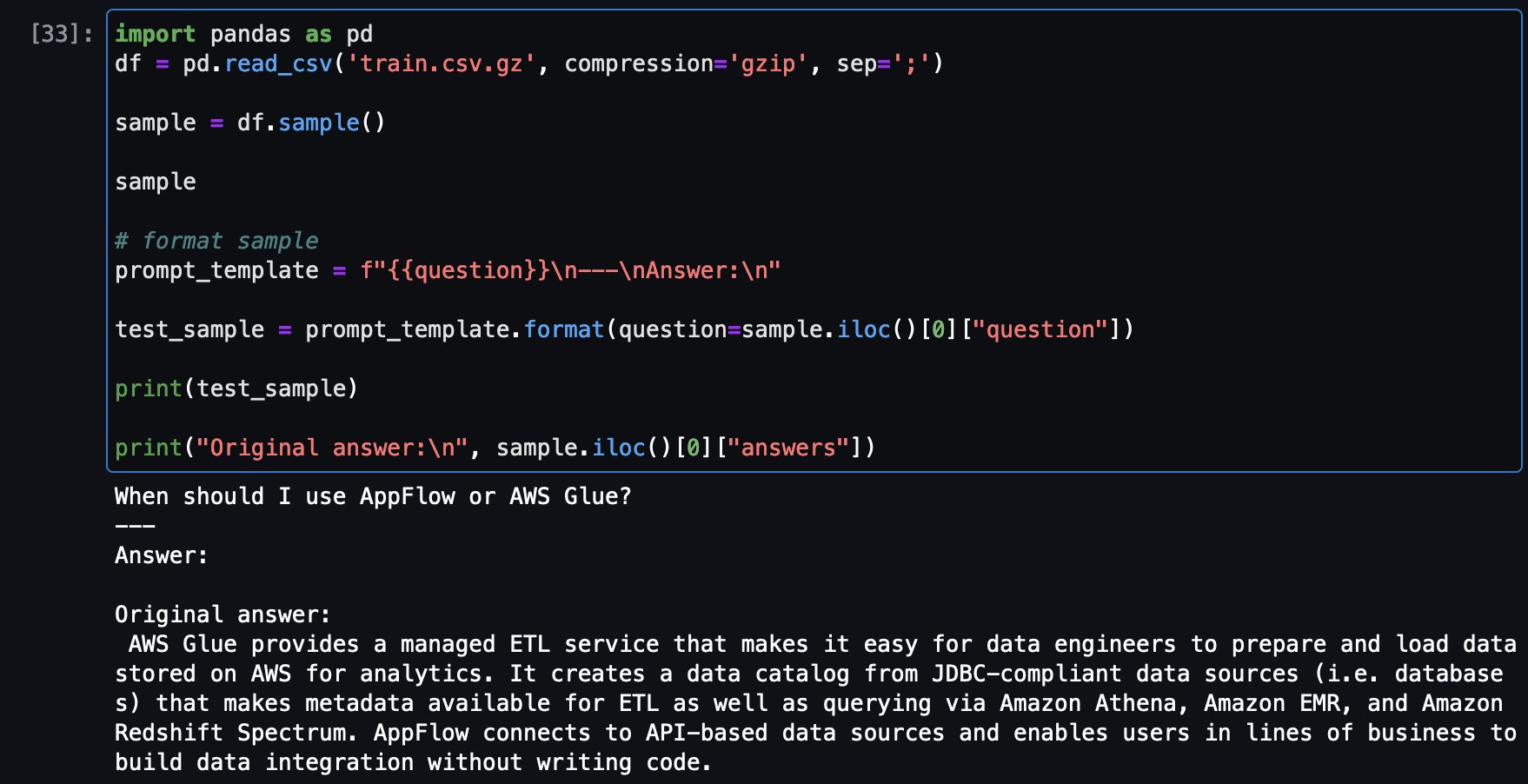
Now, similar query being requested to tuned Falcon-7B mannequin:
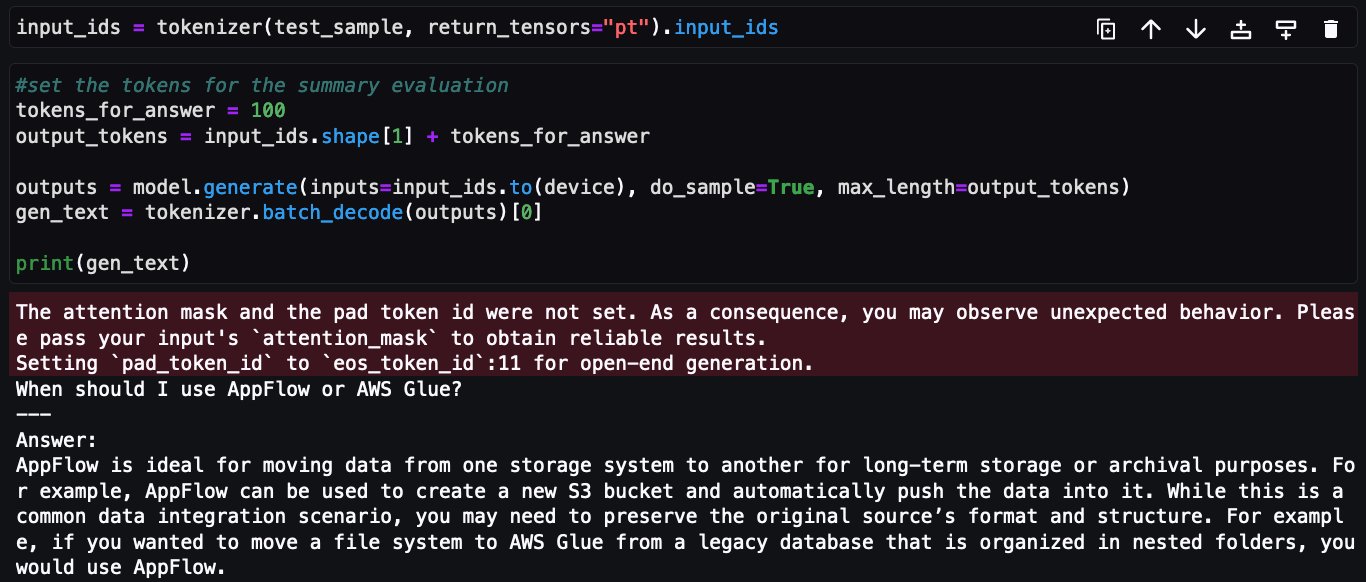
This concludes the implementation of positive tuning Falcon-7B on AWS providers FAQ dataset utilizing @distant decorator from Amazon SageMaker Python SDK.
Cleansing up
Full the next steps to scrub up your sources:
- Shut down the Amazon SageMaker Studio situations to keep away from incurring extra prices.
- Clear up your Amazon Elastic File System (Amazon EFS) listing by clearing the Hugging Face cache listing:
Conclusion
On this submit, we confirmed you learn how to successfully use the @distant decorator’s capabilities to fine-tune Falcon-7B mannequin utilizing QLoRA, Hugging Face PEFT with bitsandbtyes with out making use of important adjustments within the coaching pocket book, and used Amazon SageMaker capabilities to run coaching jobs on a distant cluster.
All of the code proven as a part of this submit to fine-tune Falcon-7B is out there within the GitHub repository. The repository additionally accommodates pocket book exhibiting learn how to fine-tune Llama-13B.
As a subsequent step, we encourage you to take a look at the @remote decorator functionality and Python SDK API and use it in your alternative of surroundings and IDE. Extra examples can be found within the amazon-sagemaker-examples repository to get you began shortly. You can even try the next posts:
Concerning the Authors
 Bruno Pistone is an AI/ML Specialist Options Architect for AWS based mostly in Milan. He works with massive prospects serving to them to deeply perceive their technical wants and design AI and Machine Studying options that make the very best use of the AWS Cloud and the Amazon Machine Studying stack. His experience embody: Machine Studying finish to finish, Machine Studying Industrialization, and Generative AI. He enjoys spending time together with his buddies and exploring new locations, in addition to travelling to new locations.
Bruno Pistone is an AI/ML Specialist Options Architect for AWS based mostly in Milan. He works with massive prospects serving to them to deeply perceive their technical wants and design AI and Machine Studying options that make the very best use of the AWS Cloud and the Amazon Machine Studying stack. His experience embody: Machine Studying finish to finish, Machine Studying Industrialization, and Generative AI. He enjoys spending time together with his buddies and exploring new locations, in addition to travelling to new locations.
 Vikesh Pandey is a Machine Studying Specialist Options Architect at AWS, serving to prospects from monetary industries design and construct options on generative AI and ML. Outdoors of labor, Vikesh enjoys making an attempt out totally different cuisines and taking part in out of doors sports activities.
Vikesh Pandey is a Machine Studying Specialist Options Architect at AWS, serving to prospects from monetary industries design and construct options on generative AI and ML. Outdoors of labor, Vikesh enjoys making an attempt out totally different cuisines and taking part in out of doors sports activities.





