Machine studying with decentralized coaching information utilizing federated studying on Amazon SageMaker

Machine studying (ML) is revolutionizing options throughout industries and driving new types of insights and intelligence from information. Many ML algorithms prepare over giant datasets, generalizing patterns it finds within the information and inferring outcomes from these patterns as new unseen data are processed. Often, if the dataset or mannequin is just too giant to be educated on a single occasion, distributed training permits for a number of situations inside a cluster for use and distribute both information or mannequin partitions throughout these situations throughout the coaching course of. Native assist for distributed coaching is obtainable via the Amazon SageMaker SDK, together with example notebooks in well-liked frameworks.
Nevertheless, generally as a consequence of safety and privateness laws inside or throughout organizations, the information is decentralized throughout a number of accounts or in numerous Areas and it will possibly’t be centralized into one account or throughout Areas. On this case, federated studying (FL) needs to be thought-about to get a generalized mannequin on the entire information.
On this publish, we talk about the right way to implement federated studying on Amazon SageMaker to run ML with decentralized coaching information.
What’s federated studying?
Federated studying is an ML method that permits for a number of separate coaching classes working in parallel to run throughout giant boundaries, for instance geographically, and mixture the outcomes to construct a generalized mannequin (world mannequin) within the course of. Extra particularly, every coaching session makes use of its personal dataset and will get its personal native mannequin. Native fashions in numerous coaching classes will likely be aggregated (for instance, mannequin weight aggregation) into a world mannequin throughout the coaching course of. This method stands in distinction to centralized ML methods the place datasets are merged for one coaching session.
Federated studying vs. distributed coaching on the cloud
When these two approaches are working on the cloud, distributed coaching occurs in a single Area on one account, and coaching information begins with a centralized coaching session or job. Throughout distributed coaching course of, the dataset will get break up into smaller subsets and, relying on the technique (information parallelism or mannequin parallelism), subsets are despatched to completely different coaching nodes or undergo nodes in a coaching cluster, which suggests particular person information doesn’t essentially keep in a single node of the cluster.
In distinction, with federated studying, coaching often happens in a number of separate accounts or throughout Areas. Every account or Area has its personal coaching situations. The coaching information is decentralized throughout accounts or Areas from the start to the top, and particular person information is barely learn by its respective coaching session or job between completely different accounts or Areas throughout the federated studying course of.
Flower federated studying framework
A number of open-source frameworks can be found for federated studying, corresponding to FATE, Flower, PySyft, OpenFL, FedML, NVFlare, and Tensorflow Federated. When selecting an FL framework, we often take into account its assist for mannequin class, ML framework, and machine or operation system. We additionally want to think about the FL framework’s extensibility and package deal measurement in order to run it on the cloud effectively. On this publish, we select an simply extensible, customizable, and light-weight framework, Flower, to do the FL implementation utilizing SageMaker.
Flower is a complete FL framework that distinguishes itself from present frameworks by providing new amenities to run large-scale FL experiments, and permits richly heterogeneous FL machine situations. FL solves challenges associated to information privateness and scalability in situations the place sharing information is just not doable.
Design rules and implementation of Flower FL
Flower FL is language-agnostic and ML framework-agnostic by design, is absolutely extensible, and might incorporate rising algorithms, coaching methods, and communication protocols. Flower is open-sourced below Apache 2.0 License.
The conceptual structure of the FL implementation is described within the paper Flower: A friendly Federated Learning Framework and is highlighted within the following determine.
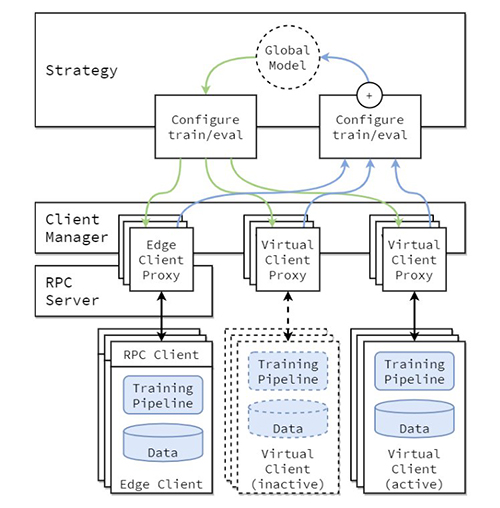
On this structure, edge purchasers stay on actual edge units and talk with the server over RPC. Digital purchasers, then again, devour near zero sources when inactive and solely load mannequin and information into reminiscence when the consumer is being chosen for coaching or analysis.
The Flower server builds the technique and configurations to be despatched to the Flower purchasers. It serializes these configuration dictionaries (or config dict for brief) to their ProtoBuf illustration, transports them to the consumer utilizing gRPC, after which deserializes them again to Python dictionaries.
Flower FL methods
Flower permits customization of the training course of via the strategy abstraction. The technique defines your entire federation course of specifying parameter initialization (whether or not it’s server or consumer initialized), the minimal variety of purchasers out there required to initialize a run, the burden of the consumer’s contributions, and coaching and analysis particulars.
Flower has an intensive implementation of FL averaging algorithms and a sturdy communication stack. For a listing of averaging algorithms applied and related analysis papers, seek advice from the next desk, from Flower: A friendly Federated Learning Framework.

Federated studying with SageMaker: Resolution structure
A federated studying structure utilizing SageMaker with the Flower framework is applied on high of bi-directional gRPC (basis) streams. gRPC defines the kinds of messages exchanged and makes use of compilers to then generate environment friendly implementation for Python, however it will possibly additionally generate the implementation for different languages, corresponding to Java or C++.
The Flower purchasers obtain directions (messages) as uncooked byte arrays through the community. Then the purchasers deserialize and run the instruction (coaching on native information). The outcomes (mannequin parameters and weights) are then serialized and communicated again to the server.
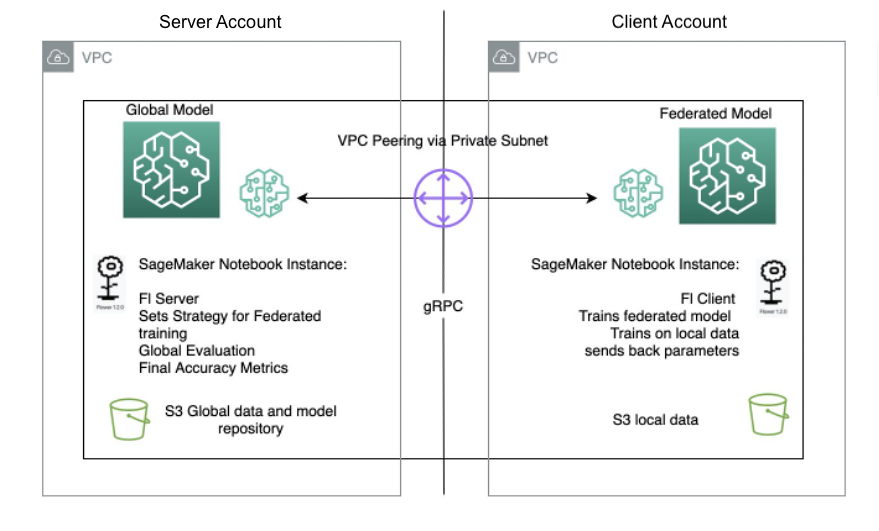
The server/consumer structure for Flower FL is outlined in SageMaker utilizing pocket book situations in numerous accounts in the identical Area because the Flower server and Flower consumer. The coaching and analysis methods are outlined on the server in addition to the worldwide parameters, then the configuration is serialized and despatched to the consumer over VPC peering.
The pocket book occasion consumer begins a SageMaker coaching job that runs a customized script to set off the instantiation of the Flower consumer, which deserializes and reads the server configuration, triggers the coaching job, and sends the parameters response.
The final step happens on the server when the analysis of the newly aggregated parameters is triggered upon completion of the variety of runs and purchasers stipulated on the server technique. The analysis takes place on a testing dataset present solely on the server, and the brand new improved accuracy metrics are produced.
The next diagram illustrates the structure of the FL setup on SageMaker with the Flower package deal.
Implement federated studying utilizing SageMaker
SageMaker is a completely managed ML service. With SageMaker, information scientists and builders can rapidly construct and prepare ML fashions, after which deploy them right into a production-ready hosted atmosphere.
On this publish, we display the right way to use the managed ML platform to supply a pocket book expertise atmosphere and carry out federated studying throughout AWS accounts, utilizing SageMaker coaching jobs. The uncooked coaching information by no means leaves the account that owns the information and solely the derived weights are despatched throughout the peered connection.
We spotlight the next core parts on this publish:
- Networking – SageMaker permits for fast setup of default networking configuration whereas additionally permitting you to totally customise the networking relying in your group’s necessities. We use a VPC peering configuration inside the Area on this instance.
- Cross-account entry settings – With the intention to enable a consumer within the server account to begin a mannequin coaching job within the consumer account, we delegate access across accounts utilizing AWS Identity and Access Management (IAM) roles. This manner, a consumer within the server account doesn’t should signal out of the account and register to the consumer account to carry out actions on SageMaker. This setting is just for functions of beginning SageMaker coaching jobs, and it doesn’t have any cross-account information entry permission or sharing.
- Implementing federated studying consumer code within the consumer account and server code within the server account – We implement federated studying consumer code within the consumer account through the use of the Flower package deal and SageMaker managed coaching. In the meantime, we implement server code within the server account through the use of the Flower package deal.
Arrange VPC peering
A VPC peering connection is a networking connection between two VPCs that lets you route site visitors between them utilizing personal IPv4 addresses or IPv6 addresses. Situations in both VPC can talk with one another as if they’re inside the similar community.
To arrange a VPC peering connection, first create a request to see with one other VPC. You’ll be able to request a VPC peering reference to one other VPC in the identical account, or in our use case, join with a VPC in a special AWS account. To activate the request, the proprietor of the VPC should settle for the request. For extra particulars about VPC peering, seek advice from Create a VPC peering connection.
Launch SageMaker pocket book situations in VPCs
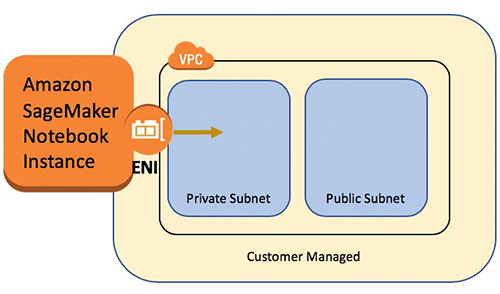
A SageMaker pocket book occasion offers a Jupyter pocket book app via a completely managed ML Amazon Elastic Compute Cloud (Amazon EC2) occasion. SageMaker Jupyter notebooks are used to carry out superior information exploration, create coaching jobs, deploy fashions to SageMaker internet hosting, and check or validate your fashions.
The pocket book occasion has a wide range of networking configurations out there to it. On this setup, we’ve got the pocket book occasion run inside a personal subnet of the VPC and don’t have direct web entry.
Configure cross-account entry settings
Cross-account entry settings embrace two steps to delegate entry from the server account to consumer account through the use of IAM roles:
- Create an IAM position within the consumer account.
- Grant entry to the position within the server account.
For detailed steps to arrange an identical state of affairs, seek advice from Delegate access across AWS accounts using IAM roles.
Within the consumer account, we create an IAM position known as FL-kickoff-client-job with the coverage FL-sagemaker-actions connected to the position. The FL-sagemaker-actions coverage has JSON content material as follows:
We then modify the belief coverage within the belief relationships of the FL-kickoff-client-job position:
Within the server account, permissions are added to an present consumer (for instance, developer) to permit switching to the FL-kickoff-client-job position in consumer account. To do that, we create an inline coverage known as FL-allow-kickoff-client-job and fix it to the consumer. The next is the coverage JSON content material:
Pattern dataset and information preparation
On this publish, we use a curated dataset for fraud detection in Medicare suppliers’ information launched by the Centers for Medicare & Medicaid Services (CMS). Knowledge is break up right into a coaching dataset and a testing dataset. As a result of nearly all of the information is non-fraud, we apply SMOTE to stability the coaching dataset, and additional break up the coaching dataset into coaching and validation components. Each the coaching and validation information are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket for mannequin coaching within the consumer account, and the testing dataset is used within the server account for testing functions solely. Particulars of the information preparation code are within the following notebook.
With the SageMaker pre-built Docker images for the scikit-learn framework and SageMaker managed coaching course of, we prepare a logistic regression mannequin on this dataset utilizing federated studying.
Implement a federated studying consumer within the consumer account
Within the consumer account’s SageMaker pocket book occasion, we put together a client.py script and a utils.py script. The consumer.py file accommodates code for the consumer, and the utils.py file accommodates code for among the utility capabilities that will likely be wanted for our coaching. We use the scikit-learn package deal to construct the logistic regression mannequin.
In consumer.py, we outline a Flower consumer. The consumer is derived from the category fl.client.NumPyClient. It must outline the next three strategies:
- get_parameters – It returns the present native mannequin parameters. The utility perform
get_model_parameterswill do that. - match – It defines the steps to coach the mannequin on the coaching information in consumer’s account. It additionally receives world mannequin parameters and different configuration info from the server. We replace the native mannequin’s parameters utilizing the obtained world parameters and proceed coaching it on the dataset within the consumer account. This methodology additionally sends the native mannequin’s parameters after coaching, the dimensions of the coaching set, and a dictionary speaking arbitrary values again to the server.
- consider – It evaluates the offered parameters utilizing the validation information within the consumer account. It returns the loss along with different particulars corresponding to the dimensions of the validation set and accuracy again to the server.
The next is a code snippet for the Flower consumer definition:
We then use SageMaker script mode to organize the remainder of the consumer.py file. This consists of defining parameters that will likely be handed to SageMaker coaching, loading coaching and validation information, initializing and coaching the mannequin on the consumer, establishing the Flower consumer to speak with the server, and at last saving the educated mannequin.
utils.py features a few utility capabilities which can be known as in consumer.py:
- get_model_parameters – It returns the scikit-learn LogisticRegression mannequin parameters.
- set_model_params – It units the mannequin’s parameters.
- set_initial_params – It initializes the parameters of the mannequin as zeros. That is required as a result of the server asks for preliminary mannequin parameters from the consumer at launch. Nevertheless, within the scikit-learn framework,
LogisticRegressionmannequin parameters usually are not initialized tillmannequin.match()is named. - load_data – It hundreds the coaching and testing information.
- save_model – It saves mannequin as a
.joblibfile.
As a result of Flower is just not a package deal put in within the SageMaker pre-built scikit-learn Docker container, we record flwr==1.3.0 in a necessities.txt file.
We put all three recordsdata (consumer.py, utils.py, and necessities.txt) below a folder and tar zip it. The .tar.gz file (named supply.tar.gz on this publish) is then uploaded to an S3 bucket within the consumer account.
Implement a federated studying server within the server account
Within the server account, we put together code on a Jupyter pocket book. This consists of two components: the server first assumes a job to begin a coaching job within the consumer account, then the server federates the mannequin utilizing Flower.
Assume a job to run the coaching job within the consumer account
We use the Boto3 Python SDK to arrange an AWS Security Token Service (AWS STS) consumer to imagine the FL-kickoff-client-job position and arrange a SageMaker consumer in order to run a coaching job within the consumer account through the use of the SageMaker managed coaching course of:
Utilizing the assumed position, we create a SageMaker coaching job in consumer account. The coaching job makes use of the SageMaker built-in scikit-learn framework. Be aware that each one S3 buckets and the SageMaker IAM position within the following code snippet are associated to the consumer account:
Combination native fashions into a world mannequin utilizing Flower
We put together code to federate the mannequin on the server. This consists of defining the technique for federation and its initialization parameters. We use utility capabilities within the utils.py script described earlier to initialize and set mannequin parameters. Flower lets you outline your individual callback capabilities to customise an present technique. We use the FedAvg technique with customized callbacks for analysis and match configuration. See the next code:
The next two capabilities are talked about within the previous code snippet:
- fit_round – It’s used to ship the spherical quantity to the consumer. We go this callback because the
on_fit_config_fnparameter of the technique. We do that merely to display using theon_fit_config_fnparameter. - get_evaluate_fn – It’s used for mannequin analysis on the server.
For demo functions, we use the testing dataset that we put aside in information preparation to judge the mannequin federated from the consumer’s account and talk the consequence again to the consumer. Nevertheless, it’s price noting that in nearly all actual use circumstances, the information used within the server account is just not break up from the dataset used within the consumer account.
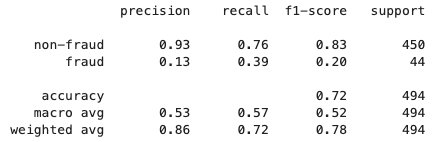
After the federated studying course of is completed, a mannequin.tar.gz file is saved by SageMaker as a mannequin artifact in an S3 bucket within the consumer account. In the meantime, a mannequin.joblib file is saved on the SageMaker pocket book occasion within the server account. Lastly, we use the testing dataset to check the ultimate mannequin (mannequin.joblib) on the server. Testing output of the ultimate mannequin is as follows:
Clear up
After you’re executed, clear up the sources in each the server account and consumer account to keep away from extra costs:
- Cease the SageMaker pocket book situations.
- Delete VPC peering connections and corresponding VPCs.
- Empty and delete the S3 bucket you created for information storage.
Conclusion
On this publish, we walked via the right way to implement federated studying on SageMaker through the use of the Flower package deal. We confirmed the right way to configure VPC peering, arrange cross-account entry, and implement the FL consumer and server. This publish is helpful for individuals who want to coach ML fashions on SageMaker utilizing decentralized information throughout accounts with restricted information sharing. As a result of the FL on this publish is applied utilizing SageMaker, it’s price noting that much more options in SageMaker might be introduced into the method.
Implementing federated studying on SageMaker can benefit from all of the superior options that SageMaker offers via the ML lifecycle. There are different methods to realize or apply federated studying on the AWS Cloud, corresponding to utilizing EC2 situations or on the sting. For particulars about these various approaches, seek advice from Federated Learning on AWS with FedML and Applying Federated Learning for ML at the Edge.
In regards to the authors
 Sherry Ding is a senior AI/ML specialist options architect at Amazon Internet Companies (AWS). She has intensive expertise in machine studying with a PhD diploma in laptop science. She primarily works with public sector prospects on varied AI/ML-related enterprise challenges, serving to them speed up their machine studying journey on the AWS Cloud. When not serving to prospects, she enjoys outside actions.
Sherry Ding is a senior AI/ML specialist options architect at Amazon Internet Companies (AWS). She has intensive expertise in machine studying with a PhD diploma in laptop science. She primarily works with public sector prospects on varied AI/ML-related enterprise challenges, serving to them speed up their machine studying journey on the AWS Cloud. When not serving to prospects, she enjoys outside actions.
 Lorea Arrizabalaga is a Options Architect aligned to the UK Public Sector, the place she helps prospects design ML options with Amazon SageMaker. She can also be a part of the Technical Discipline Neighborhood devoted to {hardware} acceleration and helps with testing and benchmarking AWS Inferentia and AWS Trainium workloads.
Lorea Arrizabalaga is a Options Architect aligned to the UK Public Sector, the place she helps prospects design ML options with Amazon SageMaker. She can also be a part of the Technical Discipline Neighborhood devoted to {hardware} acceleration and helps with testing and benchmarking AWS Inferentia and AWS Trainium workloads.
 Ben Snively is an AWS Public Sector Senior Principal Specialist Options Architect. He works with authorities, non-profit, and schooling prospects on massive information, analytical, and AI/ML tasks, serving to them construct options utilizing AWS.
Ben Snively is an AWS Public Sector Senior Principal Specialist Options Architect. He works with authorities, non-profit, and schooling prospects on massive information, analytical, and AI/ML tasks, serving to them construct options utilizing AWS.





