Analyze Amazon SageMaker spend and decide price optimization alternatives based mostly on utilization, Half 3: Processing and Knowledge Wrangler jobs

In 2021, we launched AWS Support Proactive Services as a part of the AWS Enterprise Support plan. Since its introduction, we’ve helped a whole lot of consumers optimize their workloads, set guardrails, and enhance the visibility of their machine studying (ML) workloads’ price and utilization.
On this sequence of posts, we share classes realized about optimizing prices in Amazon SageMaker. On this put up, we give attention to information preprocessing utilizing Amazon SageMaker Processing and Amazon SageMaker Data Wrangler jobs.
Knowledge preprocessing holds a pivotal function in a data-centric AI method. Nevertheless, getting ready uncooked information for ML coaching and analysis is usually a tedious and demanding job by way of compute assets, time, and human effort. Knowledge preparation generally must be built-in from completely different sources and take care of lacking or noisy values, outliers, and so forth.
Moreover, along with frequent extract, rework, and cargo (ETL) duties, ML groups sometimes require extra superior capabilities like creating fast fashions to guage information and produce characteristic significance scores or post-training mannequin analysis as a part of an MLOps pipeline.
SageMaker presents two options particularly designed to assist with these points: SageMaker Processing and Knowledge Wrangler. SageMaker Processing lets you simply run preprocessing, postprocessing, and mannequin analysis on a totally managed infrastructure. Knowledge Wrangler reduces the time it takes to combination and put together information by simplifying the method of information supply integration and have engineering utilizing a single visible interface and a totally distributed information processing surroundings.
Each SageMaker options present nice flexibility with a number of choices for I/O, storage, and computation. Nevertheless, setting these choices incorrectly could result in pointless price, particularly when coping with massive datasets.
On this put up, we analyze the pricing components and supply price optimization steering for SageMaker Processing and Knowledge Wrangler jobs.
SageMaker Processing
SageMaker Processing is a managed answer to run information processing and mannequin analysis workloads. You need to use it in information processing steps akin to characteristic engineering, information validation, mannequin analysis, and mannequin interpretation in ML workflows. With SageMaker Processing, you’ll be able to carry your personal customized processing scripts and select to construct a customized container or use a SageMaker managed container with frequent frameworks like scikit-learn, Lime, Spark and extra.
SageMaker Processing expenses you for the occasion sort you select, based mostly on the period of use and provisioned storage that’s hooked up to that occasion. In Half 1, we confirmed learn how to get began utilizing AWS Cost Explorer to determine price optimization alternatives in SageMaker.
You possibly can filter processing prices by making use of a filter on the utilization sort. The names of those utilization sorts are as follows:
REGION-Processing:instanceType(for instance,USE1-Processing:ml.m5.massive)REGION-Processing:VolumeUsage.gp2(for instance,USE1-Processing:VolumeUsage.gp2)
To assessment your SageMaker Processing price in Value Explorer, begin by filtering with SageMaker for Service, and for Utilization sort, you’ll be able to choose all processing cases operating hours by coming into the processing:ml prefix and choosing the listing on the menu.

Keep away from price in processing and pipeline growth
Earlier than right-sizing and optimizing a SageMaker Processing job’s run period, we test for high-level metrics about historic job runs. You possibly can select from two strategies to do that.
First, you’ll be able to entry the Processing web page on the SageMaker console.

Alternatively, you should utilize the list_processing_jobs API.

A Processing job standing might be InProgress, Accomplished, Failed, Stopping, or Stopped.
A excessive variety of failed jobs is frequent when creating new MLOps pipelines. Nevertheless, it is best to at all times take a look at and make each effort to validate jobs earlier than launching them on SageMaker as a result of there are expenses for assets used. For that function, you should utilize SageMaker Processing in local mode. Native mode is a SageMaker SDK characteristic that means that you can create estimators, processors, and pipelines, and deploy them to your native growth surroundings. It is a nice option to take a look at your scripts earlier than operating them in a SageMaker managed surroundings. Native mode is supported by SageMaker managed containers and those you provide your self. To be taught extra about learn how to use native mode with Amazon SageMaker Pipelines, consult with Local Mode.
Optimize I/O-related price
SageMaker Processing jobs provide entry to 3 information sources as a part of the managed processing input: Amazon Simple Storage Service (Amazon S3), Amazon Athena, and Amazon Redshift. For extra info, consult with ProcessingS3Input, AthenaDatasetDefinition, and RedshiftDatasetDefinition, respectively.
Earlier than wanting into optimization, it’s necessary to notice that though SageMaker Processing jobs help these information sources, they aren’t necessary. In your processing code, you’ll be able to implement any technique for downloading the accessing information from any supply (supplied that the processing occasion can entry it).
To realize higher insights into processing efficiency and detecting optimization alternatives, we suggest following logging best practices in your processing script. SageMaker publishes your processing logs to Amazon CloudWatch.
Within the following instance job log, we see that the script processing took quarter-hour (between Begin customized script and Finish customized script).
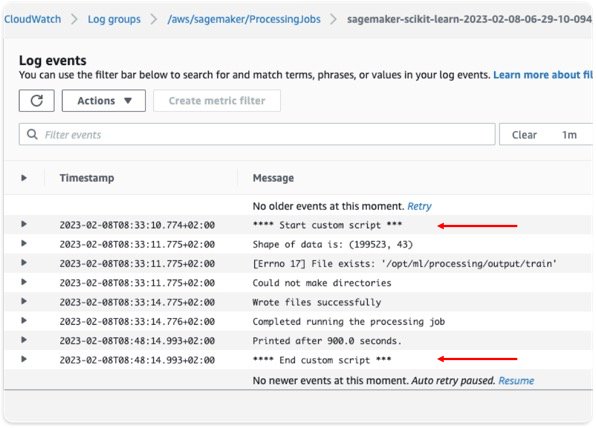
Nevertheless, on the SageMaker console, we see that the job took 4 further minutes (virtually 25% of the job’s complete runtime).
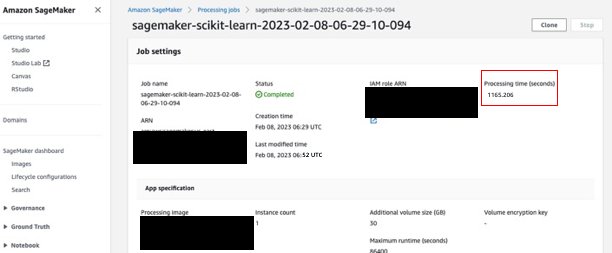
This is because of the truth that along with the time our processing script took, SageMaker-managed information downloading and importing additionally took time (4 minutes). If this proves to be an enormous a part of the fee, take into account alternate methods to hurry up downloading time, akin to utilizing the Boto3 API with multiprocessing to obtain recordsdata concurrently, or utilizing third-party libraries as WebDataset or s5cmd for sooner obtain from Amazon S3. For extra info, consult with Parallelizing S3 Workloads with s5cmd. Be aware that such strategies may introduce expenses in Amazon S3 because of data transfer.
Processing jobs additionally help Pipe mode. With this technique, SageMaker streams enter information from the supply on to your processing container into named pipes with out utilizing the ML storage quantity, thereby eliminating the info obtain time and a smaller disk quantity. Nevertheless, this requires a extra sophisticated programming mannequin than merely studying from recordsdata on a disk.
As talked about earlier, SageMaker Processing additionally helps Athena and Amazon Redshift as information sources. When establishing a Processing job with these sources, SageMaker routinely copies the info to Amazon S3, and the processing occasion fetches the info from the Amazon S3 location. Nevertheless, when the job is completed, there isn’t a managed cleanup course of and the info copied will nonetheless stay in Amazon S3 and may incur undesirable storage expenses. Subsequently, when utilizing Athena and Amazon Redshift information sources, be certain that to implement a cleanup process, akin to a Lambda operate that runs on a schedule or in a Lambda Step as a part of a SageMaker pipeline.
Like downloading, importing processing artifacts can be a possibility for optimization. When a Processing job’s output is configured utilizing the ProcessingS3Output parameter, you’ll be able to specify which S3UploadMode to make use of. The S3UploadMode parameter default worth is EndOfJob, which can get SageMaker to add the outcomes after the job completes. Nevertheless, in case your Processing job produces a number of recordsdata, you’ll be able to set S3UploadMode to Steady, thereby enabling the add of artifacts concurrently as processing continues, and reducing the job runtime.
Proper-size processing job cases
Choosing the proper occasion sort and measurement is a significant component in optimizing the price of SageMaker Processing jobs. You possibly can right-size an occasion by migrating to a distinct model inside the similar occasion household or by migrating to a different occasion household. When migrating inside the similar occasion household, you solely want to think about CPU/GPU and reminiscence. For extra info and normal steering on selecting the best processing assets, consult with Ensure efficient compute resources on Amazon SageMaker.
To fine-tune occasion choice, we begin by analyzing Processing job metrics in CloudWatch. For extra info, consult with Monitor Amazon SageMaker with Amazon CloudWatch.
CloudWatch collects uncooked information from SageMaker and processes it into readable, near-real-time metrics. Though these statistics are stored for 15 months, the CloudWatch console limits the search to metrics that had been up to date within the final 2 weeks (this ensures that solely present jobs are proven). Processing jobs metrics might be discovered within the /aws/sagemaker/ProcessingJobs namespace and the metrics collected are CPUUtilization, MemoryUtilization, GPUUtilization, GPUMemoryUtilization, and DiskUtilization.
The next screenshot exhibits an instance in CloudWatch of the Processing job we noticed earlier.
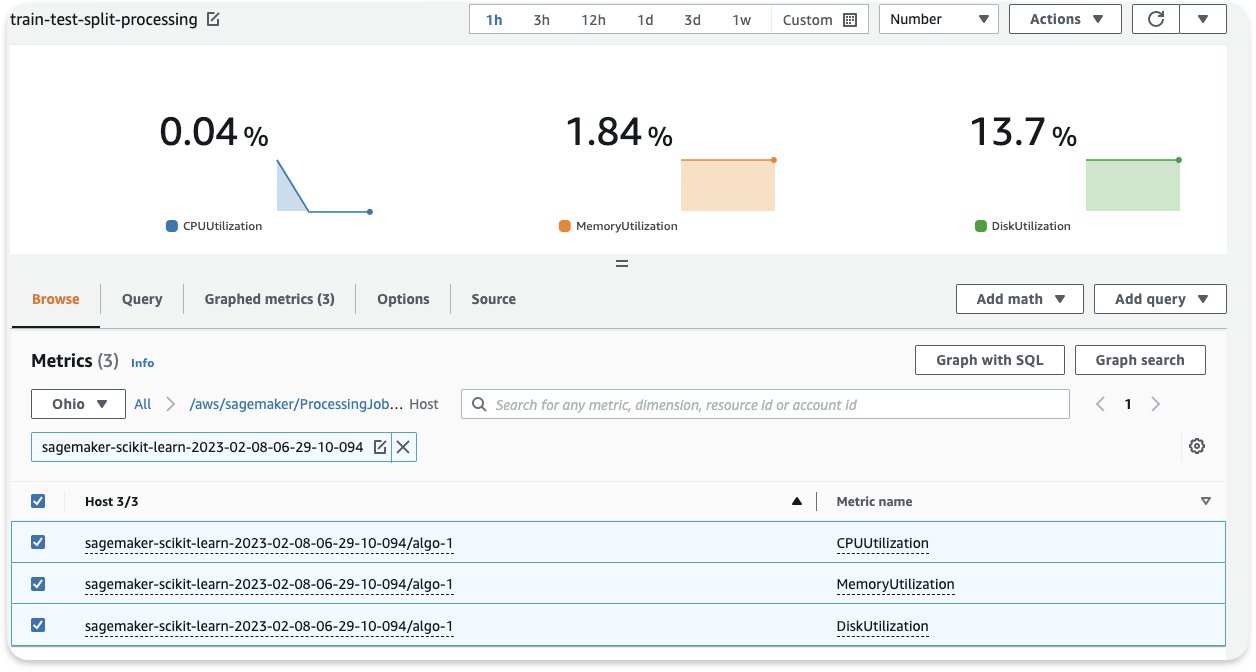
On this instance, we see the averaged CPU and reminiscence values (which is the default in CloudWatch): the common CPU utilization is 0.04%, reminiscence 1.84%, and disk utilization 13.7%. In an effort to right-size, at all times take into account the utmost CPU and reminiscence utilization (on this instance, the utmost CPU utilization was 98% within the first 3 minutes). As a normal rule, in case your most CPU and reminiscence utilization is constantly lower than 40%, you’ll be able to safely minimize the machine in half. For instance, in the event you had been utilizing an ml.c5.4xlarge occasion, you may transfer to an ml.c5.2xlarge, which might scale back your price by 50%.
Knowledge Wrangler jobs
Knowledge Wrangler is a characteristic of Amazon SageMaker Studio that gives a repeatable and scalable answer for information exploration and processing. You utilize the Knowledge Wrangler interface to interactively import, analyze, rework, and featurize your information. These steps are captured in a recipe (a .move file) which you can then use in a Knowledge Wrangler job. This helps you reapply the identical information transformations in your information and likewise scale to a distributed batch information processing job, both as a part of an ML pipeline or independently.
For steering on optimizing your Knowledge Wrangler app in Studio, consult with Half 2 on this sequence.
On this part, we give attention to optimizing Knowledge Wrangler jobs.
Knowledge Wrangler makes use of SageMaker Spark processing jobs with a Knowledge Wrangler-managed container. This container runs the instructions from the .move file within the job. Like all processing jobs, Knowledge Wrangler expenses you for the cases you select, based mostly on the period of use and provisioned storage that’s hooked up to that occasion.
In Value Explorer, you’ll be able to filter Knowledge Wrangler jobs prices by making use of a filter on the utilization sort. The names of those utilization sorts are:
REGION-processing_DW:instanceType(for instance,USE1-processing_DW:ml.m5.massive)REGION-processing_DW:VolumeUsage.gp2(for instance,USE1-processing_DW:VolumeUsage.gp2)
To view your Knowledge Wrangler price in Value Explorer, filter the service to make use of SageMaker, and for Utilization sort, select the processing_DW prefix and choose the listing on the menu. It will present you each occasion utilization (hours) and storage quantity (GB) associated prices. (If you wish to see Studio Knowledge Wrangler prices you’ll be able to filter the utilization sort by the Studio_DW prefix.)

Proper-size and schedule Knowledge Wrangler job cases
In the mean time, Knowledge Wrangler helps solely m5 cases with following occasion sizes: ml.m5.4xlarge, ml.m5.12xlarge, and ml.m5.24xlarge. You need to use the distributed job characteristic to fine-tune your job price. For instance, suppose it’s essential to course of a dataset that requires 350 GiB in RAM. The 4xlarge (128 GiB) and 12xlarge (256 GiB) may not be capable of course of and can lead you to make use of the m5.24xlarge occasion (768 GiB). Nevertheless, you may use two m5.12xlarge cases (2 * 256 GiB = 512 GiB) and scale back the fee by 40% or three m5.4xlarge cases (3 * 128 GiB = 384 GiB) and save 50% of the m5.24xlarge occasion price. It’s best to word that these are estimates and that distributed processing may introduce some overhead that may have an effect on the general runtime.
When altering the occasion sort, be sure you replace the Spark config accordingly. For instance, when you’ve got an preliminary ml.m5.4xlarge occasion job configured with properties spark.driver.reminiscence set to 2048 and spark.executor.reminiscence set to 55742, and later scale as much as ml.m5.12xlarge, these configuration values should be elevated, in any other case they would be the bottleneck within the processing job. You possibly can replace these variables within the Knowledge Wrangler GUI or in a configuration file appended to the config path (see the next examples).
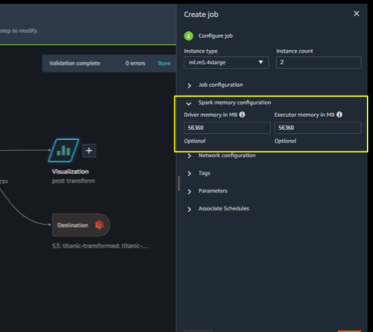
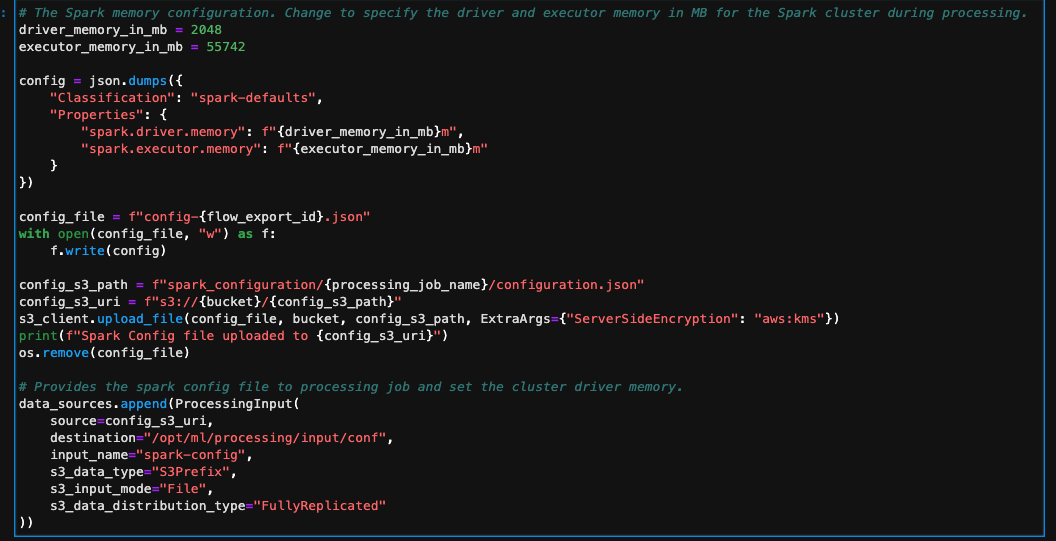
One other compelling characteristic in Knowledge Wrangler is the flexibility to set a scheduled job. In the event you’re processing information periodically, you’ll be able to create a schedule to run the processing job routinely. For instance, you’ll be able to create a schedule that runs a processing job routinely once you get new information (for examples, see Export to Amazon S3 or Export to Amazon SageMaker Feature Store). Nevertheless, it is best to word that once you create a schedule, Knowledge Wrangler creates an eventRule in EventBridge. This implies you even be charged for the occasion guidelines that you just create (in addition to the cases used to run the processing job). For extra info, see Amazon EventBridge pricing.
Conclusion
On this put up, we supplied steering on price evaluation and greatest practices when preprocessing
information utilizing SageMaker Processing and Knowledge Wrangler jobs. Much like preprocessing, there are lots of choices and configuration settings in constructing, coaching, and operating ML fashions which will result in pointless prices. Subsequently, as machine studying establishes itself as a robust software throughout industries, ML workloads wants to stay cost-effective.
SageMaker presents a large and deep characteristic set for facilitating every step within the ML pipeline.
This robustness additionally offers steady price optimization alternatives with out compromising efficiency or agility.
Concerning the Authors
 Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise prospects offering technical steering with greatest practices for deploying and sustaining AI/ML options within the AWS ecosystem. She has labored with a variety of organizations on varied deep studying use instances involving NLP and pc imaginative and prescient. She is captivated with empowering organizations to leverage generative AI to boost their use expertise. In her spare time, she enjoys motion pictures, music, and literature.
Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise prospects offering technical steering with greatest practices for deploying and sustaining AI/ML options within the AWS ecosystem. She has labored with a variety of organizations on varied deep studying use instances involving NLP and pc imaginative and prescient. She is captivated with empowering organizations to leverage generative AI to boost their use expertise. In her spare time, she enjoys motion pictures, music, and literature.
 Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Based mostly out of Israel, Uri works to empower enterprise prospects on all issues ML to design, construct, and function at scale. In his spare time, he enjoys biking, mountaineering, and watching sunsets (at minimal as soon as a day).
Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Based mostly out of Israel, Uri works to empower enterprise prospects on all issues ML to design, construct, and function at scale. In his spare time, he enjoys biking, mountaineering, and watching sunsets (at minimal as soon as a day).





