Find out how to Construct a Streaming Semi-structured Analytics Platform on Snowflake


Picture by Editor
Snowflake is a SaaS, i.e., software program as a service that’s properly fitted to working analytics on massive volumes of information. The platform is supremely simple to make use of and is properly fitted to enterprise customers, analytics groups, and many others., to get worth from the ever-increasing datasets. This text will undergo the parts of making a streaming semi-structured analytics platform on Snowflake for healthcare information. We may also undergo some key concerns throughout this section.
There are a number of totally different information codecs that the healthcare trade as a complete helps however we are going to take into account one of many newest semi-structured codecs i.e. FHIR (Quick Healthcare Interoperability Assets) for constructing our analytics platform. This format normally possesses all of the patient-centric info embedded inside 1 JSON doc. This format accommodates a plethora of data, like all hospital encounters, lab outcomes, and many others. The analytics staff, when supplied with a queryable information lake, can extract precious info comparable to what number of sufferers have been recognized with most cancers, and many others. Let’s go along with the idea that every one such JSON information are pushed on AWS S3 (or every other public cloud storage) each quarter-hour by way of totally different AWS companies or finish API endpoints.
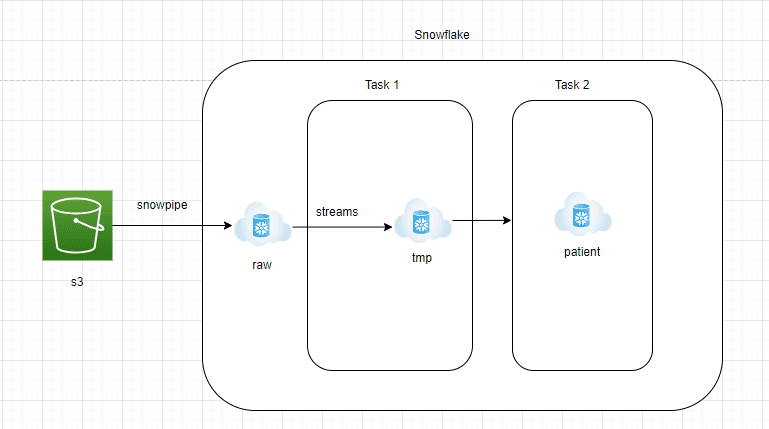
- AWS S3 to Snowflake RAW zone:
- Information must be repeatedly streamed from AWS S3 into the RAW zone of Snowflake.
- Snowflake presents Snowpipe managed service, which might learn JSON information from S3 in a steady streaming method.
- A desk with a variant column must be created within the Snowflake RAW zone to carry the JSON information within the native format.
- Snowflake RAW Zone to Streams:
- Streams is managed change information seize service which is able to basically be capable to seize all the brand new incoming JSON paperwork into Snowflake RAW zone
- Streams can be pointed to the Snowflake RAW Zone desk and must be set to append=true
- Streams are identical to any desk and simply queryable.
- Snowflake Process 1:
- Snowflake Process is an object that’s much like a scheduler. Queries or saved procedures will be scheduled to run utilizing cron job notations
- On this structure, we create Process 1 to fetch the information from Streams and ingest them right into a staging desk. This layer can be truncated and reload
- That is achieved to make sure new JSON paperwork are processed each quarter-hour
- Snowflake Process 2:
- This layer will convert the uncooked JSON doc into reporting tables that the analytics staff can simply question.
- To transform JSON paperwork into structured format, the lateral flatten characteristic of Snowflake can be utilized.
- Lateral flatten is an easy-to-use perform that explodes the nested array parts and will be simply extracted utilizing the ‘:’ notation.
- Snowpipe is advisable for use with a couple of massive information. The fee might go excessive if small information on exterior storage aren’t clubbed collectively
- In a manufacturing setting, guarantee automated processes are created to observe streams since as soon as they go stale, information can’t be recovered from them
- The utmost allowed dimension of a single JSON doc is 16MB compressed that may be loaded into Snowflake. In case you have big JSON paperwork that exceed these dimension limits, guarantee you might have a course of to separate them earlier than ingesting them into Snowflake
Managing semi-structured information is all the time difficult as a result of nested construction of parts embedded contained in the JSON paperwork. Contemplate the gradual and exponential enhance of the amount of incoming information earlier than designing the ultimate reporting layer. This text goals to exhibit how simple it’s to construct a streaming pipeline with semi-structured information.
Milind Chaudhari is a seasoned information engineer/information architect who has a decade of labor expertise in constructing information lakes/lakehouses utilizing quite a lot of standard & trendy instruments. He’s extraordinarily obsessed with information streaming structure and can also be a technical reviewer with Packt & O’Reilly.




