Environment friendly parallel audio technology – Google AI Weblog
The current progress in generative AI unlocked the opportunity of creating new content material in a number of completely different domains, together with textual content, imaginative and prescient and audio. These fashions usually depend on the truth that uncooked knowledge is first transformed to a compressed format as a sequence of tokens. Within the case of audio, neural audio codecs (e.g., SoundStream or EnCodec) can effectively compress waveforms to a compact illustration, which could be inverted to reconstruct an approximation of the unique audio sign. Such a illustration consists of a sequence of discrete audio tokens, capturing the native properties of sounds (e.g., phonemes) and their temporal construction (e.g., prosody). By representing audio as a sequence of discrete tokens, audio technology could be carried out with Transformer-based sequence-to-sequence fashions — this has unlocked fast progress in speech continuation (e.g., with AudioLM), text-to-speech (e.g., with SPEAR-TTS), and normal audio and music technology (e.g., AudioGen and MusicLM). Many generative audio fashions, together with AudioLM, depend on auto-regressive decoding, which produces tokens one after the other. Whereas this technique achieves excessive acoustic high quality, inference (i.e., calculating an output) could be gradual, particularly when decoding lengthy sequences.
To handle this problem, in “SoundStorm: Efficient Parallel Audio Generation”, we suggest a brand new technique for environment friendly and high-quality audio technology. SoundStorm addresses the issue of producing lengthy audio token sequences by counting on two novel components: 1) an structure tailored to the precise nature of audio tokens as produced by the SoundStream neural codec, and a couple of) a decoding scheme impressed by MaskGIT, a lately proposed technique for picture technology, which is tailor-made to function on audio tokens. In comparison with the autoregressive decoding strategy of AudioLM, SoundStorm is ready to generate tokens in parallel, thus reducing the inference time by 100x for lengthy sequences, and produces audio of the identical high quality and with larger consistency in voice and acoustic situations. Furthermore, we present that SoundStorm, coupled with the text-to-semantic modeling stage of SPEAR-TTS, can synthesize high-quality, pure dialogues, permitting one to regulate the spoken content material (through transcripts), speaker voices (through quick voice prompts) and speaker turns (through transcript annotations), as demonstrated by the examples under:
| Enter: Textual content (transcript used to drive the audio technology in daring) | One thing actually humorous occurred to me this morning. | Oh wow, what? | Effectively, uh I awoke as common. | Uhhuh | Went downstairs to have uh breakfast. | Yeah | Began consuming. Then uh 10 minutes later I spotted it was the midnight. | Oh no approach, that is so humorous! | I did not sleep effectively final night time. | Oh, no. What occurred? | I do not know. I I simply could not appear to uh to go to sleep someway, I stored tossing and turning all night time. | That is too dangerous. Possibly you must uh strive going to mattress earlier tonight or uh possibly you could possibly strive studying a e book. | Yeah, thanks for the solutions, I hope you are proper. | No drawback. I I hope you get a very good night time’s sleep | ||
| Enter: Audio immediate |
|
|
||
| Output: Audio immediate + generated audio |
|
|
SoundStorm design
In our earlier work on AudioLM, we confirmed that audio technology could be decomposed into two steps: 1) semantic modeling, which generates semantic tokens from both earlier semantic tokens or a conditioning sign (e.g., a transcript as in SPEAR-TTS, or a textual content immediate as in MusicLM), and a couple of) acoustic modeling, which generates acoustic tokens from semantic tokens. With SoundStorm we particularly deal with this second, acoustic modeling step, changing slower autoregressive decoding with sooner parallel decoding.
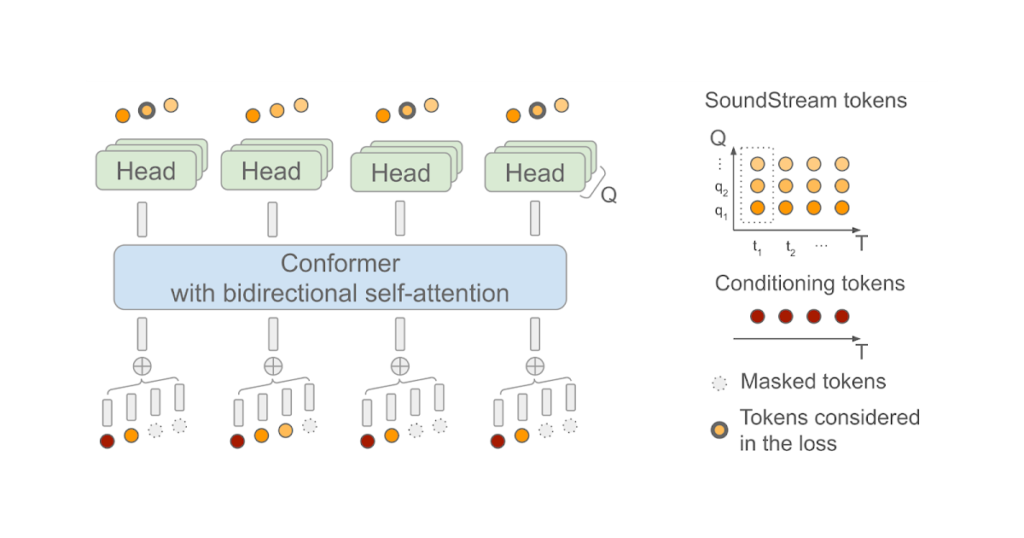
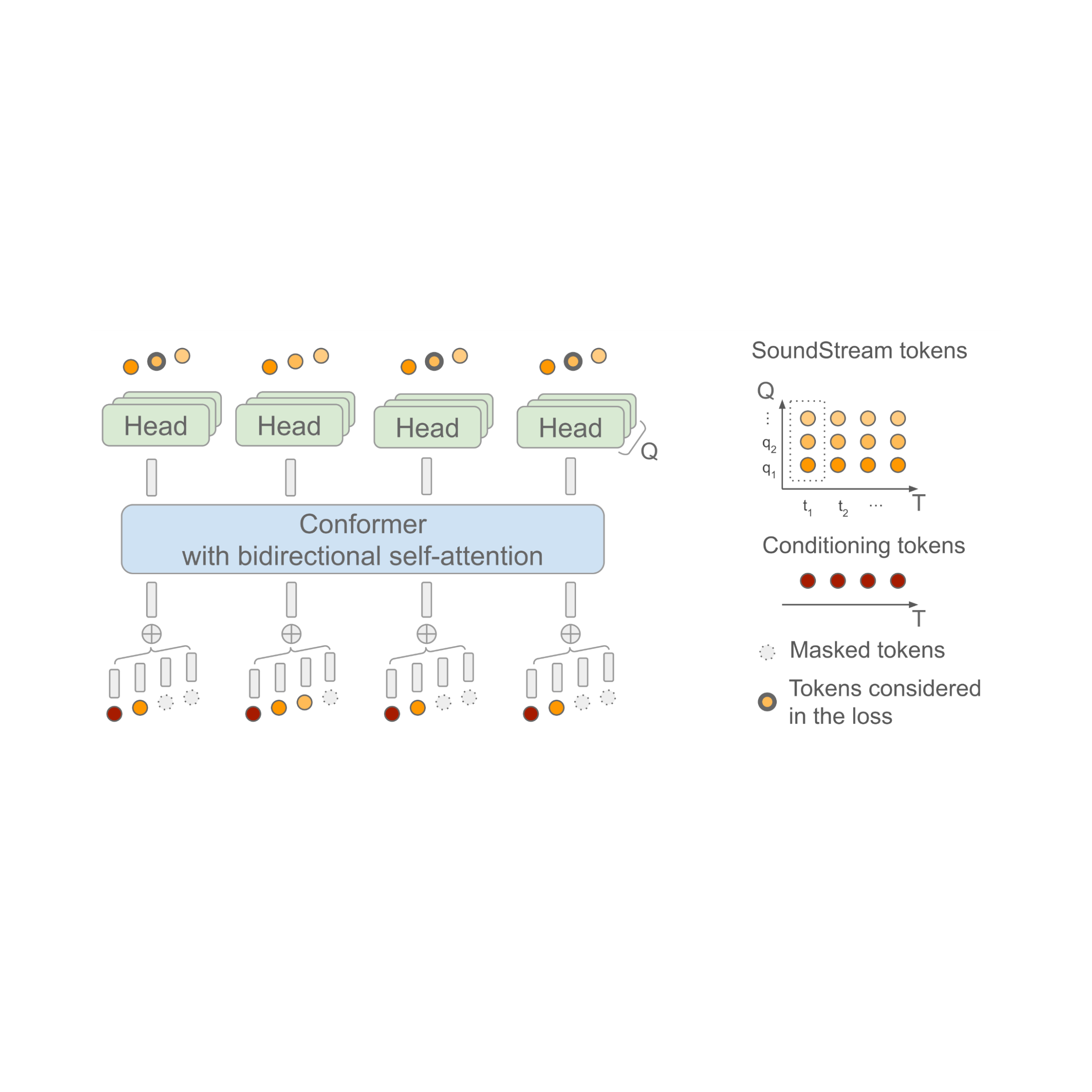
SoundStorm depends on a bidirectional attention-based Conformer, a mannequin structure that mixes a Transformer with convolutions to seize each native and international construction of a sequence of tokens. Particularly, the mannequin is skilled to foretell audio tokens produced by SoundStream given a sequence of semantic tokens generated by AudioLM as enter. When doing this, it is very important bear in mind the truth that, at every time step t, SoundStream makes use of as much as Q tokens to symbolize the audio utilizing a way often known as residual vector quantization (RVQ), as illustrated under on the precise. The important thing instinct is that the standard of the reconstructed audio progressively will increase because the variety of generated tokens at every step goes from 1 to Q.
At inference time, given the semantic tokens as enter conditioning sign, SoundStorm begins with all audio tokens masked out, and fills within the masked tokens over a number of iterations, ranging from the coarse tokens at RVQ stage q = 1 and continuing level-by-level with finer tokens till reaching stage q = Q.
There are two essential points of SoundStorm that allow quick technology: 1) tokens are predicted in parallel throughout a single iteration inside a RVQ stage and, 2) the mannequin structure is designed in such a approach that the complexity is barely mildly affected by the variety of ranges Q. To assist this inference scheme, throughout coaching a fastidiously designed masking scheme is used to imitate the iterative course of used at inference.
 |
| SoundStorm mannequin structure. T denotes the variety of time steps and Q the variety of RVQ ranges utilized by SoundStream. The semantic tokens used as conditioning are time-aligned with the SoundStream frames. |
Measuring SoundStorm efficiency
We exhibit that SoundStorm matches the standard of AudioLM’s acoustic generator, changing each AudioLM’s stage two (coarse acoustic mannequin) and stage three (advantageous acoustic mannequin). Moreover, SoundStorm produces audio 100x sooner than AudioLM’s hierarchical autoregressive acoustic generator (high half under) with matching high quality and improved consistency by way of speaker id and acoustic situations (backside half under).
 |
| Runtimes of SoundStream decoding, SoundStorm and completely different phases of AudioLM on a TPU-v4. |
 |
| Acoustic consistency between the immediate and the generated audio. The shaded space represents the inter-quartile vary. |
Security and threat mitigation
We acknowledge that the audio samples produced by the mannequin could also be influenced by the unfair biases current within the coaching knowledge, as an illustration by way of represented accents and voice traits. In our generated samples, we exhibit that we will reliably and responsibly management speaker traits through prompting, with the objective of avoiding unfair biases. An intensive evaluation of any coaching knowledge and its limitations is an space of future work in keeping with our accountable AI Principles.
In flip, the flexibility to imitate a voice can have quite a few malicious functions, together with bypassing biometric identification and utilizing the mannequin for the aim of impersonation. Thus, it’s essential to place in place safeguards towards potential misuse: to this finish, we have now verified that the audio generated by SoundStorm stays detectable by a devoted classifier utilizing the identical classifier as described in our authentic AudioLM paper. Therefore, as a part of a bigger system, we imagine that SoundStorm could be unlikely to introduce extra dangers to these mentioned in our earlier papers on AudioLM and SPEAR-TTS. On the similar time, stress-free the reminiscence and computational necessities of AudioLM would make analysis within the area of audio technology extra accessible to a wider group. Sooner or later, we plan to discover different approaches for detecting synthesized speech, e.g., with the assistance of audio watermarking, in order that any potential product utilization of this expertise strictly follows our accountable AI Rules.
Conclusion
Now we have launched SoundStorm, a mannequin that may effectively synthesize high-quality audio from discrete conditioning tokens. When in comparison with the acoustic generator of AudioLM, SoundStorm is 2 orders of magnitude sooner and achieves larger temporal consistency when producing lengthy audio samples. By combining a text-to-semantic token mannequin much like SPEAR-TTS with SoundStorm, we will scale text-to-speech synthesis to longer contexts and generate pure dialogues with a number of speaker turns, controlling each the voices of the audio system and the generated content material. SoundStorm isn’t restricted to producing speech. For instance, MusicLM makes use of SoundStorm to synthesize longer outputs effectively (as seen at I/O).
Acknowledgments
The work described right here was authored by Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour and Marco Tagliasacchi. We’re grateful for all discussions and suggestions on this work that we obtained from our colleagues at Google.






