Spotlight textual content because it’s being spoken utilizing Amazon Polly
Amazon Polly is a service that turns textual content into lifelike speech. It permits the event of an entire class of functions that may convert textual content into speech in a number of languages.
This service can be utilized by chatbots, audio books, and different text-to-speech functions at the side of different AWS AI or machine studying (ML) providers. For instance, Amazon Lex and Amazon Polly may be mixed to create a chatbot that engages in a two-way dialog with a consumer and performs sure duties based mostly on the consumer’s instructions. Amazon Transcribe, Amazon Translate, and Amazon Polly may be mixed to transcribe speech to textual content within the supply language, translate it to a distinct language, and converse it.
On this submit, we current an fascinating strategy for highlighting textual content because it’s being spoken utilizing Amazon Polly. This resolution can be utilized in lots of text-to-speech functions to do the next:
- Add visible capabilities to audio in books, web sites, and blogs
- Enhance comprehension when prospects try to know the textual content quickly because it’s being spoken
Our resolution provides the consumer (the browser, on this instance), the power to know what textual content (phrase or sentence) is being spoken by Amazon Polly at any prompt. This permits the consumer to dynamically spotlight the textual content because it’s being spoken. Such a functionality is helpful for offering visible help to speech for the use circumstances talked about beforehand.
Our resolution may be prolonged to carry out further duties in addition to highlighting textual content. For instance, the browser can present photographs, play music, or carry out different animations on the entrance finish because the textual content is being spoken. This functionality is helpful for creating dynamic audio books, instructional content material, and richer text-to-speech functions.
Answer overview
At its core, the answer makes use of Amazon Polly to transform a string of textual content into speech. The textual content may be enter from the browser or via an API name to the endpoint uncovered by our resolution. The speech generated by Amazon Polly is saved as an audio file (MP3 format) in an Amazon Simple Storage Service (Amazon S3) bucket.
Nevertheless, utilizing the audio file alone, the browser can’t discover what components of the textual content are being spoken at any prompt as a result of we don’t have granular data on when every phrase is spoken.
Amazon Polly offers a approach to receive this utilizing speech marks. Speech marks are saved in a textual content file that reveals the time (measured in milliseconds from begin of the audio) when every phrase or sentence is spoken.
Amazon Polly returns speech mark objects in a line-delimited JSON stream. A speech mark object comprises the next fields:
- Time – The timestamp in milliseconds from the start of the corresponding audio stream
- Sort – The kind of speech mark (sentence, phrase, viseme, or SSML)
- Begin – The offset in bytes (not characters) of the beginning of the article within the enter textual content (not together with viseme marks)
- Finish – The offset in bytes (not characters) of the article’s finish within the enter textual content (not together with viseme marks)
- Worth – This varies relying on the kind of speech mark:
- SSML – <mark> SSML tag
- Viseme – The viseme identify
- Phrase or sentence – A substring of the enter textual content as delimited by the beginning and finish fields
For instance, the sentence “Mary had a bit of lamb” can provide the following speech marks file if you happen to use SpeechMarkTypes = [“word”, “sentence”] within the API name to acquire the speech marks:
The phrase “had” (on the finish of line 3) begins 373 milliseconds after the audio stream begins, begins at byte 5, and ends at byte 8 of the enter textual content.
Structure overview
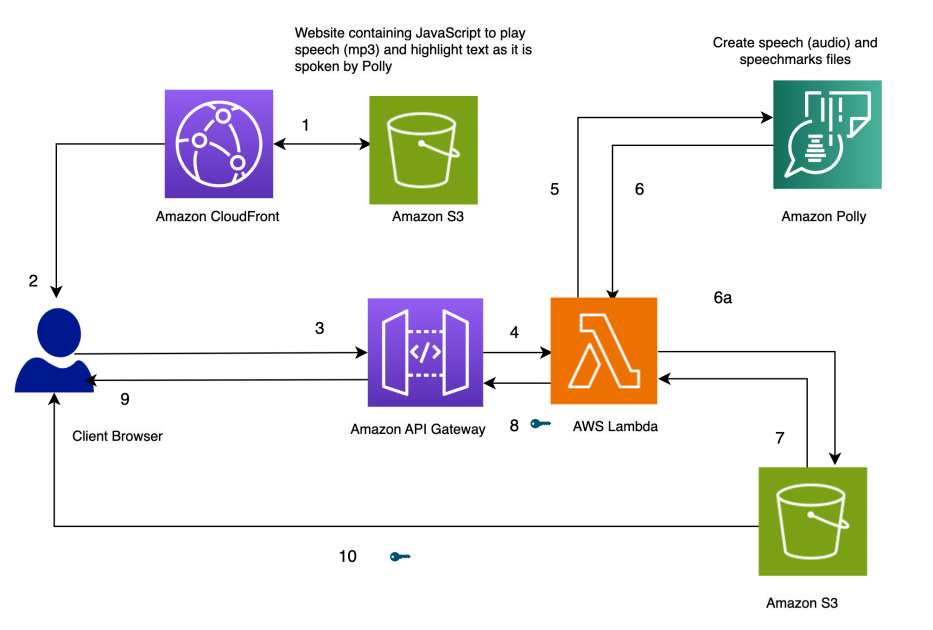
The structure of our resolution is introduced within the following diagram.
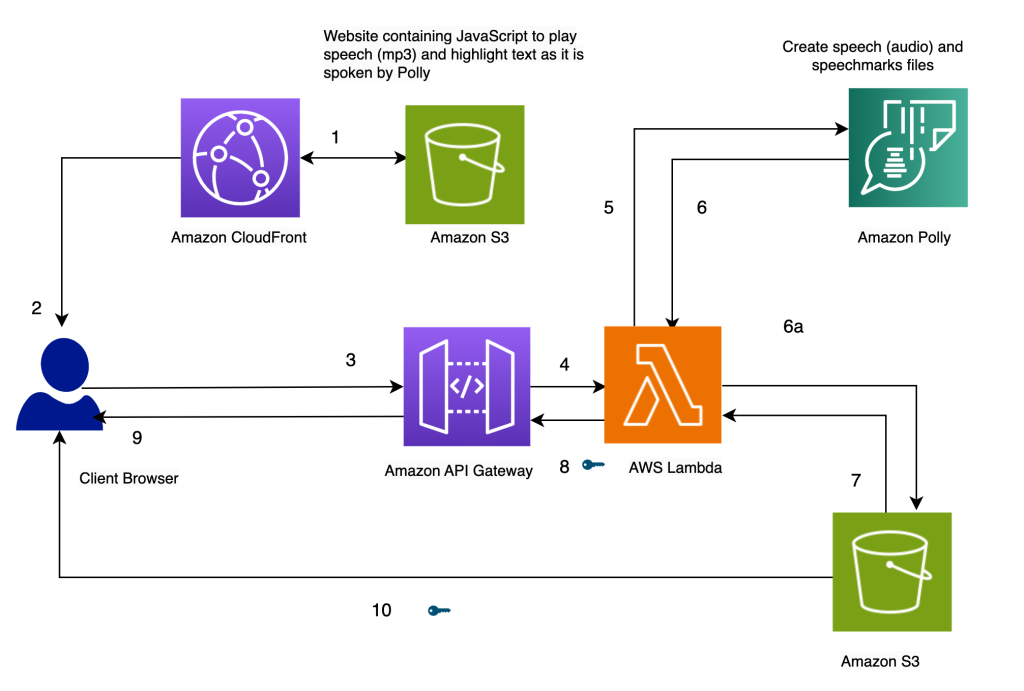
Spotlight Textual content because it’s spoken, utilizing Amazon Polly
Our web site for the answer is saved on Amazon S3 as static recordsdata (JavaScript, HTML), that are hosted in Amazon CloudFront (1) and served to the end-user’s browser (2).
When the consumer enters textual content within the browser via a easy HTML kind, it’s processed by JavaScript within the browser. This calls an API (3) via Amazon API Gateway, to invoke an AWS Lambda operate (4). The Lambda operate calls Amazon Polly (5) to generate speech (audio) and speech marks (JSON) recordsdata. Two calls are made to Amazon Polly to fetch the audio and speech marks recordsdata. The calls are made utilizing JavaScript async capabilities. The output of those calls is the audio and speech marks recordsdata, that are saved in Amazon S3 (6a). To keep away from a number of customers overwriting every others’ recordsdata within the S3 bucket, the recordsdata are saved in a folder with a timestamp. This minimizes the probabilities of two customers overwriting every others’ recordsdata in Amazon S3. For a manufacturing launch, we will make use of extra strong approaches to segregate customers’ recordsdata based mostly on consumer ID or timestamp and different distinctive traits.
The Lambda operate creates pre-signed URLs for the speech and speech marks recordsdata and returns them to the browser within the type of an array (7, 8, 9).
When the browser sends the textual content file to the API endpoint (3), it will get again two pre-signed URLs for the audio file and the speech marks file in a single synchronous invocation (9). That is indicated by the important thing image subsequent to the arrow.
A JavaScript operate within the browser fetches the speech marks file and the audio from their URL handles (10). It units up the audio participant to play the audio. (The HTML audio tag is used for this objective).
When the consumer clicks the play button, it parses the speech marks retrieved within the earlier step to create a sequence of timed occasions utilizing timeouts. The occasions invoke a callback operate, which is one other JavaScript operate used to focus on the spoken textual content within the browser. Concurrently, the JavaScript operate streams the audio file from its URL deal with.
The result’s that the occasions are run on the applicable instances to focus on the textual content because it’s spoken whereas the audio is being performed. The usage of JavaScript timeouts offers us the synchronization of the audio with the highlighted textual content.
Conditions
To run this resolution, you want an AWS account with an AWS Identity and Access Management (IAM) consumer who has permission to make use of Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda, and AWS Step Features.
Use Lambda to generate speech and speech marks
The next code invokes the Amazon Polly synthesize_speech operate two instances to fetch the audio and speech marks file. They’re run as asynchronous capabilities and coordinated to return the outcome on the identical time utilizing guarantees.
On the JavaScript facet, the textual content highlighting is completed by highlighter(begin, end, phrase) and the timed occasions are set by setTimers():
Different approaches
As an alternative of the earlier strategy, you’ll be able to contemplate just a few options:
- Create each the speech marks and audio recordsdata inside a Step Features state machine. The state machine can invoke the parallel department situation to invoke two totally different Lambda capabilities: one to generate speech and one other to generate speech marks. The code for this may be discovered within the using-step-functions subfolder within the Github repo.
- Invoke Amazon Polly asynchronously to generate the audio and speech marks. This strategy can be utilized if the textual content content material is giant or the consumer doesn’t want a real-time response. For extra particulars about creating lengthy audio recordsdata, confer with Creating Long Audio Files.
- Have Amazon Polly create the presigned URL instantly utilizing the
generate_presigned_urlname on the Amazon Polly consumer in Boto3. Should you go along with this strategy, Amazon Polly generates the audio and speech marks newly each time. In our present strategy, we retailer these recordsdata in Amazon S3. Though these saved recordsdata aren’t accessible from the browser in our model of the code, you’ll be able to modify the code to play beforehand generated audio recordsdata by fetching them from Amazon S3 (as an alternative of regenerating the audio for the textual content once more utilizing Amazon Polly). We now have extra code examples for accessing Amazon Polly with Python within the AWS Code Library.
Create the answer
The whole resolution is offered from our Github repo. To create this resolution in your account, comply with the directions within the README.md file. The answer consists of an AWS CloudFormation template to provision your sources.
Cleanup
To wash up the sources created on this demo, carry out the next steps:
- Delete the S3 buckets created to retailer the CloudFormation template (Bucket A), the supply code (Bucket B) and the web site (
pth-cf-text-highlighter-website-[Suffix]). - Delete the CloudFormation stack
pth-cf. - Delete the S3 bucket containing the speech recordsdata (
pth-speech-[Suffix]). This bucket was created by the CloudFormation template to retailer the audio and speech marks recordsdata generated by Amazon Polly.
Abstract
On this submit, we confirmed an instance of an answer that may spotlight textual content because it’s being spoken utilizing Amazon Polly. It was developed utilizing the Amazon Polly speech marks characteristic, which offers us markers for the place every phrase or sentence begins in an audio file.
The answer is offered as a CloudFormation template. It may be deployed as is to any net utility that performs text-to-speech conversion. This is able to be helpful for including visible capabilities to audio in books, avatars with lip-sync capabilities (utilizing viseme speech marks), web sites, and blogs, and for aiding individuals with listening to impairments.
It may be prolonged to carry out further duties in addition to highlighting textual content. For instance, the browser can present photographs, play music, and carry out different animations on the entrance finish whereas the textual content is being spoken. This functionality may be helpful for creating dynamic audio books, instructional content material, and richer text-to-speech functions.
We welcome you to check out this resolution and be taught extra concerning the related AWS providers from the next hyperlinks. You’ll be able to prolong the performance on your particular wants.
Concerning the Creator
 Varad G Varadarajan is a Trusted Advisor and Subject CTO for Digital Native Companies (DNB) prospects at AWS. He helps them architect and construct modern options at scale utilizing AWS services. Varad’s areas of curiosity are IT technique consulting, structure, and product administration. Outdoors of labor, Varad enjoys inventive writing, watching motion pictures with household and associates, and touring.
Varad G Varadarajan is a Trusted Advisor and Subject CTO for Digital Native Companies (DNB) prospects at AWS. He helps them architect and construct modern options at scale utilizing AWS services. Varad’s areas of curiosity are IT technique consulting, structure, and product administration. Outdoors of labor, Varad enjoys inventive writing, watching motion pictures with household and associates, and touring.





