LAION AI Introduces Video2Dataset: An Open-Supply Device Designed To Curate Video And Audio Datasets Effectively And At Scale
Huge foundational fashions like CLIP, Steady Diffusion, and Flamingo have radically improved multimodal deep studying over the previous few years. Joint text-image modeling has gone from being a distinct segment utility to one of many (if not the) most related points in as we speak’s synthetic intelligence panorama because of the excellent capabilities of such fashions to generate spectacular, high-resolution imagery or carry out onerous downstream issues. Surprisingly, regardless of tackling vastly completely different duties and having vastly completely different designs, all these fashions have three elementary properties in frequent that contribute to their sturdy efficiency: a easy and secure goal operate throughout (pre-)coaching, a well-investigated scalable mannequin structure, and – maybe most significantly – a big, various dataset.
Multimodal deep studying, as of 2023, continues to be primarily involved with text-image modeling, with solely restricted consideration paid to further modalities like video (and audio). Contemplating that the strategies used to coach the fashions are sometimes modality agnostic, one might surprise why there aren’t stable groundwork fashions for these different modalities. The easy rationalization is the shortage of high-quality, large-scale annotated datasets. This lack of unpolluted information impedes analysis and growth of enormous multimodal fashions, particularly within the video area, in distinction to picture modeling, the place there exist established datasets for scaling like LAION-5B, DataComp, and COYO-700M and scalable instruments like img2dataset.
As a result of it could possibly pave the best way for groundbreaking initiatives like high-quality video and audio creation, improved pre-trained fashions for robotics, film AD for the blind neighborhood, and extra, researchers recommend that resolving this information drawback is a central intention of (open supply) multimodal analysis.
Researchers current video2dataset, an open-source program for quick and in depth video and audio dataset curating. It has been efficiently examined on a number of giant video datasets, and it’s adaptable, extensible, and offers an enormous variety of transformations. Yow will discover these case research and detailed directions on replicating our technique within the repository.
By downloading particular person video datasets, merging them, and reshaping them into extra manageable shapes with new options and considerably extra samples, researchers have utilized video2dataset to construct upon current video datasets. Please confer with the examples part for a extra in-depth description of this chain processing. The outcomes they achieved by coaching completely different fashions on the datasets equipped by video2dataset reveal the device’s efficacy. Our forthcoming research will extensively talk about the brand new information set and related findings.
To start, let’s outline video2dataset.
Since webdataset is an appropriate input_format, video2dataset can be utilized in a sequence to reprocess beforehand downloaded information. You need to use the WebVid information you downloaded within the earlier instance to execute this script, which is able to calculate the optical circulation for every film and retailer it in metadata shards (shards that solely have the optical circulation metadata in them).
Structure
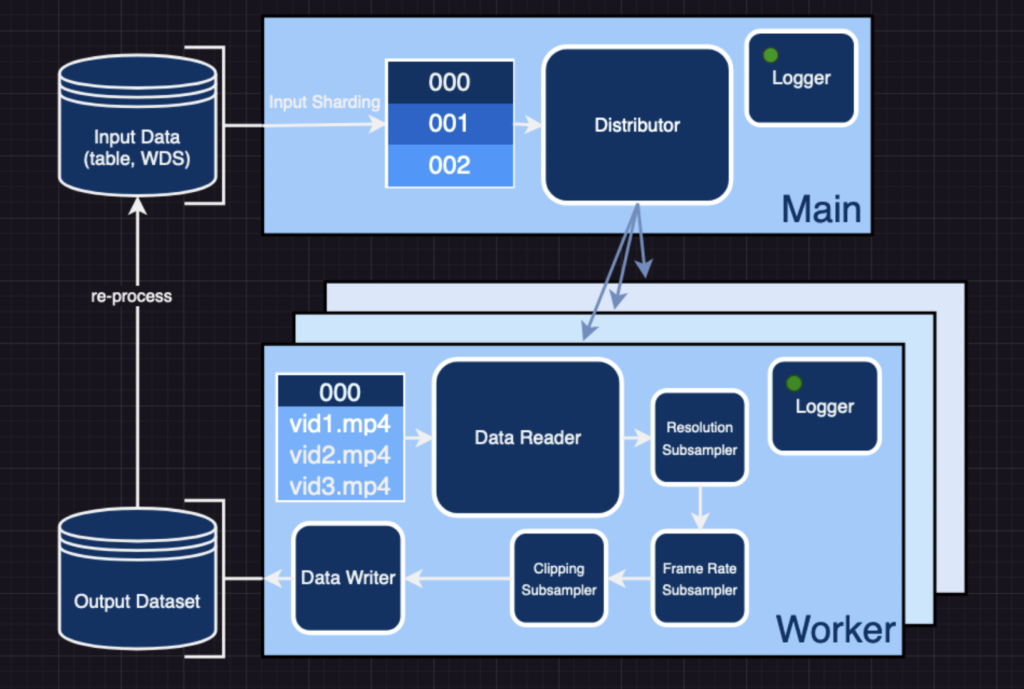
Based mostly on img2dataset, video2dataset takes a listing of URLs and related metadata and converts it right into a WebDataset that may be loaded with a single command. As well as, the WebDataset might be reprocessed for added adjustments with the identical shard contents preserved. How does video2dataset work? I’ll clarify.
Exchanging Concepts
Step one is to partition the enter information in order that it might be distributed evenly among the many employees. These enter shards are cached briefly, and the one-to-one mapping between them and their corresponding output shards ensures fault-free restoration. If a dataset processing run terminates unexpectedly, one can save time by skipping the enter shards for which researchers have already got the corresponding output shard.
Communication and Examine
Employees then take turns studying and processing the samples contained throughout the shards. Researchers supply three completely different distribution modes: multiprocessing, pyspark, and slurm. The previous is good for single-machine purposes, whereas the latter is beneficial for scaling throughout a number of machines. The format of the incoming dataset determines the studying technique. If the information is a desk of URLs, video2dataset will fetch the video from the web and add it to the dataset. video2dataset works with many various video platforms as a result of it makes use of yt-dlp to request movies it could possibly’t discover. Nevertheless, if the video samples come from an current Net dataset, the information loader for that dataset can learn the tensor format of the bytes or frames.
Subsampling
After the video has been learn and the employee has the video bytes, the bytes are despatched via a pipeline of subsamplers based on the job configuration. On this stage, the video could also be optionally downsampled by way of each body price and backbone; clipped; scenes could also be recognized; and so forth. Then again, there are subsamplers whose sole goal is to extract and add metadata, resembling decision/compression info, artificial captions, optical circulation, and so forth, from the enter modalities. Defining a brand new subsampler or modifying an current one is all it takes so as to add a brand new transformation to video2dataset if it isn’t already there. It is a big assist and might be applied with a number of adjustments elsewhere within the repository.
Logging
Video2dataset retains meticulous logs at a number of factors within the course of. Every shard’s completion ends in its related “ID” _stats.json file. Info resembling the entire variety of samples dealt with, the share of these dealt with efficiently, and the incidence and nature of any errors are recorded right here. Weights & Biases (wand) is an extra device that can be utilized with video2dataset. With only one argument, you may activate this integration and entry detailed efficiency reporting and metrics for successes and failures. Such capabilities are useful for benchmarking and cost-estimating duties related to entire jobs.
Writing
Lastly, video2dataset shops the modified info in output shards at user-specified locations to make use of in subsequent coaching or reprocessing operations. The dataset might be downloaded in a number of codecs, all consisting of shards with N samples every. These codecs embody folders, tar recordsdata, data, and parquet recordsdata. A very powerful ones are the directories format for smaller datasets for debugging and tar recordsdata utilized by the WebDataset format for loading.
Reprocessing
video2dataset can reprocess earlier output datasets by studying the output shards and passing the samples via new transformations. This performance is especially advantageous for video datasets, contemplating their usually hefty dimension and awkward nature. It permits us to rigorously downsample the information to keep away from quite a few downloads of enormous datasets. Researchers dig right into a sensible instance of this within the subsequent part.
Code and particulars might be present in GitHub https://github.com/iejMac/video2dataset
Future Plans
- Examine of an enormous dataset constructed with the software program described on this weblog article, adopted by public dissemination of the outcomes of that research.
- It improved artificial captioning. There may be a variety of room for innovation in artificial captioning for movies. Quickly in video2dataset, researchers could have extra fascinating strategies to provide captions for movies that use picture captioning fashions and LLMs.
- Whisper’s means to extract quite a few textual content tokens from the video has been the topic of a lot dialogue since its launch. Utilizing video2dataset, they’re at present transcribing a large assortment of podcasts to make the ensuing textual content dataset (focusing on 50B tokens) publicly out there.
- Many thrilling modeling concepts. Hopefully, with improved dataset curation tooling, extra individuals will try to push the SOTA within the video and audio modality.
video2dataset is a totally open-source venture, and researchers are dedicated to growing it within the open. This implies all of the related TODOs and future instructions might be discovered within the points tab of the repository. Contributions are welcomed; one of the simplest ways to try this is to select an issue, handle it, and submit a pull request.
Try the Blog and Github Link. Don’t overlook to hitch our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra. In case you have any questions concerning the above article or if we missed something, be at liberty to electronic mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Dhanshree Shenwai is a Pc Science Engineer and has a great expertise in FinTech corporations overlaying Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is obsessed with exploring new applied sciences and developments in as we speak’s evolving world making everybody’s life simple.






