In-Database Analytics: Leveraging SQL’s Analytic Features


Picture by Creator
Everyone knows the significance of knowledge evaluation in as we speak’s data-driven world and the way it presents us invaluable insights from the out there information. However typically, information evaluation turns into very difficult and time-consuming for the information analyst. The primary cause it has turn out to be hectic these days is the exploded quantity of generated information and the necessity for exterior instruments to carry out complicated evaluation methods on it.
However what if we analyse information throughout the database itself and with considerably simplified queries? This may be made doable utilizing SQL Analytic capabilities. This text will focus on numerous SQL analytic capabilities that may be executed throughout the SQL Server and procure us invaluable outcomes.
These capabilities calculate the combination worth primarily based on a gaggle of rows and transcend fundamental row operations. They supply us with instruments for rating, time collection calculations, windowing and pattern evaluation. So with out losing any additional time, let’s begin discussing these capabilities one after the other with some particulars and sensible examples. The pre-requisite of this tutorial is the essential sensible information of SQL queries.
We’ll create a demo desk and apply all of the analytic capabilities on this desk so that you just simply observe together with the tutorial.
Be aware: Some capabilities mentioned on this tutorial should not current in SQLite. So it’s preferable to make use of MySQL or PostgreSQL Server.
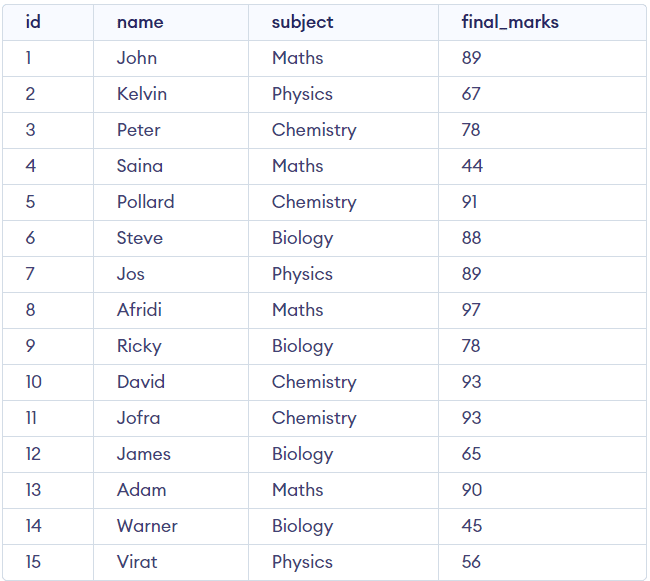
This desk accommodates the information of a number of college college students, containing 4 columns Pupil ID, Pupil Identify, Topic and Last Marks out of 100.
Making a College students Desk containing 4 columns:
CREATE TABLE college students
(
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
topic VARCHAR(30),
final_marks INT
);
Now, we’ll insert some dummy information into that desk.
INSERT INTO College students (id, title, topic, final_marks)
VALUES (1, 'John', 'Maths', 89),
(2, 'Kelvin', 'Physics', 67),
(3, 'Peter', 'Chemistry', 78),
(4, 'Saina', 'Maths', 44),
(5, 'Pollard', 'Chemistry', 91),
(6, 'Steve', 'Biology', 88),
(7, 'Jos', 'Physics', 89),
(8, 'Afridi', 'Maths', 97),
(9, 'Ricky', 'Biology', 78),
(10, 'David', 'Chemistry', 93),
(11, 'Jofra', 'Chemistry', 93),
(12, 'James', 'Biology', 65),
(13, 'Adam', 'Maths', 90),
(14, 'Warner', 'Biology', 45),
(15, 'Virat', 'Physics', 56);
Now we’ll visualize our desk.
Output:
We’re able to execute the analytic capabilities.
RANK() operate will assign a selected rank to every row inside a partition primarily based on the required order. If the rows have equivalent values throughout the similar partition, it assigns them the identical rank.
Let’s perceive it extra clearly with the beneath instance.
SELECT *,
Rank()
OVER (
ORDER BY final_marks DESC) AS 'ranks'
FROM college students;
Output:
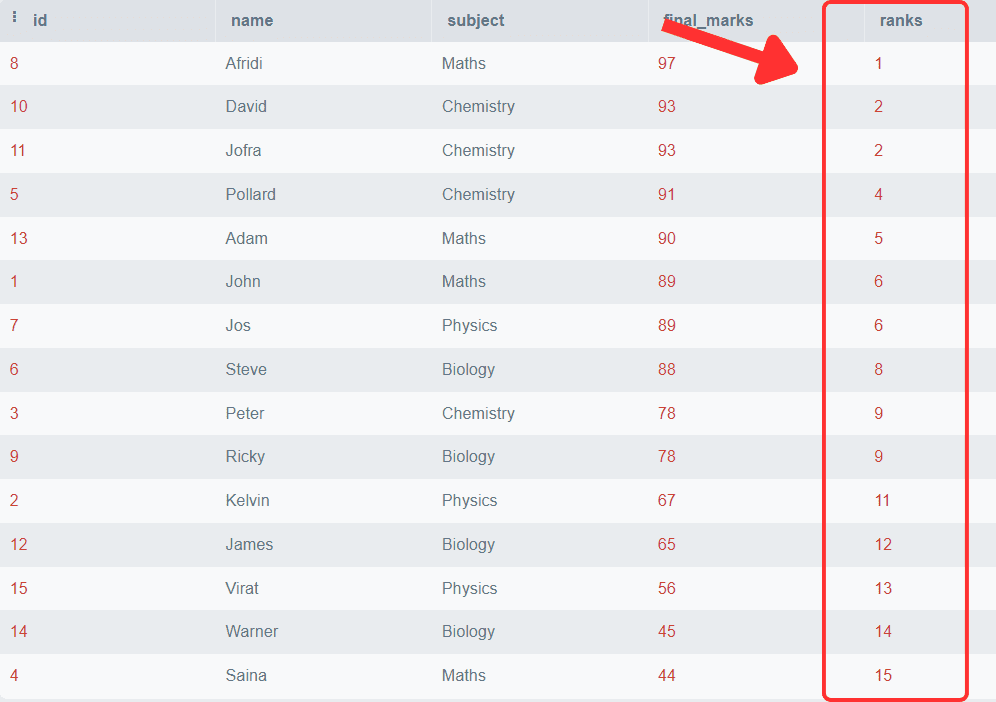
You’ll be able to observe that the ultimate marks are organized in descending order, and a selected rank is related to every row. You may as well observe that the scholars with the identical marks get the identical rank, and the next rank after the duplicate row is skipped.
We are able to additionally discover toppers of every topic, i.e. we will partition the rank primarily based on the themes. Let’s see methods to do it.
SELECT *,
Rank()
OVER (
PARTITION BY topic
ORDER BY final_marks DESC) AS 'ranks'
FROM college students;
Output:
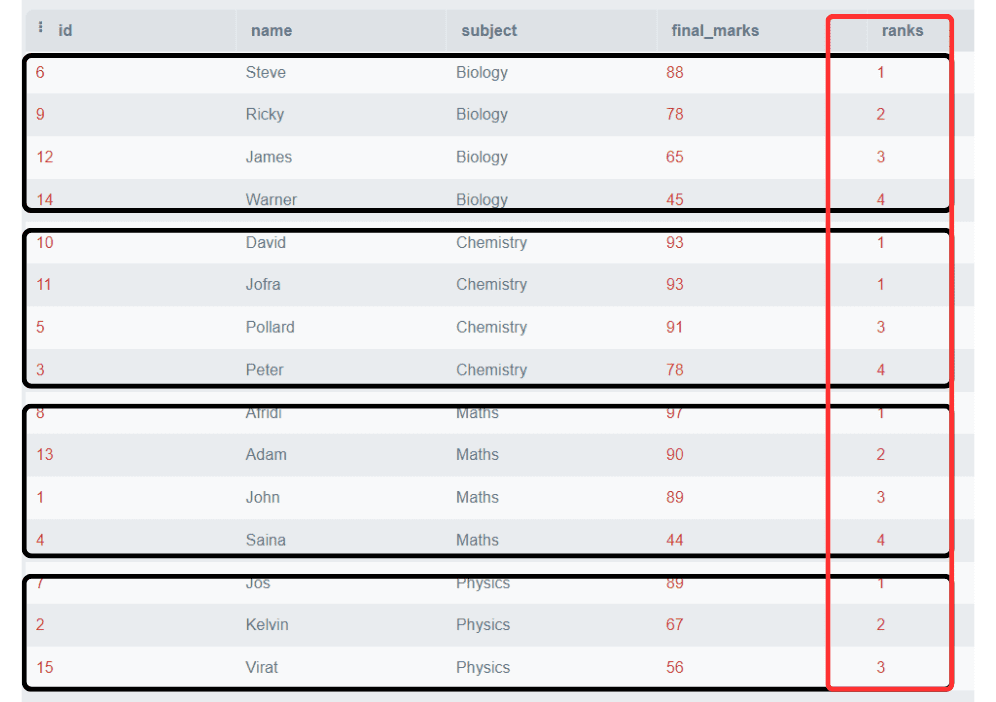
On this instance, we have now partitioned the rating primarily based on topics and the ranks are allotted individually for every topic.
Be aware: Please observe that two college students acquired the identical marks within the Chemistry topic, ranked as 1, and the rank for the following row instantly begins from 3. It skips the rank of two.
That is the function of the RANK() operate that it’s not at all times obligatory to provide ranks consecutively. The following rank would be the sum of the earlier rank and the duplicate numbers.
To beat this drawback, DENSE_RANK() is launched to work equally to the RANK() operate, nevertheless it at all times assigns rank consecutively. Comply with the beneath instance:
SELECT *,
DENSE_RANK()
OVER (
PARTITION BY topic
ORDER BY final_marks DESC) AS 'ranks'
FROM college students;
Output:
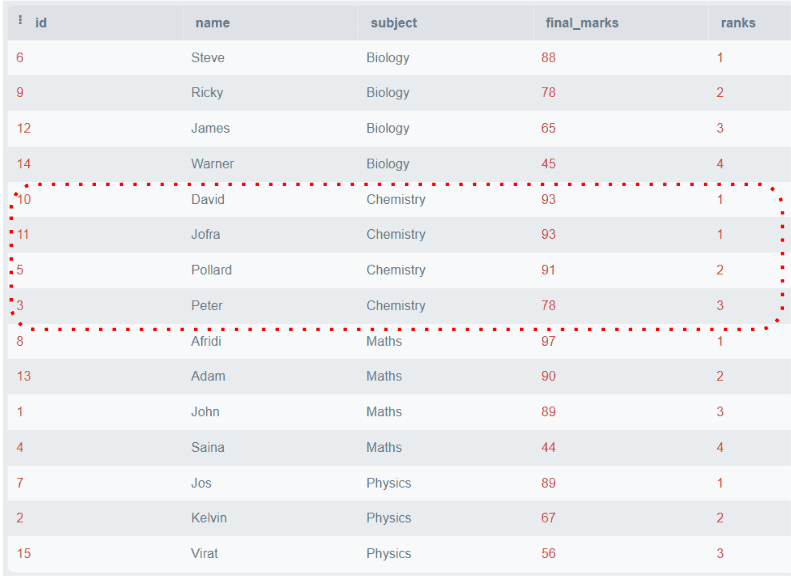
The above determine exhibits that every one the ranks are consecutive, even when duplicate marks are in the identical partition.
NTILE() operate is used to divide the rows right into a specified quantity (N) of roughly equal-sized buckets. Every row is assigned a bucket quantity ranging from 1 to N (Complete variety of buckets).
We are able to additionally apply NTILE() operate on a selected partition or order, that are specified within the PARTITION BY and ORDER BY clauses.
Suppose N shouldn’t be completely divisible by the variety of rows. Then the operate will create buckets of various sizes with the distinction of 1.
Syntax:
NTILE(n) OVER (PARTITION BY c1, c2 ORDER BY c3)
The NTILE() operate takes one required parameter N, i.e. the variety of buckets and a few optionally available parameters like PARTITION BY and ORDER BY clause. NTILE() will divide the rows primarily based on the order specified by these clauses.
Let’s take an instance contemplating our “College students” desk. Suppose we wish to divide the scholars into teams primarily based on their remaining marks. We’ll create three teams. Group 1 will include the scholars with the best marks. Group 2 could have all of the mediocre college students, and Group 3 will embody the scholars with low marks.
SELECT *,
NTILE(3)
OVER (
ORDER BY final_marks DESC) AS bucket
FROM college students;
Output:
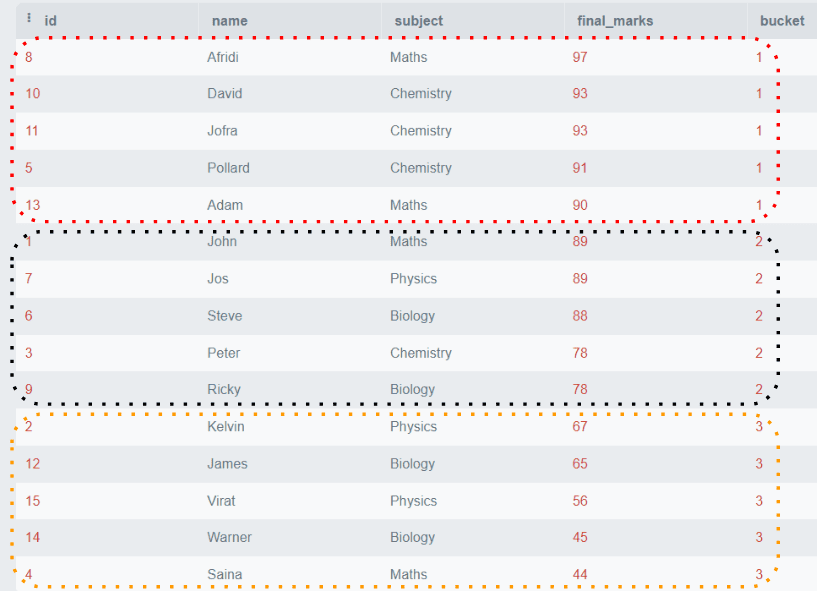
The above instance exhibits that every one the rows are ordered by final_marks and divided into three teams containing 5 rows per group.
NTILE() is helpful after we wish to divide some information into equal teams in accordance with some specified standards. It may be used within the purposes like buyer segmentation primarily based on objects bought or categorizing worker efficiency, and so on.
The CUME_DIST() operate finds the cumulative distribution of a selected worth in every row inside a partition or order specified. Cumulative Distribution Perform (CDF) denotes the chance that the random variable X is lower than or equal to x. It’s denoted by F(x), and its mathematical system is represented as,
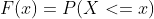
P(x) is the Likelihood Distribution Perform.
In easy language, CUME_DIST() operate returns the proportion of rows whose worth is lower than equal to the present row worth. It can assist to investigate the distribution of knowledge and in addition the relative place of a worth with the set.
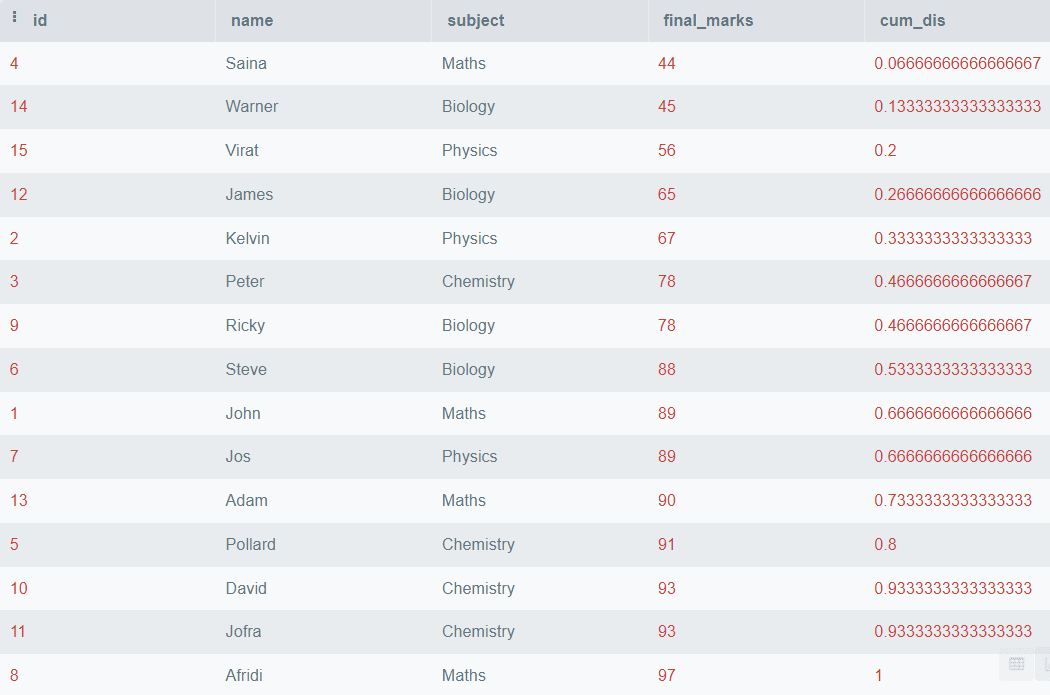
SELECT *,
CUME_DIST()
OVER (
ORDER BY final_marks) AS cum_dis
FROM college students;
Output:
The above code will order all of the rows primarily based on final_marks and discover the Cumulative Distribution, however if you wish to partition the information primarily based on the themes, you should use the PARTITION BY clause. Beneath is an instance of methods to do it.
SELECT *,
CUME_DIST()
OVER (
PARTITION BY topic
ORDER BY final_marks) AS cum_dis
FROM college students;
Output:
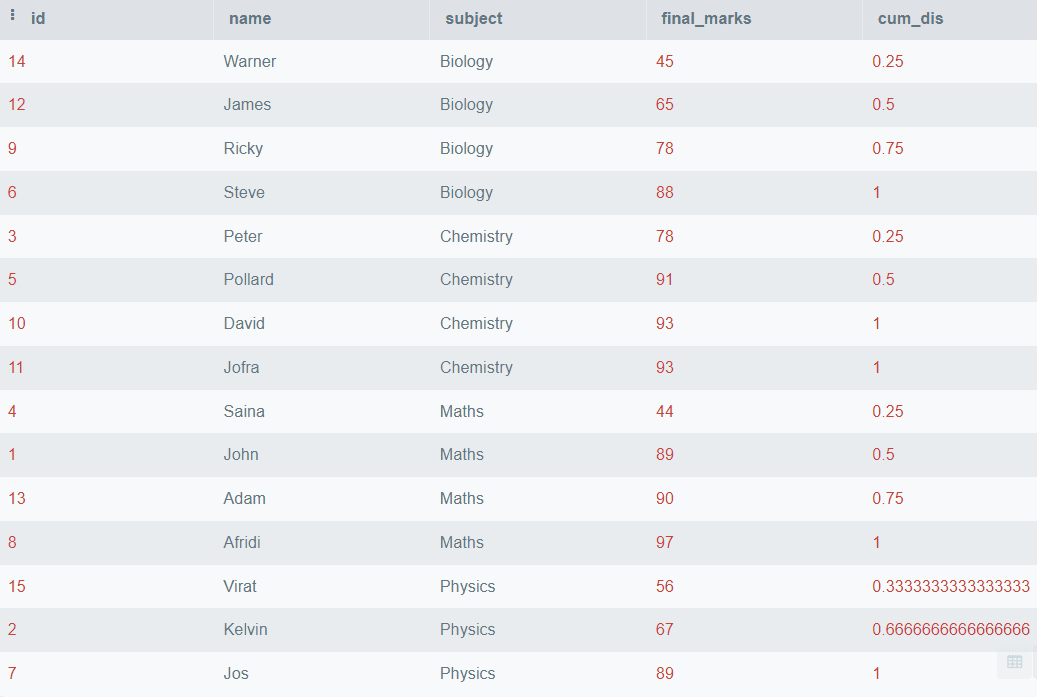
Within the above output, we have now seen the cumulative distribution of final_marks partitioned by the topic title.
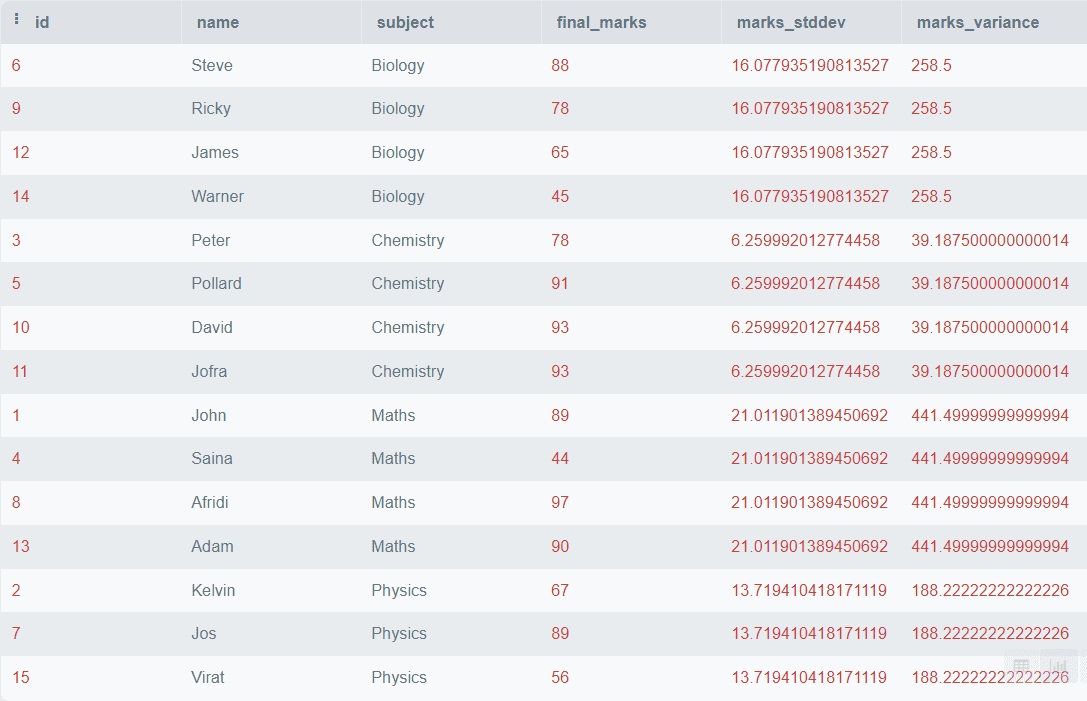
TheVARIANCE() operate is used to search out the variance of a given worth throughout the partition. In statistics, Variance represents how a quantity is much from its imply worth, or it represents the diploma of unfold between numbers. It’s represented by ?^2.
The STDDEV() operate is used to search out the usual deviation of a given worth throughout the partition. Commonplace Deviation additionally measures the variation within the information, and it equals the sq. root of the variance. It’s represented by ?.
These parameters might help us to search out dispersion and variability within the information. Let’s see how can we do it virtually.
SELECT *,
STDDEV(final_marks)
OVER (
PARTITION BY topic) AS marks_stddev,
VARIANCE(final_marks)
OVER (
PARTITION BY topic) AS marks_variance
FROM college students;
Output:
The above output exhibits the Commonplace Variation and the Variance of the ultimate marks for every topic.
The FIRST_VALUE() operate will output the primary worth of a partition primarily based on a selected ordering. Equally, the LAST_VALUE() operate will output the final worth of that partition. These capabilities can be utilized after we wish to establish the primary and final prevalence of a specified partition.
Syntax:
SELECT *,
FIRST_VALUE(col1)
OVER (
PARTITION BY col2, col3
ORDER BY col4) AS first_value
FROM table_name
SQL Analytic Features present us with the capabilities to carry out information evaluation throughout the SQL server. Utilizing these capabilities, we will unlock the true potential of the information and get invaluable insights from it to extend our enterprise. Aside from the capabilities mentioned above, there are numerous extra wonderful capabilities which will remedy your complicated issues in a short time. You’ll be able to learn extra about these Analytical Features from this article by Microsoft.
Aryan Garg is a B.Tech. Electrical Engineering pupil, presently within the remaining 12 months of his undergrad. His curiosity lies within the subject of Net Improvement and Machine Studying. He have pursued this curiosity and am wanting to work extra in these instructions.




