Mechanically generate impressions from findings in radiology stories utilizing generative AI on AWS

Radiology stories are complete, prolonged paperwork that describe and interpret the outcomes of a radiological imaging examination. In a typical workflow, the radiologist supervises, reads, and interprets the photographs, after which concisely summarizes the important thing findings. The summarization (or impression) is an important a part of the report as a result of it helps clinicians and sufferers concentrate on the vital contents of the report that comprise info for scientific decision-making. Creating a transparent and impactful impression includes far more effort than merely restating the findings. Your entire course of is due to this fact laborious, time consuming, and susceptible to error. It usually takes years of training for docs to build up sufficient experience in writing concise and informative radiology report summarizations, additional highlighting the importance of automating the method. Moreover, computerized era of report findings summarization is critical for radiology reporting. It permits translation of stories into human readable language, thereby assuaging the sufferers’ burden of studying by way of prolonged and obscure stories.
To unravel this drawback, we suggest the usage of generative AI, a sort of AI that may create new content material and concepts, together with conversations, tales, photographs, movies, and music. Generative AI is powered by machine studying (ML) fashions—very giant fashions which might be pre-trained on huge quantities of knowledge and generally known as basis fashions (FMs). Latest developments in ML (particularly the invention of the transformer-based neural community structure) have led to the rise of fashions that comprise billions of parameters or variables. The proposed answer on this put up makes use of fine-tuning of pre-trained giant language fashions (LLMs) to assist generate summarizations primarily based on findings in radiology stories.
This put up demonstrates a technique for fine-tuning publicly out there LLMs for the duty of radiology report summarization utilizing AWS providers. LLMs have demonstrated outstanding capabilities in pure language understanding and era, serving as basis fashions that may be tailored to varied domains and duties. There are important advantages to utilizing a pre-trained mannequin. It reduces computation prices, reduces carbon footprints, and lets you use state-of-the-art fashions with out having to coach one from scratch.
Our answer makes use of the FLAN-T5 XL FM, utilizing Amazon SageMaker JumpStart, which is an ML hub providing algorithms, fashions, and ML options. We reveal how one can accomplish this utilizing a pocket book in Amazon SageMaker Studio. Wonderful-tuning a pre-trained mannequin includes additional coaching on particular knowledge to enhance efficiency on a unique however associated job. This answer includes fine-tuning the FLAN-T5 XL mannequin, which is an enhanced model of T5 (Textual content-to-Textual content Switch Transformer) general-purpose LLMs. T5 reframes pure language processing (NLP) duties right into a unified text-to-text-format, in distinction to BERT-style fashions that may solely output both a category label or a span of the enter. It’s fine-tuned for a summarization job on 91,544 free-text radiology stories obtained from the MIMIC-CXR dataset.
Overview of answer
On this part, we talk about the important thing parts of our answer: selecting the technique for the duty, fine-tuning an LLM, and evaluating the outcomes. We additionally illustrate the answer structure and the steps to implement the answer.
Establish the technique for the duty
There are numerous methods to strategy the duty of automating scientific report summarization. For instance, we may use a specialised language mannequin pre-trained on scientific stories from scratch. Alternatively, we may instantly fine-tune a publicly out there general-purpose language mannequin to carry out the scientific job. Utilizing a fine-tuned domain-agnostic mannequin could also be needed in settings the place coaching a language model from scratch is just too expensive. On this answer, we reveal the latter strategy of utilizing a FLAN -T5 XL mannequin, which we fine-tune for the scientific job of summarization of radiology stories. The next diagram illustrates the mannequin workflow.

A typical radiology report is well-organized and succinct. Such stories usually have three key sections:
- Background – Offers basic details about the demographics of the affected person with important details about the affected person, scientific historical past, and related medical historical past and particulars of examination procedures
- Findings – Presents detailed examination prognosis and outcomes
- Impression – Concisely summarizes essentially the most salient findings or interpretation of the findings with an evaluation of significance and potential prognosis primarily based on the noticed abnormalities
Utilizing the findings part within the radiology stories, the answer generates the impression part, which corresponds to the docs’ summarization. The next determine is an instance of a radiology report .

Wonderful-tune a general-purpose LLM for a scientific job
On this answer, we fine-tune a FLAN-T5 XL mannequin (tuning all of the parameters of the mannequin and optimizing them for the duty). We fine-tune the mannequin utilizing the scientific area dataset MIMIC-CXR, which is a publicly out there dataset of chest radiographs. To fine-tune this mannequin by way of SageMaker Jumpstart, labeled examples should be offered within the type of {immediate, completion} pairs. On this case, we use pairs of {Findings, Impression} from the unique stories in MIMIC-CXR dataset. For inferencing, we use a immediate as proven within the following instance:
![]()
The mannequin is fine-tuned on an accelerated computing ml.p3.16xlarge occasion with 64 digital CPUs and 488 GiB reminiscence. For validation, 5% of the dataset was randomly chosen. The elapsed time of the SageMaker coaching job with fine-tuning was 38,468 seconds (roughly 11 hours).
Consider the outcomes
When the coaching is full, it’s vital to judge the outcomes. For a quantitative evaluation of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Analysis), essentially the most generally used metric for evaluating summarization. This metric compares an mechanically produced abstract towards a reference or a set of references (human-produced) abstract or translation. ROUGE1 refers back to the overlap of unigrams (every phrase) between the candidate (the mannequin’s output) and reference summaries. ROUGE2 refers back to the overlap of bigrams (two phrases) between the candidate and reference summaries. ROUGEL is a sentence-level metric and refers back to the longest frequent subsequence (LCS) between two items of textual content. It ignores newlines within the textual content. ROUGELsum is a summary-level metric. For this metric, newlines within the textual content aren’t ignored however are interpreted as sentence boundaries. The LCS is then computed between every pair of reference and candidate sentences, after which union-LCS is computed. For aggregation of those scores over a given set of reference and candidate sentences, the common is computed.
Walkthrough and structure
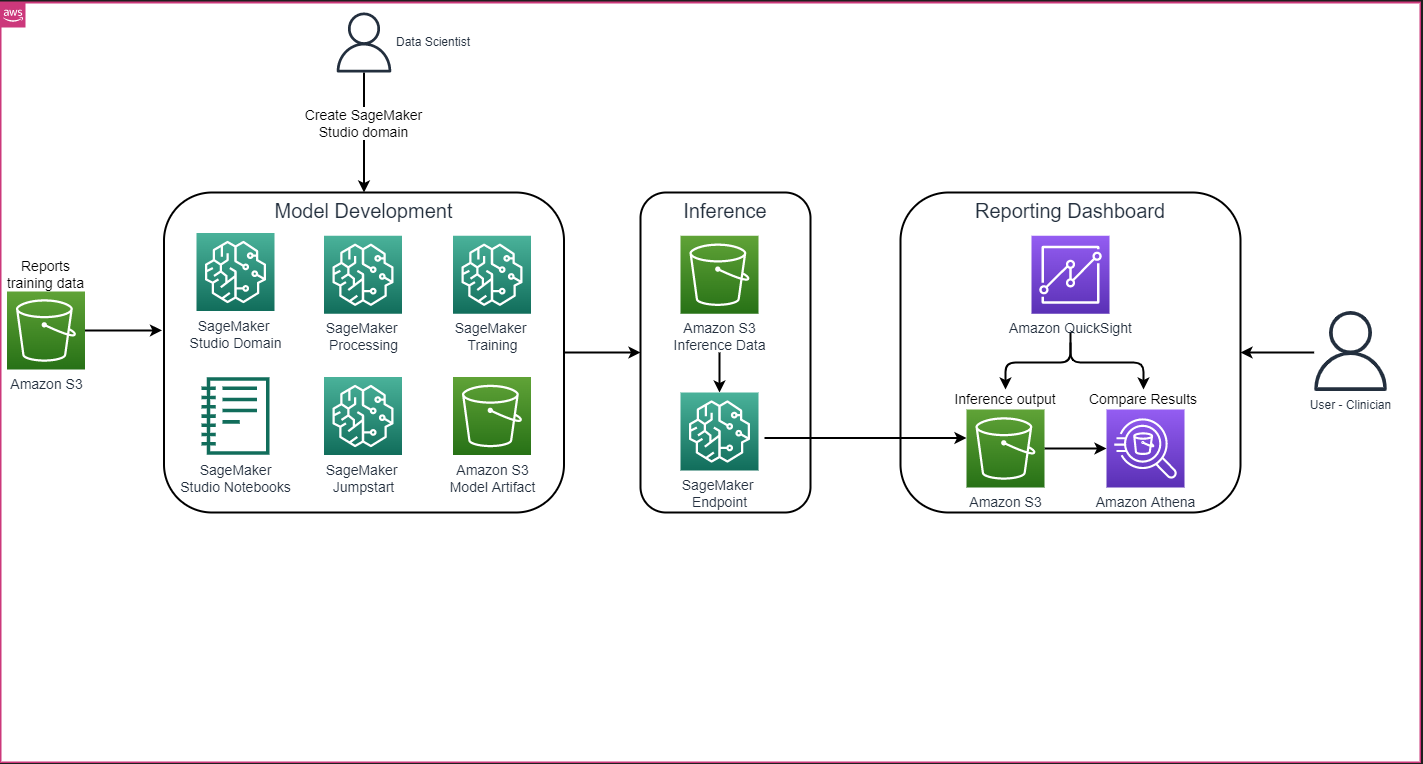
The general answer structure as proven within the following determine primarily consists of a mannequin growth atmosphere that makes use of SageMaker Studio, mannequin deployment with a SageMaker endpoint, and a reporting dashboard utilizing Amazon QuickSight.
Within the following sections, we reveal fine-tuning an LLM out there on SageMaker JumpStart for summarization of a domain-specific job by way of the SageMaker Python SDK. Particularly, we talk about the next matters:
- Steps to arrange the event atmosphere
- An outline of the radiology report datasets on which the mannequin is fine-tuned and evaluated
- An illustration of fine-tuning the FLAN-T5 XL mannequin utilizing SageMaker JumpStart programmatically with the SageMaker Python SDK
- Inferencing and analysis of the pre-trained and fine-tuned fashions
- Comparability of outcomes from pre-trained mannequin and fine-tuned fashions
The answer is obtainable within the Generating Radiology Report Impression using generative AI with Large Language Model on AWS GitHub repo.
Stipulations
To get began, you want an AWS account by which you need to use SageMaker Studio. You will have to create a consumer profile for SageMaker Studio should you don’t have already got one.
The coaching occasion sort used on this put up is ml.p3.16xlarge. Notice that the p3 occasion sort requires a service quota limit increase.
The MIMIC CXR dataset might be accessed by way of an information use settlement, which requires consumer registration and completion of a credentialing course of.
Arrange the event atmosphere
To arrange your growth atmosphere, you create an S3 bucket, configure a pocket book, create endpoints and deploy the fashions, and create a QuickSight dashboard.
Create an S3 bucket
Create an S3 bucket known as llm-radiology-bucket to host the coaching and analysis datasets. This can even be used to retailer the mannequin artifact throughout mannequin growth.
Configure a pocket book
Full the next steps:
- Launch SageMaker Studio from both the SageMaker console or the AWS Command Line Interface (AWS CLI).
For extra details about onboarding to a website, see Onboard to Amazon SageMaker Domain.
- Create a brand new SageMaker Studio notebook for cleansing the report knowledge and fine-tuning the mannequin. We use an ml.t3.medium 2vCPU+4GiB pocket book occasion with a Python 3 kernel.
- Throughout the pocket book, set up the related packages reminiscent of
nest-asyncio,IPyWidgets(for interactive widgets for Jupyter pocket book), and the SageMaker Python SDK:
For inferencing the pre-trained and fine-tuned fashions, create an endpoint and deploy each model within the pocket book as follows:
- Create a mannequin object from the Mannequin class that may be deployed to an HTTPS endpoint.
- Create an HTTPS endpoint with the mannequin object’s pre-built
deploy()methodology:
Create a QuickSight dashboard
Create a QuickSight dashboard with an Athena data source with inference ends in Amazon Simple Storage Service (Amazon S3) to check the inference outcomes with the bottom fact. The next screenshot reveals our instance dashboard. 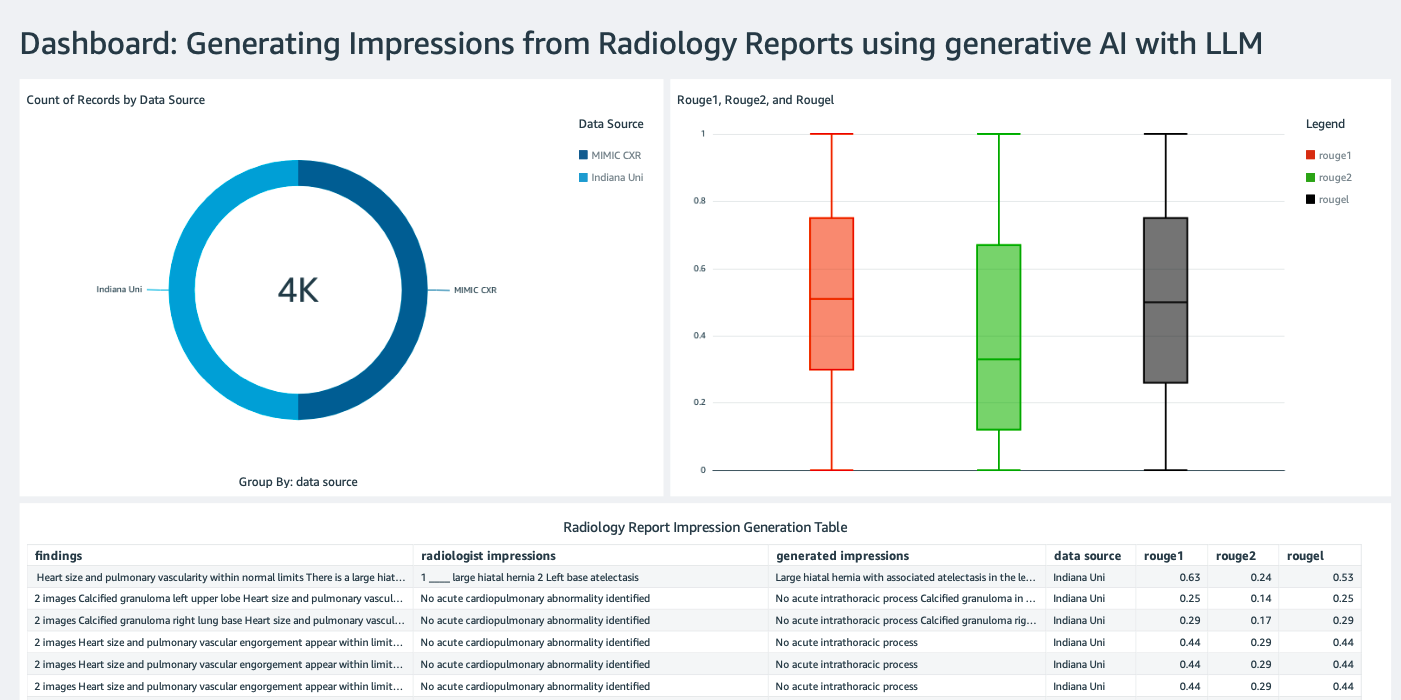
Radiology report datasets
The mannequin is now fine-tuned, all of the mannequin parameters are tuned on 91,544 stories downloaded from the MIMIC-CXR v2.0 dataset. As a result of we used solely the radiology report textual content knowledge, we downloaded only one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR web site. Now we consider the fine-tuned mannequin on 2,000 stories (known as the dev1 dataset) from the separate held out subset of this dataset. We use one other 2,000 radiology stories (known as dev2) for evaluating the fine-tuned mannequin from the chest X-ray assortment from the Indiana University hospital network. All of the datasets are learn as JSON recordsdata and uploaded to the newly created S3 bucket llm-radiology-bucket. Notice that each one the datasets by default don’t comprise any Protected Well being Info (PHI); all delicate info is changed with three consecutive underscores (___) by the suppliers.
Wonderful-tune with the SageMaker Python SDK
For fine-tuning, the model_id is specified as huggingface-text2text-flan-t5-xl from the listing of SageMaker JumpStart fashions. The training_instance_type is ready as ml.p3.16xlarge and the inference_instance_type as ml.g5.2xlarge. The coaching knowledge in JSON format is learn from the S3 bucket. The following step is to make use of the chosen model_id to extract the SageMaker JumpStart useful resource URIs, together with image_uri (the Amazon Elastic Container Registry (Amazon ECR) URI for the Docker picture), model_uri (the pre-trained mannequin artifact Amazon S3 URI), and script_uri (the coaching script):
Additionally, an output location is ready up as a folder throughout the S3 bucket.
Just one hyperparameter, epochs, is modified to three, and the remainder all are set as default:
The coaching metrics reminiscent of eval_loss (for validation loss), loss (for coaching loss), and epoch to be tracked are outlined and listed:
We use the SageMaker JumpStart useful resource URIs (image_uri, model_uri, script_uri) recognized earlier to create an estimator and fine-tune it on the coaching dataset by specifying the S3 path of the dataset. The Estimator class requires an entry_point parameter. On this case, JumpStart makes use of transfer_learning.py. The coaching job fails to run if this worth isn’t set.
This coaching job can take hours to finish; due to this fact, it’s really useful to set the wait parameter to False and monitor the coaching job standing on the SageMaker console. Use the TrainingJobAnalytics perform to maintain observe of the coaching metrics at varied timestamps:
Deploy inference endpoints
So as to draw comparisons, we deploy inference endpoints for each the pre-trained and fine-tuned fashions.
First, retrieve the inference Docker picture URI utilizing model_id, and use this URI to create a SageMaker mannequin occasion of the pre-trained mannequin. Deploy the pre-trained mannequin by creating an HTTPS endpoint with the mannequin object’s pre-built deploy() methodology. So as to run inference by way of SageMaker API, ensure to move the Predictor class.
Repeat the previous step to create a SageMaker mannequin occasion of the fine-tuned mannequin and create an endpoint to deploy the mannequin.
Consider the fashions
First, set the size of summarized textual content, variety of mannequin outputs (ought to be higher than 1 if a number of summaries have to be generated), and variety of beams for beam search.
Assemble the inference request as a JSON payload and use it to question the endpoints for the pre-trained and fine-tuned fashions.
Compute the aggregated ROUGE scores (ROUGE1, ROUGE2, ROUGEL, ROUGELsum) as described earlier.
Examine the outcomes
The next desk depicts the analysis outcomes for the dev1 and dev2 datasets. The analysis end result on dev1 (2,000 findings from the MIMIC CXR Radiology Report) reveals roughly 38 share factors enchancment within the aggregated common ROUGE1 and ROUGE2 scores in comparison with the pre-trained mannequin. For dev2, an enchancment of 31 share factors and 25 share factors is noticed in ROUGE1 and ROUGE2 scores. Total, fine-tuning led to an enchancment of 38.2 share factors and 31.3 share factors in ROUGELsum scores for the dev1 and dev2 datasets, respectively.
|
Analysis Dataset |
Pre-trained Mannequin | Wonderful-tuned mannequin | ||||||
| ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | |
dev1 |
0.2239 | 0.1134 | 0.1891 | 0.1891 | 0.6040 | 0.4800 | 0.5705 | 0.5708 |
dev2 |
0.1583 | 0.0599 | 0.1391 | 0.1393 | 0.4660 | 0.3125 | 0.4525 | 0.4525 |
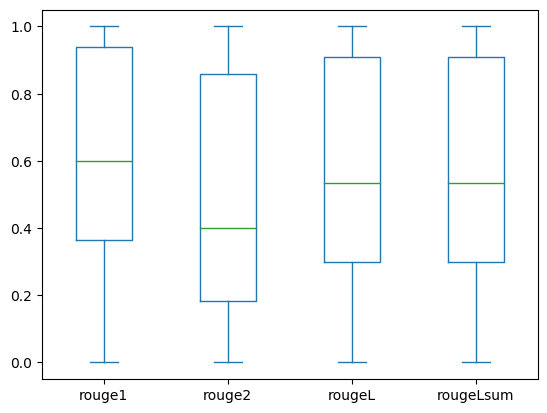
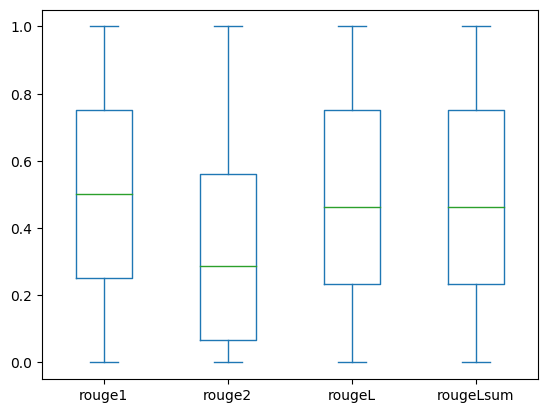
The next field plots depict the distribution of ROUGE scores for the dev1 and dev2 datasets evaluated utilizing the fine-tuned mannequin.
 |
 |
(a): dev1 |
(b): dev2 |
The next desk reveals that ROUGE scores for the analysis datasets have roughly the identical median and imply and due to this fact are symmetrically distributed.
| Datasets | Scores | Depend | Imply | Std Deviation | Minimal | 25% percentile | 50% percentile | 75% percentile | Most |
dev1 |
ROUGE1 | 2000.00 | 0.6038 | 0.3065 | 0.0000 | 0.3653 | 0.6000 | 0.9384 | 1.0000 |
| ROUGE 2 | 2000.00 | 0.4798 | 0.3578 | 0.0000 | 0.1818 | 0.4000 | 0.8571 | 1.0000 | |
| ROUGE L | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
| ROUGELsum | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
dev2 |
ROUGE 1 | 2000.00 | 0.4659 | 0.2525 | 0.0000 | 0.2500 | 0.5000 | 0.7500 | 1.0000 |
| ROUGE 2 | 2000.00 | 0.3123 | 0.2645 | 0.0000 | 0.0664 | 0.2857 | 0.5610 | 1.0000 | |
| ROUGE L | 2000.00 | 0.4529 | 0.2554 | 0.0000 | 0.2349 | 0.4615 | 0.7500 | 1.0000 | |
| ROUGE Lsum | 2000.00 | 0.4529 | 0.2554 | 0.0000 | 0.2349 | 0.4615 | 0.7500 | 1.0000 |
Clear up
To keep away from incurring future prices, delete the sources you created with the next code:
Conclusion
On this put up, we demonstrated how one can fine-tune a FLAN-T5 XL mannequin for a scientific domain-specific summarization job utilizing SageMaker Studio. To extend the arrogance, we in contrast the predictions with floor fact and evaluated the outcomes utilizing ROUGE metrics. We demonstrated {that a} mannequin fine-tuned for a particular job returns higher outcomes than a mannequin pre-trained on a generic NLP job. We wish to level out that fine-tuning a general-purpose LLM eliminates the price of pre-training altogether.
Though the work introduced right here focuses on chest X-ray stories, it has the potential to be expanded to greater datasets with diverse anatomies and modalities, reminiscent of MRI and CT, for which radiology stories may be extra complicated with a number of findings. In such instances, radiologists may generate impressions so as of criticality and embody follow-up suggestions. Moreover, establishing a suggestions loop for this software would allow radiologists to enhance the efficiency of the mannequin over time.
As we confirmed on this put up, the fine-tuned mannequin generates impressions for radiology stories with excessive ROUGE scores. You’ll be able to attempt to fine-tune LLMs on different domain-specific medical stories from completely different departments.
Concerning the authors
 Dr. Adewale Akinfaderin is a Senior Information Scientist in Healthcare and Life Sciences at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to international healthcare prospects formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in Physics and a Doctorate diploma in Engineering.
Dr. Adewale Akinfaderin is a Senior Information Scientist in Healthcare and Life Sciences at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to international healthcare prospects formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in Physics and a Doctorate diploma in Engineering.
 Priya Padate is a Senior Accomplice Options Architect with intensive experience in Healthcare and Life Sciences at AWS. Priya drives go-to-market methods with companions and drives answer growth to speed up AI/ML-based growth. She is keen about utilizing expertise to remodel the healthcare business to drive higher affected person care outcomes.
Priya Padate is a Senior Accomplice Options Architect with intensive experience in Healthcare and Life Sciences at AWS. Priya drives go-to-market methods with companions and drives answer growth to speed up AI/ML-based growth. She is keen about utilizing expertise to remodel the healthcare business to drive higher affected person care outcomes.
 Ekta Walia Bhullar, PhD, is a senior AI/ML advisor with AWS Healthcare and Life Sciences (HCLS) skilled providers enterprise unit. She has intensive expertise within the software of AI/ML throughout the healthcare area, particularly in radiology. Exterior of labor, when not discussing AI in radiology, she likes to run and hike.
Ekta Walia Bhullar, PhD, is a senior AI/ML advisor with AWS Healthcare and Life Sciences (HCLS) skilled providers enterprise unit. She has intensive expertise within the software of AI/ML throughout the healthcare area, particularly in radiology. Exterior of labor, when not discussing AI in radiology, she likes to run and hike.