Unlocking effectivity: Harnessing the facility of Selective Execution in Amazon SageMaker Pipelines
MLOps is a key self-discipline that always oversees the trail to productionizing machine studying (ML) fashions. It’s pure to give attention to a single mannequin that you simply wish to practice and deploy. Nevertheless, in actuality, you’ll seemingly work with dozens and even tons of of fashions, and the method could contain a number of advanced steps. Subsequently, it’s essential to have the infrastructure in place to trace, practice, deploy, and monitor fashions with various complexities at scale. That is the place MLOps tooling is available in. MLOps tooling helps you repeatably and reliably construct and simplify these processes right into a workflow that’s tailor-made for ML.
Amazon SageMaker Pipelines, a function of Amazon SageMaker, is a purpose-built workflow orchestration service for ML that helps you automate end-to-end ML workflows at scale. It simplifies the event and upkeep of ML fashions by offering a centralized platform to orchestrate duties corresponding to information preparation, mannequin coaching, tuning and validation. SageMaker Pipelines will help you streamline workflow administration, speed up experimentation and retrain fashions extra simply.
On this put up, we highlight an thrilling new function of SageMaker Pipelines often known as Selective Execution. This new function empowers you to selectively run particular parts of your ML workflow, leading to important time and compute useful resource financial savings by limiting the run to pipeline steps in scope and eliminating the necessity to run steps out of scope. Moreover, we discover numerous use instances the place some great benefits of using Selective Execution turn into evident, additional solidifying its worth proposition.
Answer overview
SageMaker Pipelines continues to innovate its developer expertise with the discharge of Selective Execution. ML builders now have the flexibility to decide on particular steps to run inside a pipeline, eliminating the necessity to rerun all the pipeline. This function allows you to rerun particular sections of the pipeline whereas modifying the runtime parameters related to the chosen steps.
It’s essential to notice that the chosen steps could depend on the outcomes of non-selected steps. In such instances, the outputs of those non-selected steps are reused from a reference run of the present pipeline model. Which means the reference run should have already accomplished. The default reference run is the newest run of the present pipeline model, however you may also select to make use of a special run of the present pipeline model as a reference.
The general state of the reference run should be Profitable, Failed or Stopped. It can’t be Operating when Selective Execution makes an attempt to make use of its outputs. When utilizing Selective Execution, you’ll be able to select any variety of steps to run, so long as they kind a contiguous portion of the pipeline.
The next diagram illustrates the pipeline conduct with a full run.

The next diagram illustrates the pipeline conduct utilizing Selective Execution.

Within the following sections, we present easy methods to use Selective Execution for numerous situations, together with advanced workflows in pipeline Direct Acyclic Graphs (DAGs).
Conditions
To start out experimenting with Selective Execution, we have to first arrange the next parts of your SageMaker surroundings:
- SageMaker Python SDK – Guarantee that you’ve an up to date SageMaker Python SDK put in in your Python surroundings. You may run the next command out of your pocket book or terminal to put in or improve the SageMaker Python SDK model to 2.162.0 or increased:
python3 -m pip set up sagemaker>=2.162.0orpip3 set up sagemaker>=2.162.0. - Entry to SageMaker Studio (non-obligatory) – Amazon SageMaker Studio may be useful for visualizing pipeline runs and interacting with preexisting pipeline ARNs visually. When you don’t have entry to SageMaker Studio or are utilizing on-demand notebooks or different IDEs, you’ll be able to nonetheless observe this put up and work together together with your pipeline ARNs utilizing the Python SDK.
The pattern code for a full end-to-end walkthrough is out there within the GitHub repo.
Setup
With the sagemaker>=1.162.0 Python SDK, we launched the SelectiveExecutionConfig class as a part of the sagemaker.workflow.selective_execution_config module. The Selective Execution function depends on a pipeline ARN that has been beforehand marked as Succeeded, Failed or Stopped. The next code snippet demonstrates easy methods to import the SelectiveExecutionConfig class, retrieve the reference pipeline ARN, and collect related pipeline steps and runtime parameters governing the pipeline run:
import boto3
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.selective_execution_config import SelectiveExecutionConfig
sm_client = boto3.shopper('sagemaker')
# reference the title of your pattern pipeline
pipeline_name = "AbalonePipeline"
# filter for earlier success pipeline execution arns
pipeline_executions = [_exec
for _exec in Pipeline(name=pipeline_name).list_executions()['PipelineExecutionSummaries']
if _exec['PipelineExecutionStatus'] == "Succeeded"
]
# get the final profitable execution
latest_pipeline_arn = pipeline_executions[0]['PipelineExecutionArn']
print(latest_pipeline_arn)
>>> arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/x62pbar3gs6h
# record all steps of your pattern pipeline
execution_steps = sm_client.list_pipeline_execution_steps(
PipelineExecutionArn=latest_pipeline_arn
)['PipelineExecutionSteps']
print(execution_steps)
>>>
[{'StepName': 'Abalone-Preprocess',
'StartTime': datetime.datetime(2023, 6, 27, 4, 41, 30, 519000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 41, 30, 986000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'ProcessingJob': {'Arn': 'arn:aws:sagemaker:us-east-1:123123123123:processing-job/pipelines-fvsmu7m7ki3q-Abalone-Preprocess-d68CecvHLU'}},
'SelectiveExecutionResult': {'SourcePipelineExecutionArn': 'arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/ksm2mjwut6oz'}},
{'StepName': 'Abalone-Train',
'StartTime': datetime.datetime(2023, 6, 27, 4, 41, 31, 320000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 43, 58, 224000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'TrainingJob': {'Arn': 'arn:aws:sagemaker:us-east-1:123123123123:training-job/pipelines-x62pbar3gs6h-Abalone-Train-PKhAc1Q6lx'}}},
{'StepName': 'Abalone-Evaluate',
'StartTime': datetime.datetime(2023, 6, 27, 4, 43, 59, 40000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 57, 43, 76000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'ProcessingJob': {'Arn': 'arn:aws:sagemaker:us-east-1:123123123123:processing-job/pipelines-x62pbar3gs6h-Abalone-Evaluate-vmkZDKDwhk'}}},
{'StepName': 'Abalone-MSECheck',
'StartTime': datetime.datetime(2023, 6, 27, 4, 57, 43, 821000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 57, 44, 124000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'Condition': {'Outcome': 'True'}}}]
# record all configureable pipeline parameters
# params may be altered throughout selective execution
parameters = sm_client.list_pipeline_parameters_for_execution(
PipelineExecutionArn=latest_pipeline_arn
)['PipelineParameters']
print(parameters)
>>>
[{'Name': 'XGBNumRounds', 'Value': '120'},
{'Name': 'XGBSubSample', 'Value': '0.9'},
{'Name': 'XGBGamma', 'Value': '2'},
{'Name': 'TrainingInstanceCount', 'Value': '1'},
{'Name': 'XGBMinChildWeight', 'Value': '4'},
{'Name': 'XGBETA', 'Value': '0.25'},
{'Name': 'ApprovalStatus', 'Value': 'PendingManualApproval'},
{'Name': 'ProcessingInstanceCount', 'Value': '1'},
{'Name': 'ProcessingInstanceType', 'Value': 'ml.t3.medium'},
{'Name': 'MseThreshold', 'Value': '6'},
{'Name': 'ModelPath',
'Value': 's3://sagemaker-us-east-1-123123123123/Abalone/models/'},
{'Name': 'XGBMaxDepth', 'Value': '12'},
{'Name': 'TrainingInstanceType', 'Value': 'ml.c5.xlarge'},
{'Name': 'InputData',
'Value': 's3://sagemaker-us-east-1-123123123123/sample-dataset/abalone/abalone.csv'}]Use instances
On this part, we current a couple of situations the place Selective Execution can doubtlessly save time and assets. We use a typical pipeline circulate, which incorporates steps corresponding to information extraction, coaching, analysis, mannequin registration and deployment, as a reference to reveal some great benefits of Selective Execution.
SageMaker Pipelines permits you to outline runtime parameters in your pipeline run utilizing pipeline parameters. When a brand new run is triggered, it sometimes runs all the pipeline from begin to end. Nevertheless, if step caching is enabled, SageMaker Pipelines will try to discover a earlier run of the present pipeline step with the identical attribute values. If a match is discovered, SageMaker Pipelines will use the outputs from the earlier run as a substitute of recomputing the step. Be aware that even with step caching enabled, SageMaker Pipelines will nonetheless run all the workflow to the tip by default.
With the discharge of the Selective Execution function, now you can rerun a complete pipeline workflow or selectively run a subset of steps utilizing a previous pipeline ARN. This may be achieved even with out step caching enabled. The next use instances illustrate the assorted methods you should utilize Selective Execution.
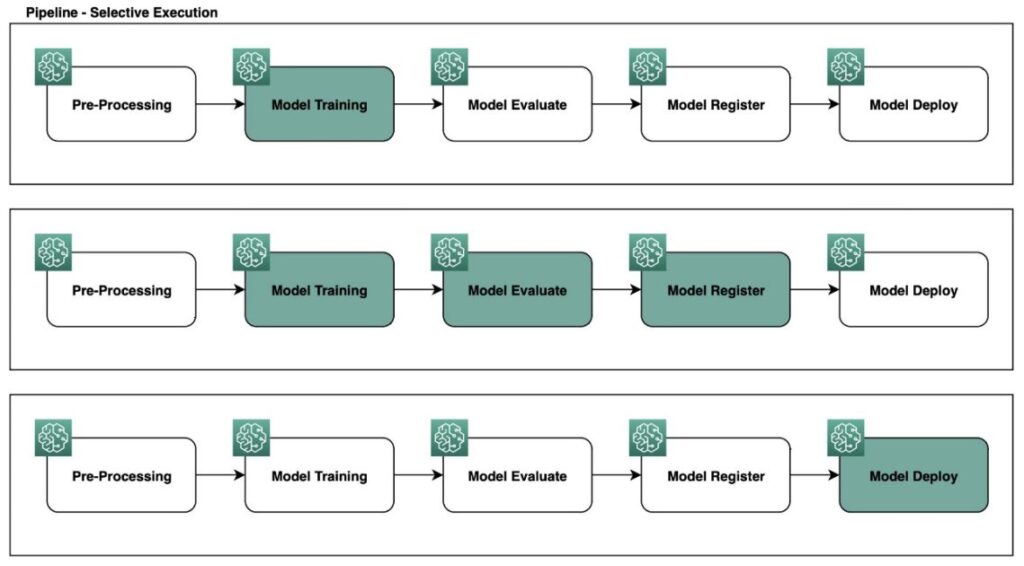
Use case 1: Run a single step
Information scientists usually give attention to the coaching stage of a MLOps pipeline and don’t wish to fear in regards to the preprocessing or deployment steps. Selective Execution permits information scientists to give attention to simply the coaching step and modify coaching parameters or hyperparameters on the fly to enhance the mannequin. This could save time and scale back price as a result of compute assets are solely utilized for working user-selected pipeline steps. See the next code:
# choose a reference pipeline arn and subset step to execute
selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/9e3ljoql7s0n",
selected_steps=["Abalone-Train"]
)
# begin execution of pipeline subset
select_execution = pipeline.begin(
selective_execution_config=selective_execution_config,
parameters={
"XGBNumRounds": 120,
"XGBSubSample": 0.9,
"XGBGamma": 2,
"XGBMinChildWeight": 4,
"XGBETA": 0.25,
"XGBMaxDepth": 12
}
)The next figures illustrate the pipeline with one step in course of after which full.


Use case 2: Run a number of contiguous pipeline steps
Persevering with with the earlier use case, a knowledge scientist needs to coach a brand new mannequin and consider its efficiency in opposition to a golden take a look at dataset. This analysis is essential to make sure that the mannequin meets rigorous tips for person acceptance testing (UAT) or manufacturing deployment. Nevertheless, the info scientist doesn’t wish to run all the pipeline workflow or deploy the mannequin. They’ll use Selective Execution to focus solely on the coaching and analysis steps, saving time and assets whereas nonetheless getting the validation outcomes they want:
# choose a reference pipeline arn and subset step to execute
selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/9e3ljoql7s0n",
selected_steps=["Abalone-Train", "Abalone-Evaluate"]
)
# begin execution of pipeline subset
select_execution = pipeline.begin(
selective_execution_config=selective_execution_config,
parameters={
"ProcessingInstanceType": "ml.t3.medium",
"XGBNumRounds": 120,
"XGBSubSample": 0.9,
"XGBGamma": 2,
"XGBMinChildWeight": 4,
"XGBETA": 0.25,
"XGBMaxDepth": 12
}
)Use case 3: Replace and rerun failed pipeline steps
You need to use Selective Execution to rerun failed steps inside a pipeline or resume the run of a pipeline from a failed step onwards. This may be helpful for troubleshooting and debugging failed steps as a result of it permits builders to give attention to the precise points that must be addressed. This could result in extra environment friendly problem-solving and sooner iteration occasions. The next instance illustrates how one can select to rerun simply the failed step of a pipeline.

# choose a beforehand failed pipeline arn
selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/fvsmu7m7ki3q",
selected_steps=["Abalone-Evaluate"]
)
# begin execution of failed pipeline subset
select_execution = pipeline.begin(
selective_execution_config=selective_execution_config
)
Alternatively, a knowledge scientist can resume a pipeline from a failed step to the tip of the workflow by specifying the failed step and all of the steps that observe it within the SelectiveExecutionConfig.
Use case 4: Pipeline protection
In some pipelines, sure branches are much less often run than others. For instance, there could be a department that solely runs when a particular situation fails. It’s essential to check these branches totally to make sure that they work as anticipated when a failure does happen. By testing these much less often run branches, builders can confirm that their pipeline is powerful and that error-handling mechanisms successfully preserve the specified workflow and produce dependable outcomes.

selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/9e3ljoql7s0n",
selected_steps=["Abalone-Train", "Abalone-Evaluate", "Abalone-MSECheck", "Abalone-FailNotify"]
)
Conclusion
On this put up, we mentioned the Selective Execution function of SageMaker Pipelines, which empowers you to selectively run particular steps of your ML workflows. This functionality results in important time and computational useful resource financial savings. We offered some pattern code within the GitHub repo that demonstrates easy methods to use Selective Execution and introduced numerous situations the place it may be advantageous for customers. If you want to study extra about Selective Execution, discuss with our Developer Guide and API Reference Guide.
To discover the obtainable steps throughout the SageMaker Pipelines workflow in additional element, discuss with Amazon SageMaker Model Building Pipeline and SageMaker Workflows. Moreover, you’ll find extra examples showcasing completely different use instances and implementation approaches utilizing SageMaker Pipelines within the AWS SageMaker Examples GitHub repository. These assets can additional improve your understanding and show you how to make the most of the total potential of SageMaker Pipelines and Selective Execution in your present and future ML initiatives.
In regards to the Authors
 Pranav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to clients construct, practice, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor business growing giant laptop imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes. In his free time, he enjoys taking part in chess and touring.
Pranav Murthy is an AI/ML Specialist Options Architect at AWS. He focuses on serving to clients construct, practice, deploy and migrate machine studying (ML) workloads to SageMaker. He beforehand labored within the semiconductor business growing giant laptop imaginative and prescient (CV) and pure language processing (NLP) fashions to enhance semiconductor processes. In his free time, he enjoys taking part in chess and touring.
 Akhil Numarsu is a Sr.Product Supervisor-Technical centered on serving to groups speed up ML outcomes by way of environment friendly instruments and companies within the cloud. He enjoys taking part in Desk Tennis and is a sports activities fan.
Akhil Numarsu is a Sr.Product Supervisor-Technical centered on serving to groups speed up ML outcomes by way of environment friendly instruments and companies within the cloud. He enjoys taking part in Desk Tennis and is a sports activities fan.
 Nishant Krishnamoorthy is a Sr. Software program Growth Engineer with Amazon Shops. He holds a masters diploma in Pc Science and at the moment focuses on accelerating ML Adoption in several orgs inside Amazon by constructing and operationalizing ML options on SageMaker.
Nishant Krishnamoorthy is a Sr. Software program Growth Engineer with Amazon Shops. He holds a masters diploma in Pc Science and at the moment focuses on accelerating ML Adoption in several orgs inside Amazon by constructing and operationalizing ML options on SageMaker.





