GPT4All is the Native ChatGPT in your Paperwork and it’s Free!
On this article we are going to be taught find out how to deploy and use GPT4All mannequin in your CPU solely laptop (I’m utilizing a Macbook Professional with out GPU!)

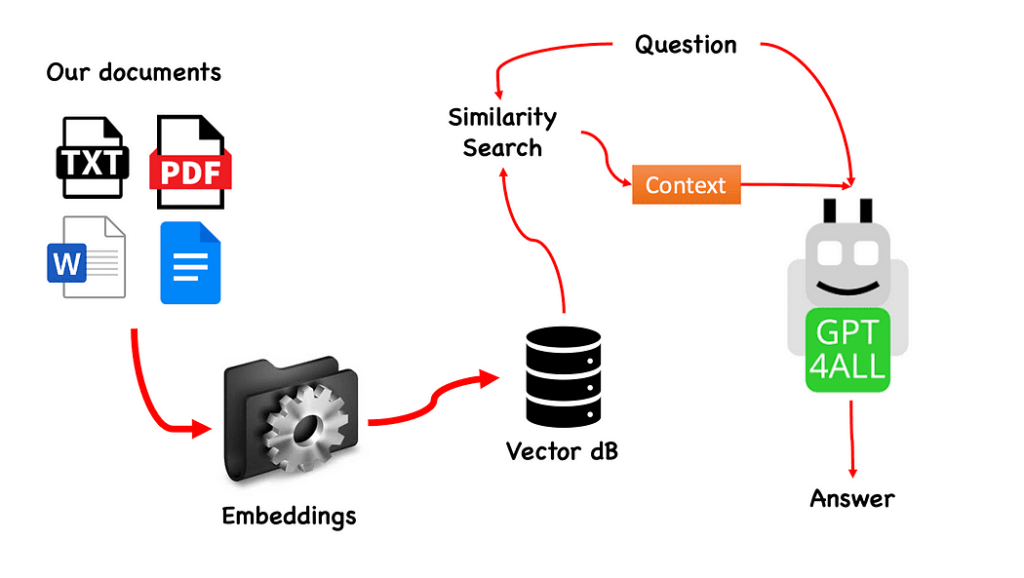
Use GPT4All on Your Laptop — Image by the creator
On this article we’re going to set up on our native laptop GPT4All (a robust LLM) and we are going to uncover find out how to work together with our paperwork with python. A group of PDFs or on-line articles would be the information base for our query/solutions.
From the official website GPT4All it’s described as a free-to-use, regionally operating, privacy-aware chatbot. No GPU or web required.
GTP4All is an ecosystem to coach and deploy highly effective and custom-made giant language fashions that run regionally on client grade CPUs.
Our GPT4All mannequin is a 4GB file that you would be able to obtain and plug into the GPT4All open-source ecosystem software program. Nomic AI facilitates top quality and safe software program ecosystems, driving the trouble to allow people and organizations to effortlessly prepare and implement their very own giant language fashions regionally.
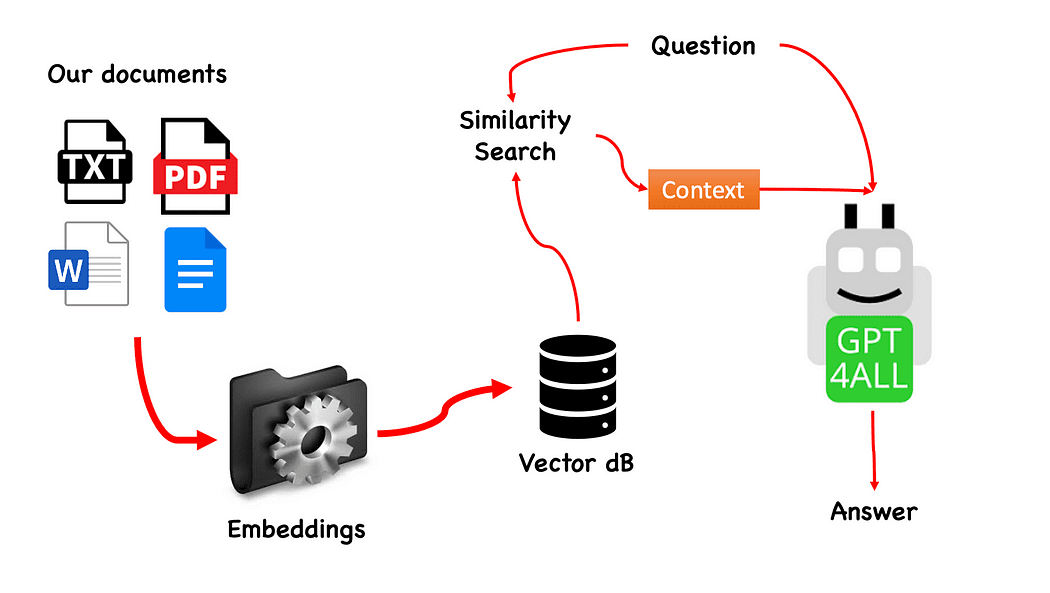
Workflow of the QnA with GPT4All — created by the creator
The method is basically easy (when it) and will be repeated with different fashions too. The steps are as follows:
- load the GPT4All mannequin
- use Langchain to retrieve our paperwork and Load them
- cut up the paperwork in small chunks digestible by Embeddings
- Use FAISS to create our vector database with the embeddings
- Carry out a similarity search (semantic search) on our vector database primarily based on the query we need to cross to GPT4All: this might be used as a context for our query
- Feed the query and the context to GPT4All with Langchain and look forward to the the reply.
So what we want is Embeddings. An embedding is a numerical illustration of a bit of data, for instance, textual content, paperwork, pictures, audio, and so forth. The illustration captures the semantic that means of what’s being embedded, and that is precisely what we want. For this mission we can not depend on heavy GPU fashions: so we are going to obtain the Alpaca native mannequin and use from Langchain the LlamaCppEmbeddings. Don’t fear! Every little thing is defined step-by-step
Create a Digital Surroundings
Create a brand new folder in your new Python mission, for instance GPT4ALL_Fabio (put your title…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabio
Subsequent, create a brand new Python digital surroundings. You probably have multiple python model put in, specify your required model: on this case I’ll use my primary set up, related to python 3.10.
The command python3 -m venv .venv creates a brand new digital surroundings named .venv (the dot will create a hidden listing referred to as venv).
A digital surroundings offers an remoted Python set up, which lets you set up packages and dependencies only for a selected mission with out affecting the system-wide Python set up or different initiatives. This isolation helps keep consistency and stop potential conflicts between completely different mission necessities.
As soon as the digital surroundings is created, you’ll be able to activate it utilizing the next command:
supply .venv/bin/activate

Activated digital surroundings
The libraries to put in
For the mission we’re constructing we don’t want too many packages. We’d like solely:
- python bindings for GPT4All
- Langchain to work together with our paperwork
LangChain is a framework for creating functions powered by language fashions. It permits you not solely to name out to a language mannequin through an API, but additionally join a language mannequin to different sources of knowledge and permit a language mannequin to work together with its surroundings.
pip set up pygpt4all==1.0.1
pip set up pyllamacpp==1.0.6
pip set up langchain==0.0.149
pip set up unstructured==0.6.5
pip set up pdf2image==1.16.3
pip set up pytesseract==0.3.10
pip set up pypdf==3.8.1
pip set up faiss-cpu==1.7.4
For LangChain you see that we specified additionally the model. This library is receiving a whole lot of updates lately, so to make certain the our setup goes to work additionally tomorrow it’s higher to specify a model we all know is working tremendous. Unstructured is a required dependency for the pdf loader and pytesseract and pdf2image as properly.
NOTE: on the GitHub repository there’s a necessities.txt file (urged by jl adcr) with all of the variations related to this mission. You are able to do the set up in a single shot, after downloading it into the principle mission file listing with the next command:
pip set up -r necessities.txt
On the finish of the article I created a section for the troubleshooting. The GitHub repo has additionally an up to date READ.ME with all these info.
Keep in mind that some libraries have variations accessible relying on the python model you might be operating in your digital surroundings.
Obtain in your PC the fashions
It is a actually vital step.
For the mission we actually want GPT4All. The method described on Nomic AI is basically difficult and requires {hardware} that not all of us have (like me). So here is the link to the model already transformed and prepared for use. Simply click on on obtain.
Obtain the GPT4All mannequin
As described briefly within the introduction we want additionally the mannequin for the embeddings, a mannequin that we will run on our CPU with out crushing. Click on the link here to download the alpaca-native-7B-ggml already transformed to 4-bit and able to use to behave as our mannequin for the embedding.
Click on the obtain arrow subsequent to ggml-model-q4_0.bin
Why we want embeddings? For those who keep in mind from the circulate diagram step one required, after we accumulate the paperwork for our information base, is to embed them. The LLamaCPP embeddings from this Alpaca mannequin match the job completely and this mannequin is sort of small too (4 Gb). By the way in which you may as well use the Alpaca mannequin in your QnA!
Replace 2023.05.25: Mani Home windows customers are going through issues to make use of the llamaCPP embeddings. This primarily occurs as a result of in the course of the set up of the python package deal llama-cpp-python with:
pip set up llama-cpp-python
the pip package deal goes to compile from supply the library. Home windows normally doesn’t have CMake or C compiler put in by default on the machine. However don’t warry there’s a answer
Working the set up of llama-cpp-python, required by LangChain with the llamaEmbeddings, on home windows CMake C complier shouldn’t be put in by default, so you can not construct from supply.
On Mac Customers with Xtools and on Linux, normally the C complier is already accessible on the OS.
To keep away from the problem you MUST use pre complied wheel.
Go right here https://github.com/abetlen/llama-cpp-python/releases
and search for the complied wheel in your structure and python model — you MUST take Weels Model 0.1.49 as a result of greater variations will not be appropriate.
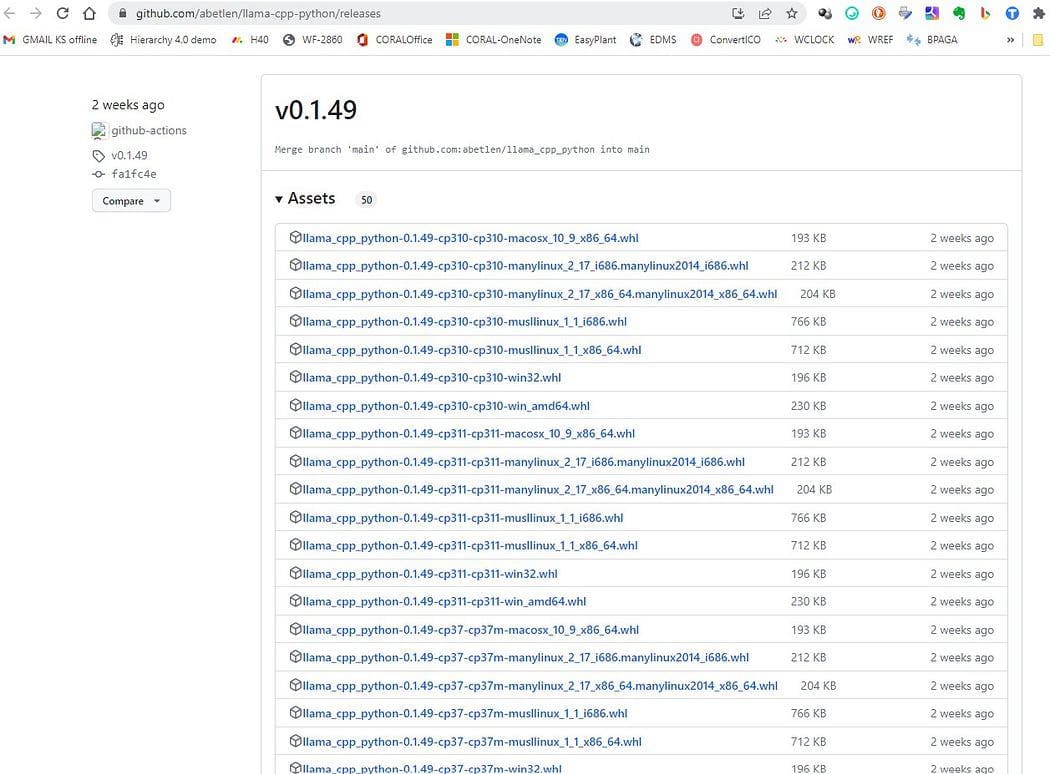
Screenshot from https://github.com/abetlen/llama-cpp-python/releases
In my case I’ve Home windows 10, 64 bit, python 3.10
so my file is llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
This issue is tracked on the GitHub repository
After downloading it’s worthwhile to put the 2 fashions within the fashions listing, as proven under.

Listing construction and the place to place the mannequin recordsdata
Since we need to have management of our interplay the the GPT mannequin, we have now to create a python file (let’s name it pygpt4all_test.py), import the dependencies and provides the instruction to the mannequin. You will notice that’s fairly simple.
from pygpt4all.fashions.gpt4all import GPT4All
That is the python binding for our mannequin. Now we will name it and begin asking. Let’s attempt a artistic one.
We create a perform that learn the callback from the mannequin, and we ask GPT4All to finish our sentence.
def new_text_callback(textual content):
print(textual content, finish="")
mannequin = GPT4All('./fashions/gpt4all-converted.bin')
mannequin.generate("As soon as upon a time, ", n_predict=55, new_text_callback=new_text_callback)
The primary assertion is telling our program the place to search out the mannequin (keep in mind what we did within the part above)
The second assertion is asking the mannequin to generate a response and to finish our immediate “As soon as upon a time,”.
To run it, ensure that the digital surroundings continues to be activated and easily run :
python3 pygpt4all_test.py
It is best to se a loading textual content of the mannequin and the completion of the sentence. Relying in your {hardware} assets it might take a while.
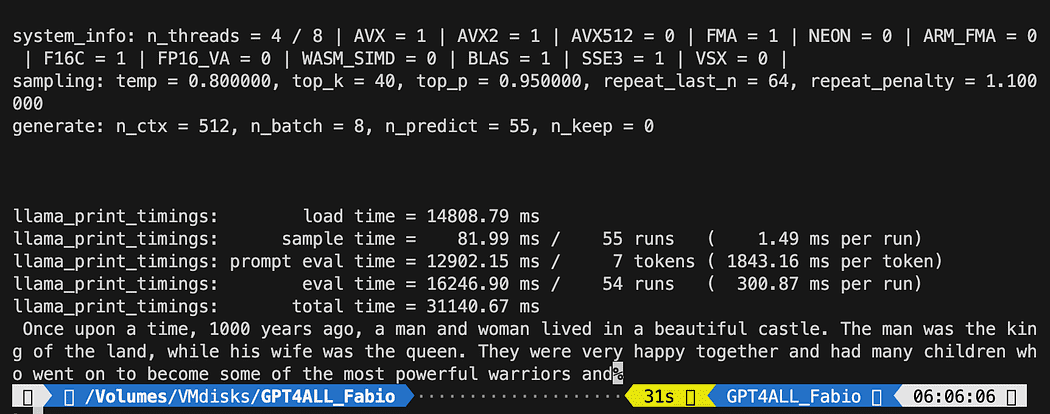
The consequence could also be completely different from yours… However for us the vital is that it’s working and we will proceed with LangChain to create some superior stuff.
NOTE (up to date 2023.05.23): when you face an error associated to pygpt4all, test the troubleshooting part on this subject with the answer given by Rajneesh Aggarwal or by Oscar Jeong.
LangChain framework is a very superb library. It offers Elements to work with language fashions in a simple to make use of approach, and it additionally offers Chains. Chains will be regarded as assembling these elements particularly methods so as to finest accomplish a selected use case. These are meant to be the next degree interface by which individuals can simply get began with a selected use case. These chains are additionally designed to be customizable.
In our subsequent python take a look at we are going to use a Immediate Template. Language fashions take textual content as enter — that textual content is often known as a immediate. Usually this isn’t merely a hardcoded string however fairly a mix of a template, some examples, and person enter. LangChain offers a number of lessons and features to make establishing and dealing with prompts simple. Let’s see how we will do it too.
Create a brand new python file and name it my_langchain.py
# Import of langchain Immediate Template and Chain
from langchain import PromptTemplate, LLMChain
# Import llm to have the ability to work together with GPT4All instantly from langchain
from langchain.llms import GPT4All
# Callbacks supervisor is required for the response dealing with
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
local_path="./fashions/gpt4all-converted.bin"
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
We imported from LangChain the Immediate Template and Chain and GPT4All llm class to have the ability to work together instantly with our GPT mannequin.
Then, after setting our llm path (as we did earlier than) we instantiate the callback managers in order that we’re in a position to catch the responses to our question.
To create a template is very easy: following the documentation tutorial we will use one thing like this…
template = """Query: {query}
Reply: Let's suppose step-by-step on it.
"""
immediate = PromptTemplate(template=template, input_variables=["question"])
The template variable is a multi-line string that comprises our interplay construction with the mannequin: in curly braces we insert the exterior variables to the template, in our state of affairs is our query.
Since it’s a variable you’ll be able to resolve whether it is an hard-coded query or an person enter query: right here the 2 examples.
# Hardcoded query
query = "What Components 1 pilot received the championship within the yr Leonardo di Caprio was born?"
# Consumer enter query...
query = enter("Enter your query: ")
For our take a look at run we are going to remark the person enter one. Now we solely have to hyperlink collectively our template, the query and the language mannequin.
template = """Query: {query}
Reply: Let's suppose step-by-step on it.
"""
immediate = PromptTemplate(template=template, input_variables=["question"])
# initialize the GPT4All occasion
llm = GPT4All(mannequin=local_path, callback_manager=callback_manager, verbose=True)
# hyperlink the language mannequin with our immediate template
llm_chain = LLMChain(immediate=immediate, llm=llm)
# Hardcoded query
query = "What Components 1 pilot received the championship within the yr Leonardo di Caprio was born?"
# Consumer imput query...
# query = enter("Enter your query: ")
#Run the question and get the outcomes
llm_chain.run(query)
Keep in mind to confirm your digital surroundings continues to be activated and run the command:
You might get a distinct outcomes from mine. What’s superb is that you would be able to see the complete reasoning adopted by GPT4All making an attempt to get a solution for you. Adjusting the query might offer you higher outcomes too.
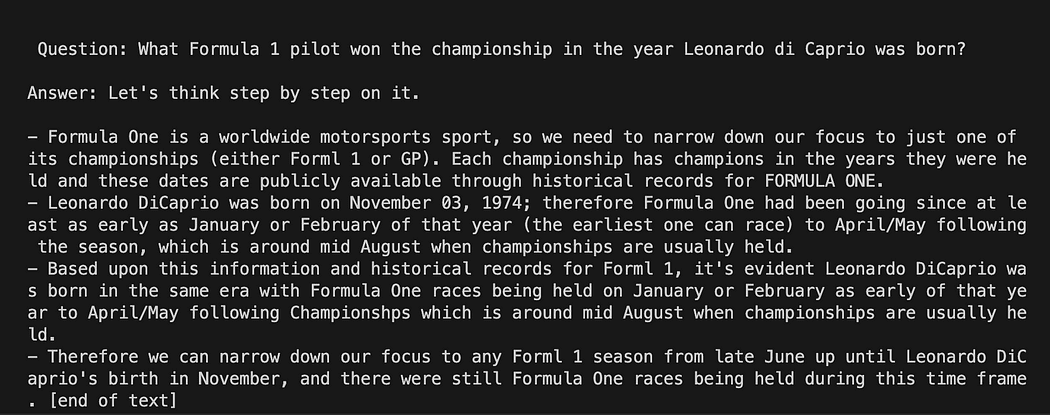
Langchain with Immediate Template on GPT4All
Right here we begin the superb half, as a result of we’re going to speak to our paperwork utilizing GPT4All as a chatbot who replies to our questions.
The sequence of steps, referring to Workflow of the QnA with GPT4All, is to load our pdf recordsdata, make them into chunks. After that we are going to want a Vector Retailer for our embeddings. We have to feed our chunked paperwork in a vector retailer for info retrieval after which we are going to embed them along with the similarity search on this database as a context for our LLM question.
For this functions we’re going to use FAISS instantly from Langchain library. FAISS is an open-source library from Fb AI Analysis, designed to rapidly discover comparable gadgets in massive collections of high-dimensional information. It provides indexing and looking strategies to make it simpler and sooner to identify probably the most comparable gadgets inside a dataset. It’s significantly handy for us as a result of it simplifies info retrieval and permit us to save lots of regionally the created database: because of this after the primary creation will probably be loaded very quick for any additional utilization.
Creation of the vector index db
Create a brand new file and name it my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# perform for loading solely TXT recordsdata
from langchain.document_loaders import TextLoader
# textual content splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to have the ability to load the pdf recordsdata
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Retailer Index to create our database about our information
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca mannequin
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the recordsdata
import datetime
The primary libraries are the identical we used earlier than: as well as we’re utilizing Langchain for the vector retailer index creation, the LlamaCppEmbeddings to work together with our Alpaca mannequin (quantized to 4-bit and compiled with the cpp library) and the PDF loader.
Let’s additionally load our LLMs with their very own paths: one for the embeddings and one for the textual content technology.
# assign the trail for the two fashions GPT4All and Alpaca for the embeddings
gpt4all_path="./fashions/gpt4all-converted.bin"
llama_path="./fashions/ggml-model-q4_0.bin"
# Calback supervisor for dealing with the calls with the mannequin
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(mannequin=gpt4all_path, callback_manager=callback_manager, verbose=True)
For take a look at let’s see if we managed to learn all of the pfd recordsdata: step one is to declare 3 features for use on every single doc. The primary is to separate the extracted textual content in chunks, the second is to create the vector index with the metadata (like web page numbers and so forth…) and the final one is for testing the similarity search (I’ll clarify higher later).
# Break up textual content
def split_chunks(sources):
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32)
for chunk in splitter.split_documents(sources):
chunks.append(chunk)
return chunks
def create_index(chunks):
texts = [doc.page_content for doc in chunks]
metadatas = [doc.metadata for doc in chunks]
search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
return search_index
def similarity_search(question, index):
# ok is the variety of similarity searched that matches the question
# default is 4
matched_docs = index.similarity_search(question, ok=3)
sources = []
for doc in matched_docs:
sources.append(
{
"page_content": doc.page_content,
"metadata": doc.metadata,
}
)
return matched_docs, sources
Now we will take a look at the index technology for the paperwork within the docs listing: we have to put there all our pdfs. Langchain has additionally a way for loading the complete folder, whatever the file sort: since it’s difficult the submit course of, I’ll cowl it within the subsequent article about LaMini fashions.

my docs listing comprises 4 pdf recordsdata
We are going to apply our features to the primary doc within the record
# get the record of pdf recordsdata from the docs listing into a listing format
pdf_folder_path="./docs"
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the trail
loader = PyPDFLoader(os.path.be part of(pdf_folder_path, doc_list[0]))
# load the paperwork with Langchain
docs = loader.load()
# Break up in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)
Within the first traces we use os library to get the record of pdf recordsdata contained in the docs listing. We then load the primary doc (doc_list[0]) from the docs folder with Langchain, cut up in chunks after which we create the vector database with the LLama embeddings.
As you noticed we’re utilizing the pyPDF method. This one is a bit longer to make use of, since it’s important to load the recordsdata one after the other, however loading PDF utilizing pypdf into array of paperwork means that you can have an array the place every doc comprises the web page content material and metadata with web page quantity. That is actually handy whenever you need to know the sources of the context we are going to give to GPT4All with our question. Right here the instance from the readthedocs:
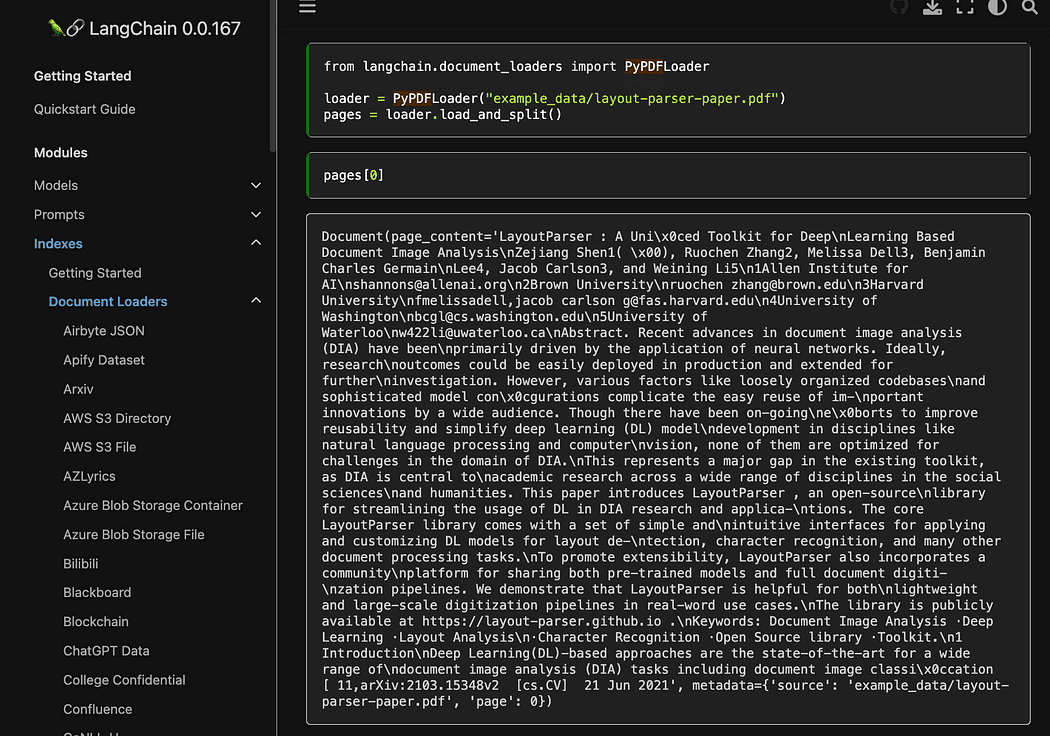
Screenshot from Langchain documentation
We are able to run the python file with the command from terminal:
python3 my_knowledge_qna.py
After the loading of the mannequin for embeddings you will notice the tokens at work for the indexing: don’t freak out since it can take time, specifically when you run solely on CPU, like me (it took 8 minutes).

Completion of the primary vector db
As I used to be explaining the pyPDF technique is slower however provides us further information for the similarity search. To iterate by all our recordsdata we are going to use a handy technique from FAISS that enables us to MERGE completely different databases collectively. What we do now could be that we use the code above to generate the primary db (we are going to name it db0) and the with a for loop we create the index of the following file within the record and merge it instantly with db0.
Right here is the code: notice that I added some logs to provide the standing of the progress utilizing datetime.datetime.now() and printing the delta of finish time and begin time to calculate how lengthy the operation took (you’ll be able to take away it when you don’t prefer it).
The merge directions is like this
# merge dbi with the present db0
db0.merge_from(dbi)
One of many final directions is for saving our database regionally: the complete technology can take even hours (relies on what number of paperwork you’ve gotten) so it’s actually good that we have now to do it solely as soon as!
# Save the databasae regionally
db0.save_local("my_faiss_index")
Right here the complete code. We are going to remark many a part of it once we work together with GPT4All loading the index instantly from our folder.
# get the record of pdf recordsdata from the docs listing into a listing format
pdf_folder_path="./docs"
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the trail
general_start = datetime.datetime.now() #not used now however helpful
print("beginning the loop...")
loop_start = datetime.datetime.now() #not used now however helpful
print("producing fist vector database after which iterate with .merge_from")
loader = PyPDFLoader(os.path.be part of(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Major Vector database created. Begin iteration and merging...")
for i in vary(1,num_of_docs):
print(doc_list[i])
print(f"loop place {i}")
loader = PyPDFLoader(os.path.be part of(pdf_folder_path, doc_list[i]))
begin = datetime.datetime.now() #not used now however helpful
docs = loader.load()
chunks = split_chunks(docs)
dbi = create_index(chunks)
print("begin merging with db0...")
db0.merge_from(dbi)
finish = datetime.datetime.now() #not used now however helpful
elapsed = finish - begin #not used now however helpful
#whole time
print(f"accomplished in {elapsed}")
print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now however helpful
loop_elapsed = loop_end - loop_start #not used now however helpful
print(f"All paperwork processed in {loop_elapsed}")
print(f"the daatabase is completed with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging accomplished")
print("-----------------------------------")
print("Saving Merged Database Domestically")
# Save the databasae regionally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now however helpful
general_elapsed = general_end - general_start #not used now however helpful
print(f"All indexing accomplished in {general_elapsed}")
print("-----------------------------------")
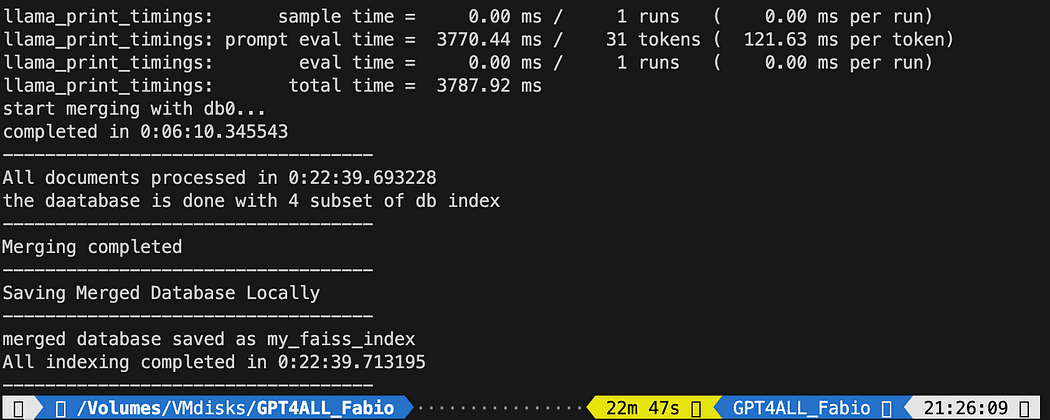 Working the python file took 22 minutes
Working the python file took 22 minutesAsk inquiries to GPT4All in your paperwork
Now we’re right here. We’ve our index, we will load it and with a Immediate Template we will ask GPT4All to reply our questions. We begin with an hard-coded query after which we are going to loop by our enter questions.
Put the next code inside a python file db_loading.py and run it with the command from terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# perform for loading solely TXT recordsdata
from langchain.document_loaders import TextLoader
# textual content splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to have the ability to load the pdf recordsdata
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Retailer Index to create our database about our information
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca mannequin
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the recordsdata
import datetime
# TEST FOR SIMILARITY SEARCH
# assign the trail for the two fashions GPT4All and Alpaca for the embeddings
gpt4all_path="./fashions/gpt4all-converted.bin"
llama_path="./fashions/ggml-model-q4_0.bin"
# Calback supervisor for dealing with the calls with the mannequin
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(mannequin=gpt4all_path, callback_manager=callback_manager, verbose=True)
# Break up textual content
def split_chunks(sources):
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32)
for chunk in splitter.split_documents(sources):
chunks.append(chunk)
return chunks
def create_index(chunks):
texts = [doc.page_content for doc in chunks]
metadatas = [doc.metadata for doc in chunks]
search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
return search_index
def similarity_search(question, index):
# ok is the variety of similarity searched that matches the question
# default is 4
matched_docs = index.similarity_search(question, ok=3)
sources = []
for doc in matched_docs:
sources.append(
{
"page_content": doc.page_content,
"metadata": doc.metadata,
}
)
return matched_docs, sources
# Load our native index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded query
question = "What's a PLC and what's the distinction with a PC"
docs = index.similarity_search(question)
# Get the matches finest 3 outcomes - outlined within the perform ok=3
print(f"The query is: {question}")
print("Right here the results of the semantic search on the index, with out GPT4All..")
print(docs[0])
The printed textual content is the record of the three sources that finest matches with the question, giving us additionally the doc title and the web page quantity.
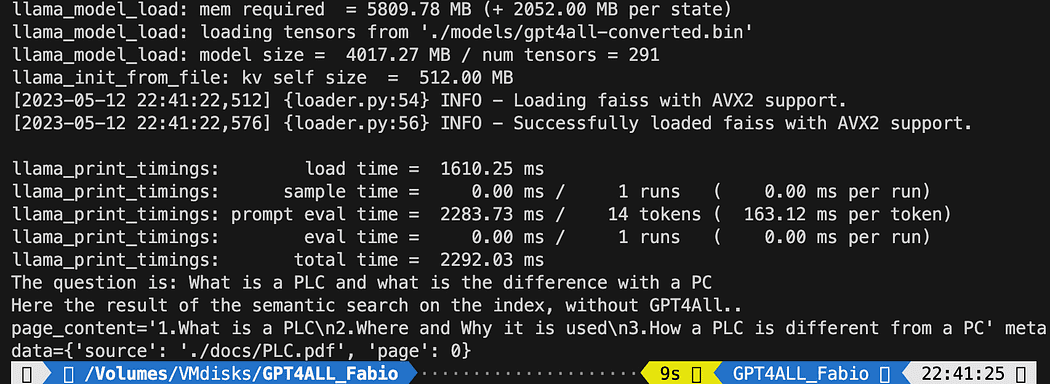
Outcomes of the semantic search operating the file db_loading.py
Now we will use the similarity search because the context for our question utilizing the immediate template. After the three features simply change all of the code with the next:
# Load our native index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# create the immediate template
template = """
Please use the next context to reply questions.
Context: {context}
---
Query: {query}
Reply: Let's suppose step-by-step."""
# Hardcoded query
query = "What's a PLC and what's the distinction with a PC"
matched_docs, sources = similarity_search(query, index)
# Creating the context
context = "n".be part of([doc.page_content for doc in matched_docs])
# instantiating the immediate template and the GPT4All chain
immediate = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(immediate=immediate, llm=llm)
# Print the consequence
print(llm_chain.run(query))
After operating you’re going to get a consequence like this (however might differ). Wonderful no!?!?
Please use the next context to reply questions.
Context: 1.What's a PLC
2.The place and Why it's used
3.How a PLC is completely different from a PC
PLC is particularly vital in industries the place security and reliability are
important, akin to manufacturing crops, chemical crops, and energy crops.
How a PLC is completely different from a PC
As a result of a PLC is a specialised laptop utilized in industrial and
manufacturing functions to manage equipment and processes.,the
{hardware} elements of a typical PLC should be capable of work together with
industrial gadget. So a typical PLC {hardware} embrace:
---
Query: What's a PLC and what's the distinction with a PC
Reply: Let's suppose step-by-step. 1) A Programmable Logic Controller (PLC),
additionally referred to as Industrial Management System or ICS, refers to an industrial laptop
that controls numerous automated processes akin to manufacturing
machines/meeting traces etcetera by sensors and actuators linked
with it through inputs & outputs. It's a type of digital computer systems which has
the flexibility for a number of instruction execution (MIE), built-in reminiscence
registers utilized by software program routines, Enter Output interface playing cards(IOC)
to speak with different units electronically/digitally over networks
or buses etcetera
2). A Programmable Logic Controller is broadly utilized in industrial
automation because it has the flexibility for multiple instruction execution.
It could actually carry out duties robotically and programmed directions, which permits
it to hold out complicated operations which can be past a
Private Laptop (PC) capability. So an ICS/PLC comprises built-in reminiscence
registers utilized by software program routines or firmware codes etcetera however
PC does not include them in order that they want exterior interfaces akin to
exhausting disks drives(HDD), USB ports, serial and parallel
communication protocols to retailer information for additional evaluation or
report technology.
If you need a user-input query to exchange the road
query = "What's a PLC and what's the distinction with a PC"
with one thing like this:
query = enter("Your query: ")
It’s time so that you can experiment. Ask completely different questions on all of the matters associated to your paperwork, and see the outcomes. There’s a massive room for enchancment, actually on the immediate and template: you’ll be able to take a look here for some inspirations. However Langchain documentation is basically superb (I may comply with it!!).
You possibly can comply with the code from the article or test it on my github repo.
Fabio Matricardi an educator, instructor, engineer and studying fanatic. He have been instructing for 15 years to younger college students, and now he prepare new staff at Key Answer Srl. He began my profession as Industrial Automation Engineer in 2010. Captivated with programming since he was a young person, he found the fantastic thing about constructing software program and Human Machine Interfaces to carry one thing to life. Instructing and training is a part of my day by day routine, in addition to finding out and studying find out how to be a passionate chief with updated administration expertise. Be part of me within the journey towards a greater design, a predictive system integration utilizing Machine Studying and Synthetic Intelligence all through the complete engineering lifecycle.
Original. Reposted with permission.





