Speed up PyTorch with DeepSpeed to coach massive language fashions with Intel Habana Gaudi-based DL1 EC2 situations

Coaching massive language fashions (LLMs) with billions of parameters might be difficult. Along with designing the mannequin structure, researchers have to arrange state-of-the-art coaching methods for distributed coaching like combined precision help, gradient accumulation, and checkpointing. With massive fashions, the coaching setup is much more difficult as a result of the out there reminiscence in a single accelerator machine bounds the scale of fashions educated utilizing solely knowledge parallelism, and utilizing mannequin parallel coaching requires extra stage of modifications to the coaching code. Libraries similar to DeepSpeed (an open-source deep studying optimization library for PyTorch) deal with a few of these challenges, and will help speed up mannequin growth and coaching.
On this publish, we arrange coaching on the Intel Habana Gaudi-based Amazon Elastic Compute Cloud (Amazon EC2) DL1 situations and quantify the advantages of utilizing a scaling framework similar to DeepSpeed. We current scaling outcomes for an encoder-type transformer mannequin (BERT with 340 million to 1.5 billion parameters). For the 1.5-billion-parameter mannequin, we achieved a scaling effectivity of 82.7% throughout 128 accelerators (16 dl1.24xlarge situations) utilizing DeepSpeed ZeRO stage 1 optimizations. The optimizer states have been partitioned by DeepSpeed to coach massive fashions utilizing the information parallel paradigm. This method has been prolonged to coach a 5-billion-parameter mannequin utilizing knowledge parallelism. We additionally used Gaudi’s native help of the BF16 knowledge kind for diminished reminiscence dimension and elevated coaching efficiency in comparison with utilizing the FP32 knowledge kind. In consequence, we achieved pre-training (section 1) mannequin convergence inside 16 hours (our goal was to coach a big mannequin inside a day) for the BERT 1.5-billion-parameter mannequin utilizing the wikicorpus-en dataset.
Coaching setup
We provisioned a managed compute cluster comprised of 16 dl1.24xlarge situations utilizing AWS Batch. We developed an AWS Batch workshop that illustrates the steps to arrange the distributed coaching cluster with AWS Batch. Every dl1.24xlarge occasion has eight Habana Gaudi accelerators, every with 32 GB of reminiscence and a full mesh RoCE community between playing cards with a complete bi-directional interconnect bandwidth of 700 Gbps every (see Amazon EC2 DL1 instances Deep Dive for extra info). The dl1.24xlarge cluster additionally used 4 AWS Elastic Fabric Adapters (EFA), with a complete of 400 Gbps interconnect between nodes.
The distributed coaching workshop illustrates the steps to arrange the distributed coaching cluster. The workshop reveals the distributed coaching setup utilizing AWS Batch and particularly, the multi-node parallel jobs characteristic to launch large-scale containerized coaching jobs on absolutely managed clusters. Extra particularly, a totally managed AWS Batch compute atmosphere is created with DL1 situations. The containers are pulled from Amazon Elastic Container Registry (Amazon ECR) and launched robotically into the situations within the cluster based mostly on the multi-node parallel job definition. The workshop concludes by operating a multi-node, multi-HPU knowledge parallel coaching of a BERT (340 million to 1.5 billion parameters) mannequin utilizing PyTorch and DeepSpeed.
BERT 1.5B pre-training with DeepSpeed
Habana SynapseAI v1.5 and v1.6 help DeepSpeed ZeRO1 optimizations. The Habana fork of the DeepSpeed GitHub repository contains the modifications essential to help the Gaudi accelerators. There’s full help of distributed knowledge parallel (multi-card, multi-instance), ZeRO1 optimizations, and BF16 knowledge varieties.
All these options are enabled on the BERT 1.5B model reference repository, which introduces a 48-layer, 1600-hidden dimension, and 25-head bi-directional encoder mannequin, derived from a BERT implementation. The repository additionally incorporates the baseline BERT Giant mannequin implementation: a 24-layer, 1024-hidden, 16-head, 340-million-parameter neural community structure. The pre-training modeling scripts are derived from the NVIDIA Deep Learning Examples repository to obtain the wikicorpus_en knowledge, preprocess the uncooked knowledge into tokens, and shard the information into smaller h5 datasets for distributed knowledge parallel coaching. You may undertake this generic method to coach your customized PyTorch mannequin architectures utilizing your datasets utilizing DL1 situations.
Pre-training (section 1) scaling outcomes
For pre-training massive fashions at scale, we primarily centered on two elements of the answer: coaching efficiency, as measured by the point to coach, and cost-effectiveness of arriving at a totally converged answer. Subsequent, we dive deeper into these two metrics with BERT 1.5B pre-training for example.
Scaling efficiency and time to coach
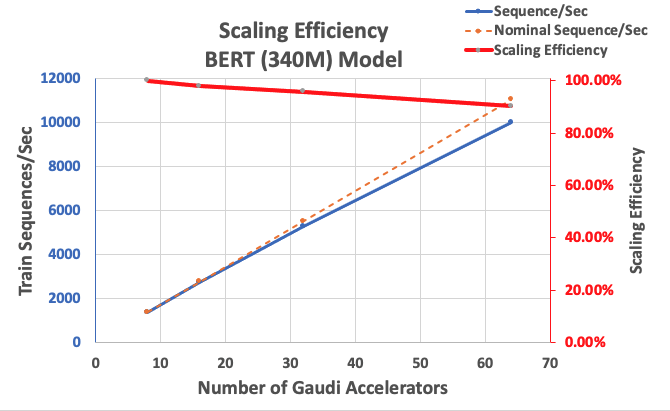
We begin by measuring the efficiency of the BERT Giant implementation as a baseline for scalability. The next desk lists the measured throughput of sequences per second from 1-8 dl1.24xlarge situations (with eight accelerator units per occasion). Utilizing the single-instance throughput as baseline, we measured the effectivity of scaling throughout a number of situations, which is a crucial lever to grasp the price-performance coaching metric.
| Variety of Cases | Variety of Accelerators | Sequences per Second | Sequences per Second per Accelerator | Scaling Effectivity |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
The next determine illustrates the scaling effectivity.
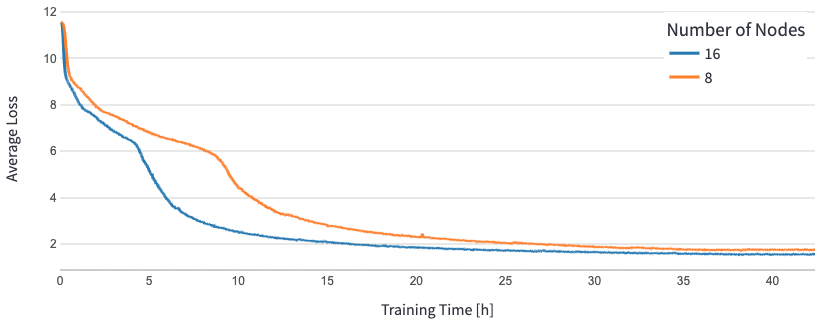
For BERT 1.5B, we modified the hyperparameters for the mannequin within the reference repository to ensure convergence. The efficient batch dimension per accelerator was set to 384 (for max reminiscence utilization), with micro-batches of 16 per step and 24 steps of gradient accumulation. Studying charges of 0.0015 and 0.003 have been used for 8 and 16 nodes, respectively. With these configurations, we achieved convergence of the section 1 pre-training of BERT 1.5B throughout 8 dl1.24xlarge situations (64 accelerators) in roughly 25 hours, and 15 hours throughout 16 dl1.24xlarge situations (128 accelerators). The next determine reveals the typical loss as a operate of variety of coaching epochs, as we scale up the variety of accelerators.
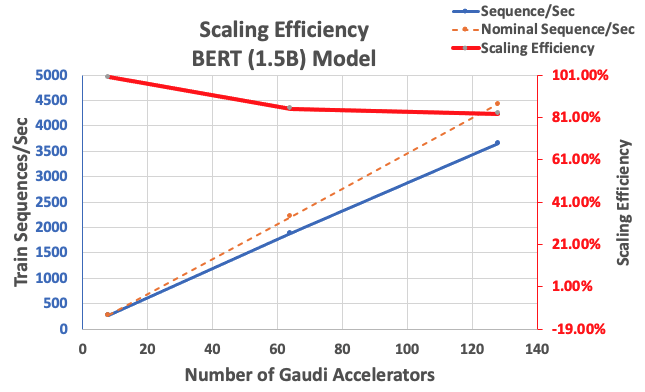
With the configuration described earlier, we obtained 85% robust scaling effectivity with 64 accelerators and 83% with 128 accelerators, from a baseline of 8 accelerators in a single occasion. The next desk summarizes the parameters.
| Variety of Cases | Variety of Accelerators | Sequences per Second | Sequences per Second per Accelerator | Scaling Effectivity |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
The next determine illustrates the scaling effectivity.
Conclusion
On this publish, we evaluated help for DeepSpeed by Habana SynapseAI v1.5/v1.6 and the way it helps scale LLM coaching on Habana Gaudi accelerators. Pre-training of a 1.5-billion-parameter BERT mannequin took 16 hours to converge on a cluster of 128 Gaudi accelerators, with 85% robust scaling. We encourage you to try the structure demonstrated within the AWS workshop and think about adopting it to coach customized PyTorch mannequin architectures utilizing DL1 situations.
In regards to the authors
 Mahadevan Balasubramaniam is a Principal Options Architect for Autonomous Computing with almost 20 years of expertise within the space of physics-infused deep studying, constructing, and deploying digital twins for industrial techniques at scale. Mahadevan obtained his PhD in Mechanical Engineering from the Massachusetts Institute of Know-how and has over 25 patents and publications to his credit score.
Mahadevan Balasubramaniam is a Principal Options Architect for Autonomous Computing with almost 20 years of expertise within the space of physics-infused deep studying, constructing, and deploying digital twins for industrial techniques at scale. Mahadevan obtained his PhD in Mechanical Engineering from the Massachusetts Institute of Know-how and has over 25 patents and publications to his credit score.
 RJ is an engineer in Search M5 group main the efforts for constructing massive scale deep studying techniques for coaching and inference. Outdoors of labor he explores totally different cuisines of meals and performs racquet sports activities.
RJ is an engineer in Search M5 group main the efforts for constructing massive scale deep studying techniques for coaching and inference. Outdoors of labor he explores totally different cuisines of meals and performs racquet sports activities.
 Sundar Ranganathan is the Head of Enterprise Improvement, ML Frameworks on the Amazon EC2 group. He focuses on large-scale ML workloads throughout AWS companies like Amazon EKS, Amazon ECS, Elastic Material Adapter, AWS Batch, and Amazon SageMaker. His expertise contains management roles in product administration and product growth at NetApp, Micron Know-how, Qualcomm, and Mentor Graphics.
Sundar Ranganathan is the Head of Enterprise Improvement, ML Frameworks on the Amazon EC2 group. He focuses on large-scale ML workloads throughout AWS companies like Amazon EKS, Amazon ECS, Elastic Material Adapter, AWS Batch, and Amazon SageMaker. His expertise contains management roles in product administration and product growth at NetApp, Micron Know-how, Qualcomm, and Mentor Graphics.
 Abhinandan Patni is a Senior Software program Engineer at Amazon Search. He focuses on constructing techniques and tooling for scalable distributed deep studying coaching and actual time inference.
Abhinandan Patni is a Senior Software program Engineer at Amazon Search. He focuses on constructing techniques and tooling for scalable distributed deep studying coaching and actual time inference.
 Pierre-Yves Aquilanti is Head of Frameworks ML Options at Amazon Net Companies the place he helps develop the trade’s greatest cloud based mostly ML Frameworks options. His background is in Excessive Efficiency Computing and previous to becoming a member of AWS, Pierre-Yves was working within the Oil & Gasoline trade. Pierre-Yves is initially from France and holds a Ph.D. in Pc Science from the College of Lille.
Pierre-Yves Aquilanti is Head of Frameworks ML Options at Amazon Net Companies the place he helps develop the trade’s greatest cloud based mostly ML Frameworks options. His background is in Excessive Efficiency Computing and previous to becoming a member of AWS, Pierre-Yves was working within the Oil & Gasoline trade. Pierre-Yves is initially from France and holds a Ph.D. in Pc Science from the College of Lille.





