NTU and Microsoft Researchers Suggest MIMIC-IT: A Giant-Scale Multi-Modal in-Context Instruction Tuning Dataset
Current developments in synthetic intelligence have focused on conversational assistants with nice comprehension capabilities who can then act. The noteworthy successes of those conversational assistants could also be ascribed to the observe of instruction adjustment along with the massive language fashions’ (LLMs) excessive generalization capability. It entails optimizing LLMs for quite a lot of actions which can be described by various and glorious directions. By together with instruction adjustment, LLMs get a deeper understanding of person intentions, bettering their zero-shot efficiency even in newly unexplored duties.
Instruction tuning internalizes the context, which is fascinating in person interactions, particularly when person enter bypasses apparent context, which can be one clarification for the zero-shot pace enchancment. Conversational assistants have had superb progress in linguistic challenges. A great informal assistant, nonetheless, should be capable of deal with jobs requiring a number of modalities. An in depth and top-notch multimodal instruction-following dataset is required for this. The unique vision-language instruction-following dataset known as LLaVAInstruct-150K or LLaVA. It’s constructed using COCO footage, directions, and information from GPT-4 based mostly on merchandise bounding packing containers and picture descriptions.
LLaVA-Instruct-150K is inspirational, but it has three drawbacks. (1) Restricted visible variety: As a result of the dataset solely makes use of the COCO image, its visible variety is proscribed. (2) It makes use of a single picture as visible enter, however a multimodal conversational assistant ought to be capable of deal with a number of photographs and even prolonged movies. As an illustration, when a person asks for help in developing with an album title for a set of images (or a picture sequence, comparable to a video), the system wants to reply correctly. (3) Language-only in-context data: Whereas a multimodal conversational assistant ought to use multimodal in-context data to grasp higher person directions, language-only in-context data depends completely on language.
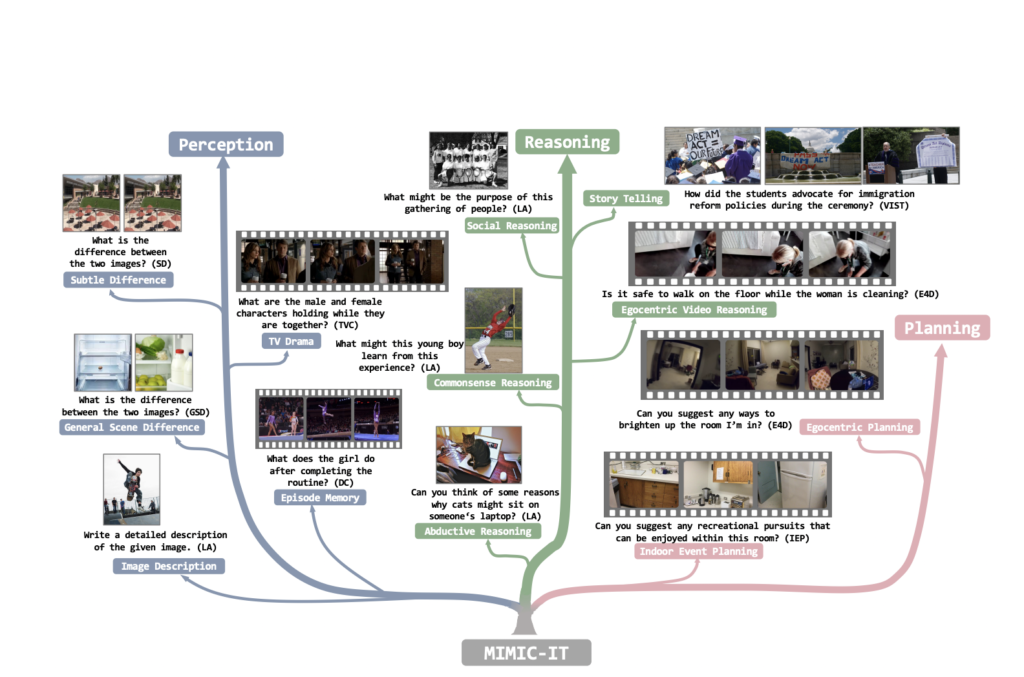
As an illustration, if a human person affords a selected visible pattern of the required options, an assistant can extra correctly align its description of a picture with the tone, fashion, or different parts. Researchers from S-Lab, Nanyang Technological College, Singapore and Microsoft Analysis, Redmond present MIMICIT (Multimodal In-Context Instruction Tuning), which addresses these restrictions. (1) Various visible scenes, integrating photographs and movies from common scenes, selfish view scenes, and indoor RGB-D photographs throughout completely different datasets, are a characteristic of MIMIC-IT. (2) A number of footage (or a video) used as visible information to assist instruction-response pairings that numerous photographs or films might accompany. (3) Multimodal in-context infor consists of in-context information offered in numerous instruction-response pairs, photographs, or movies (for extra particulars on information format, see Fig. 1).
They supply Sythus, an automatic pipeline for instruction-response annotation impressed by the self-instruct method, to successfully create instruction-response pairings. Focusing on the three core capabilities of vision-language fashions—notion, reasoning, and planning—Sythus makes use of system message, visible annotation, and in-context examples to information the language mannequin (GPT-4 or ChatGPT) in producing instruction-response pairs based mostly on visible context, together with timestamps, captions, and object data. Directions and replies are additionally translated from English into seven different languages to permit multilingual utilization. They practice a multimodal mannequin named Otter based mostly on OpenFlamingo on MIMIC-IT.

Otter’s multimodal abilities are assessed in two methods: (1) Otter performs finest within the ChatGPT analysis on the MMAGIBenchmark, which compares Otter’s perceptual and reasoning abilities to different present vision-language fashions (VLMs). (2) Human evaluation within the Multi-Modality Area, the place Otter performs higher than different VLMs and receives the best Elo rating. Otter outperforms OpenFlamingo in all few-shot circumstances, based on our analysis of its few-shot in-context studying capabilities utilizing the COCO Caption dataset.
Particularly, they offered: • The Multimodal In-Context Instruction Tuning (MIMIC-IT) dataset incorporates 2.8 million multimodal in-context instruction-response pairings with 2.2 million distinct directions in numerous real-world settings. • Syphus, an automatic course of created with LLMs to provide instruction-response pairs which can be high-quality and multilingual relying on visible context. • Otter, a multimodal mannequin, reveals skilful in-context studying and powerful multimodal notion and reasoning means, efficiently following human intent.
Test Out The Paper and GitHub link. Don’t neglect to hitch our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra. When you have any questions relating to the above article or if we missed something, be happy to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on fascinating initiatives.





