Elevating the generative AI expertise: Introducing streaming assist in Amazon SageMaker internet hosting

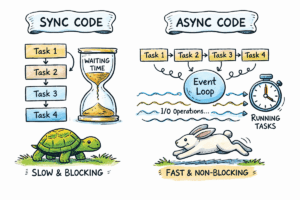
We’re excited to announce the supply of response streaming by Amazon SageMaker real-time inference. Now you possibly can repeatedly stream inference responses again to the consumer when utilizing SageMaker real-time inference that will help you construct interactive experiences for generative AI functions corresponding to chatbots, digital assistants, and music turbines. With this new function, you can begin streaming the responses instantly once they’re accessible as a substitute of ready for the complete response to be generated. This lowers the time-to-first-byte to your generative AI functions.
On this put up, we’ll present methods to construct a streaming net software utilizing SageMaker real-time endpoints with the brand new response streaming function for an interactive chat use case. We use Streamlit for the pattern demo software UI.
Resolution overview
To get responses streamed again from SageMaker, you need to use our new InvokeEndpointWithResponseStream API. It helps improve buyer satisfaction by delivering a quicker time-to-first-response-byte. This discount in customer-perceived latency is especially essential for functions constructed with generative AI fashions, the place instant processing is valued over ready for the complete payload. Furthermore, it introduces a sticky session that may allow continuity in interactions, benefiting use instances corresponding to chatbots, to create extra pure and environment friendly person experiences.
The implementation of response streaming in SageMaker real-time endpoints is achieved by HTTP 1.1 chunked encoding, which is a mechanism for sending a number of responses. This can be a HTTP commonplace that helps binary content material and is supported by most consumer/server frameworks. HTTP chunked encoding helps each textual content and picture information streaming, which suggests the fashions hosted on SageMaker endpoints can ship again streamed responses as textual content or picture, corresponding to Falcon, Llama 2, and Stable Diffusion fashions. By way of safety, each the enter and output are secured utilizing TLS utilizing AWS Sigv4 Auth. Different streaming strategies like Server-Sent Events (SSE) are additionally carried out utilizing the identical HTTP chunked encoding mechanism. To make the most of the brand new streaming API, you must be certain that the mannequin container returns the streamed response as chunked encoded information.
The next diagram illustrates the high-level structure for response streaming with a SageMaker inference endpoint.

One of many use instances that may profit from streaming response is generative AI model-powered chatbots. Historically, customers ship a question and await the complete response to be generated earlier than receiving a solution. This might take treasured seconds and even longer, which may doubtlessly degrade the efficiency of the appliance. With response streaming, the chatbot can start sending again partial inference outcomes as they’re generated. Which means customers can see the preliminary response nearly instantaneously, even because the AI continues refining its reply within the background. This creates a seamless and fascinating dialog move, the place customers really feel like they’re chatting with an AI that understands and responds in actual time.
On this put up, we showcase two container choices to create a SageMaker endpoint with response streaming: utilizing an AWS Large Model Inference (LMI) and Hugging Face Text Generation Inference (TGI) container. Within the following sections, we stroll you thru the detailed implementation steps to deploy and take a look at the Falcon-7B-Instruct mannequin utilizing each LMI and TGI containers on SageMaker. We selected Falcon 7B for instance, however any mannequin can make the most of this new streaming function.
Stipulations
You want an AWS account with an AWS Identity and Access Management (IAM) function with permissions to handle sources created as a part of the answer. For particulars, consult with Creating an AWS account. If that is your first time working with Amazon SageMaker Studio, you first must create a SageMaker domain. Moreover, you might must request a service quota improve for the corresponding SageMaker internet hosting situations. For the Falcon-7B-Instruct mannequin, we use an ml.g5.2xlarge SageMaker internet hosting occasion. For internet hosting a Falcon-40B-Instruct mannequin, we use an ml.g5.48xlarge SageMaker internet hosting occasion. You’ll be able to request a quota improve from the Service Quotas UI. For extra data, consult with Requesting a quota increase.
Possibility 1: Deploy a real-time streaming endpoint utilizing an LMI container
The LMI container is among the Deep Studying Containers for giant mannequin inference hosted by SageMaker to facilitate internet hosting massive language fashions (LLMs) on AWS infrastructure for low-latency inference use instances. The LMI container makes use of Deep Java Library (DJL) Serving, which is an open-source, high-level, engine-agnostic Java framework for deep studying. With these containers, you need to use corresponding open-source libraries corresponding to DeepSpeed, Accelerate, Transformers-neuronx, and FasterTransformer to partition mannequin parameters utilizing mannequin parallelism strategies to make use of the reminiscence of a number of GPUs or accelerators for inference. For extra particulars on the advantages utilizing the LMI container to deploy massive fashions on SageMaker, consult with Deploy large models at high performance using FasterTransformer on Amazon SageMaker and Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference. You may as well discover extra examples of internet hosting open-source LLMs on SageMaker utilizing the LMI containers on this GitHub repo.
For the LMI container, we anticipate the next artifacts to assist arrange the mannequin for inference:
- serving.properties (required) – Defines the mannequin server settings
- mannequin.py (elective) – A Python file to outline the core inference logic
- necessities.txt (elective) – Any extra pip wheel might want to set up
LMI containers can be utilized to host fashions with out offering your individual inference code. That is extraordinarily helpful when there isn’t a customized preprocessing of the enter information or postprocessing of the mannequin’s predictions. We use the next configuration:
- For this instance, we host the Falcon-7B-Instruct mannequin. We have to create a
serving.propertiesconfiguration file with our desired internet hosting choices and bundle it up right into a tar.gz artifact. Response streaming will be enabled in DJL Serving by setting theenable_streamingchoice within theserving.propertiesfile. For all of the supported parameters, consult with Streaming Python configuration. - On this instance, we use the default handlers in DJL Serving to stream responses, so we solely care about sending requests and parsing the output response. You may as well present an
entrypointcode with a customized handler in amannequin.pyfile to customise enter and output handlers. For extra particulars on the customized handler, consult with Custom model.py handler. - As a result of we’re internet hosting the Falcon-7B-Instruct mannequin on a single GPU occasion (ml.g5.2xlarge), we set
choice.tensor_parallel_degreeto 1. In the event you plan to run in a number of GPUs, use this to set the number of GPUs per worker. - We use
choice.output_formatterto regulate the output content material kind. The default output content material kind issoftware/json, so in case your software requires a special output, you possibly can overwrite this worth. For extra data on the accessible choices, consult with Configurations and settings and All DJL configuration options.
To create the SageMaker mannequin, retrieve the container picture URI:
Use the SageMaker Python SDK to create the SageMaker mannequin and deploy it to a SageMaker real-time endpoint utilizing the deploy methodology:
When the endpoint is in service, you need to use the InvokeEndpointWithResponseStream API name to invoke the mannequin. This API permits the mannequin to reply as a stream of elements of the total response payload. This allows fashions to reply with responses of bigger dimension and permits faster-time-to-first-byte for fashions the place there’s a important distinction between the era of the primary and final byte of the response.
The response content material kind proven in x-amzn-sagemaker-content-type for the LMI container is software/jsonlines as specified within the mannequin properties configuration. As a result of it’s a part of the common data formats supported for inference, we are able to use the default deserializer supplied by the SageMaker Python SDK to deserialize the JSON traces information. We create a helper LineIterator class to parse the response stream acquired from the inference request:
With the category within the previous code, every time a response is streamed, it is going to return a binary string (for instance, b'{"outputs": [" a"]}n') that may be deserialized once more right into a Python dictionary utilizing JSON bundle. We will use the next code to iterate by every streamed line of textual content and return textual content response:
The next screenshot exhibits what it might seem like should you invoked the mannequin by the SageMaker pocket book utilizing an LMI container.

Possibility 2: Implement a chatbot utilizing a Hugging Face TGI container
Within the earlier part, you noticed methods to deploy the Falcon-7B-Instruct mannequin utilizing an LMI container. On this part, we present methods to do the identical utilizing a Hugging Face Textual content Technology Inference (TGI) container on SageMaker. TGI is an open supply, purpose-built answer for deploying LLMs. It incorporates optimizations together with tensor parallelism for quicker multi-GPU inference, dynamic batching to spice up total throughput, and optimized transformers code utilizing flash-attention for standard mannequin architectures together with BLOOM, T5, GPT-NeoX, StarCoder, and LLaMa.
TGI deep studying containers assist token streaming utilizing Server-Sent Events (SSE). With token streaming, the server can begin answering after the primary prefill move instantly, with out ready for all of the era to be carried out. For very lengthy queries, this implies purchasers can begin to see one thing taking place orders of magnitude earlier than the work is completed. The next diagram exhibits a high-level end-to-end request/response workflow for internet hosting LLMs on a SageMaker endpoint utilizing the TGI container.

To deploy the Falcon-7B-Instruct mannequin on a SageMaker endpoint, we use the HuggingFaceModel class from the SageMaker Python SDK. We begin by setting our parameters as follows:
In comparison with deploying common Hugging Face fashions, we first must retrieve the container URI and supply it to our HuggingFaceModel mannequin class with image_uri pointing to the picture. To retrieve the brand new Hugging Face LLM DLC in SageMaker, we are able to use the get_huggingface_llm_image_uri methodology supplied by the SageMaker SDK. This methodology permits us to retrieve the URI for the specified Hugging Face LLM DLC primarily based on the desired backend, session, Area, and model. For extra particulars on the accessible variations, consult with HuggingFace Text Generation Inference Containers.
We then create the HuggingFaceModel and deploy it to SageMaker utilizing the deploy methodology:
The principle distinction in comparison with the LMI container is that you just allow response streaming whenever you invoke the endpoint by supplying stream=true as a part of the invocation request payload. The next code is an instance of the payload used to invoke the TGI container with streaming:
Then you possibly can invoke the endpoint and obtain a streamed response utilizing the next command:
The response content material kind proven in x-amzn-sagemaker-content-type for the TGI container is textual content/event-stream. We use StreamDeserializer to deserialize the response into the EventStream class and parse the response physique utilizing the identical LineIterator class as that used within the LMI container part.
Observe that the streamed response from the TGI containers will return a binary string (for instance, b`information:{"token": {"textual content": " sometext"}}`), which will be deserialized once more right into a Python dictionary utilizing a JSON bundle. We will use the next code to iterate by every streamed line of textual content and return a textual content response:
The next screenshot exhibits what it might seem like should you invoked the mannequin by the SageMaker pocket book utilizing a TGI container.

Run the chatbot app on SageMaker Studio
On this use case, we construct a dynamic chatbot on SageMaker Studio utilizing Streamlit, which invokes the Falcon-7B-Instruct mannequin hosted on a SageMaker real-time endpoint to offer streaming responses. First, you possibly can take a look at that the streaming responses work within the pocket book as proven within the earlier part. Then, you possibly can arrange the Streamlit software within the SageMaker Studio JupyterServer terminal and entry the chatbot UI out of your browser by finishing the next steps:
- Open a system terminal in SageMaker Studio.
- On the highest menu of the SageMaker Studio console, select File, then New, then Terminal.

- Set up the required Python packages which can be specified within the requirements.txt file:
- Arrange the surroundings variable with the endpoint title deployed in your account:
- Launch the Streamlit app from the
streamlit_chatbot_<LMI or TGI>.pyfile, which is able to robotically replace the endpoint names within the script primarily based on the surroundings variable that was arrange earlier: - To entry the Streamlit UI, copy your SageMaker Studio URL to a different tab in your browser and exchange
lab?withproxy/[PORT NUMBER]/. As a result of we specified the server port to 6006, the URL ought to look as follows:
Change the area ID and Area within the previous URL together with your account and Area to entry the chatbot UI. You could find some urged prompts within the left pane to get began.
The next demo exhibits how response streaming revolutionizes the person expertise. It may possibly make interactions really feel fluid and responsive, finally enhancing person satisfaction and engagement. Discuss with the GitHub repo for extra particulars of the chatbot implementation.

Clear up
While you’re carried out testing the fashions, as a greatest observe, delete the endpoint to save lots of prices if the endpoint is now not required:
Conclusion
On this put up, we supplied an summary of constructing functions with generative AI, the challenges, and the way SageMaker real-time response streaming helps you handle these challenges. We showcased methods to construct a chatbot software to deploy the Falcon-7B-Instruct mannequin to make use of response streaming utilizing each SageMaker LMI and HuggingFace TGI containers utilizing an instance accessible on GitHub.
Begin constructing your individual cutting-edge streaming functions with LLMs and SageMaker immediately! Attain out to us for professional steering and unlock the potential of huge mannequin streaming to your tasks.
In regards to the Authors
 Raghu Ramesha is a Senior ML Options Architect with the Amazon SageMaker Service staff. He focuses on serving to prospects construct, deploy, and migrate ML manufacturing workloads to SageMaker at scale. He makes a speciality of machine studying, AI, and laptop imaginative and prescient domains, and holds a grasp’s diploma in Pc Science from UT Dallas. In his free time, he enjoys touring and pictures.
Raghu Ramesha is a Senior ML Options Architect with the Amazon SageMaker Service staff. He focuses on serving to prospects construct, deploy, and migrate ML manufacturing workloads to SageMaker at scale. He makes a speciality of machine studying, AI, and laptop imaginative and prescient domains, and holds a grasp’s diploma in Pc Science from UT Dallas. In his free time, he enjoys touring and pictures.
 Abhi Shivaditya is a Senior Options Architect at AWS, working with strategic international enterprise organizations to facilitate the adoption of AWS providers in areas corresponding to synthetic intelligence, distributed computing, networking, and storage. His experience lies in deep studying within the domains of pure language processing (NLP) and laptop imaginative and prescient. Abhi assists prospects in deploying high-performance machine studying fashions effectively inside the AWS ecosystem.
Abhi Shivaditya is a Senior Options Architect at AWS, working with strategic international enterprise organizations to facilitate the adoption of AWS providers in areas corresponding to synthetic intelligence, distributed computing, networking, and storage. His experience lies in deep studying within the domains of pure language processing (NLP) and laptop imaginative and prescient. Abhi assists prospects in deploying high-performance machine studying fashions effectively inside the AWS ecosystem.
 Alan Tan is a Senior Product Supervisor with SageMaker, main efforts on massive mannequin inference. He’s obsessed with making use of machine studying to the world of analytics. Outdoors of labor, he enjoys the outside.
Alan Tan is a Senior Product Supervisor with SageMaker, main efforts on massive mannequin inference. He’s obsessed with making use of machine studying to the world of analytics. Outdoors of labor, he enjoys the outside.
 Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS primarily based in Sydney, Australia. She helps enterprise prospects construct options utilizing state-of-the-art AI/ML instruments on AWS and offers steering on architecting and implementing ML options with greatest practices. In her spare time, she likes to discover nature and spend time with household and buddies.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS primarily based in Sydney, Australia. She helps enterprise prospects construct options utilizing state-of-the-art AI/ML instruments on AWS and offers steering on architecting and implementing ML options with greatest practices. In her spare time, she likes to discover nature and spend time with household and buddies.
 Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialised in machine studying and Amazon SageMaker. He’s obsessed with serving to prospects remedy points associated to machine studying workflows and creating new options for them. Outdoors of labor, he enjoys taking part in racquet sports activities and touring.
Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialised in machine studying and Amazon SageMaker. He’s obsessed with serving to prospects remedy points associated to machine studying workflows and creating new options for them. Outdoors of labor, he enjoys taking part in racquet sports activities and touring.
 James Sanders is a Senior Software program Engineer at Amazon Net Companies. He works on the real-time inference platform for Amazon SageMaker.
James Sanders is a Senior Software program Engineer at Amazon Net Companies. He works on the real-time inference platform for Amazon SageMaker.