Analyze Amazon SageMaker spend and decide value optimization alternatives primarily based on utilization, Half 5: Internet hosting

In 2021, we launched AWS Support Proactive Services as a part of the AWS Enterprise Support plan. Since its introduction, we’ve helped tons of of consumers optimize their workloads, set guardrails, and enhance visibility of their machine studying (ML) workloads’ value and utilization.
On this collection of posts, we share classes realized about optimizing prices in Amazon SageMaker. In Part 1, we confirmed the right way to get began utilizing AWS Cost Explorer to determine value optimization alternatives in SageMaker. On this put up, we deal with SageMaker inference environments: real-time inference, batch remodel, asynchronous inference, and serverless inference.
SageMaker offers multiple inference options so that you can decide from primarily based in your workload necessities:
- Real-time inference for on-line, low latency, or excessive throughput necessities
- Batch transform for offline, scheduled processing and once you don’t want a persistent endpoint
- Asynchronous inference for when you might have giant payloads with lengthy processing instances and wish to queue requests
- Serverless inference for when you might have intermittent or unpredictable site visitors patterns and may tolerate chilly begins
Within the following sections, we talk about every inference choice in additional element.
SageMaker real-time inference
While you create an endpoint, SageMaker attaches an Amazon Elastic Block Store (Amazon EBS) storage quantity to the Amazon Elastic Compute Cloud (Amazon EC2) occasion that hosts the endpoint. That is true for all occasion sorts that don’t include a SSD storage. As a result of the d* occasion sorts include an NVMe SSD storage, SageMaker doesn’t connect an EBS storage quantity to those ML compute situations. Consult with Host instance storage volumes for the scale of the storage volumes that SageMaker attaches for every occasion kind for a single endpoint and for a multi-model endpoint.
The price of SageMaker real-time endpoints is predicated on the per instance-hour consumed for every occasion whereas the endpoint is operating, the price of GB-month of provisioned storage (EBS quantity), in addition to the GB knowledge processed out and in of the endpoint occasion, as outlined in Amazon SageMaker Pricing. In Value Explorer, you may view real-time endpoint prices by making use of a filter on the utilization kind. The names of those utilization sorts are structured as follows:
REGION-Host:instanceType(for instance,USE1-Host:ml.c5.9xlarge)REGION-Host:VolumeUsage.gp2(for instance,USE1-Host:VolumeUsage.gp2)REGION-Hst:Knowledge-Bytes-Out(for instance,USE2-Hst:Knowledge-Bytes-In)REGION-Hst:Knowledge-Bytes-Out(for instance,USW2-Hst:Knowledge-Bytes-Out)
As proven within the following screenshot, filtering by the utilization kind Host: will present an inventory of real-time internet hosting utilization sorts in an account.
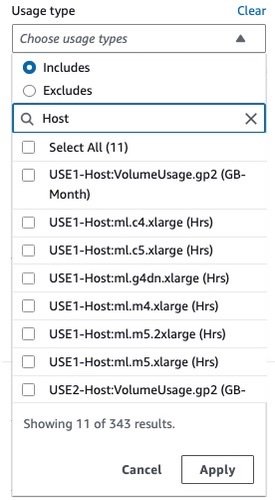
You’ll be able to both choose particular utilization sorts or choose Choose All and select Apply to show the price breakdown of SageMaker real-time internet hosting utilization. To see the price and utilization breakdown by occasion hours, it’s essential to de-select all of the REGION-Host:VolumeUsage.gp2 utilization sorts earlier than making use of the utilization kind filter. You may as well apply further filters akin to account quantity, EC2 occasion kind, value allocation tag, Area, and more. The next screenshot reveals value and utilization graphs for the chosen internet hosting utilization sorts.
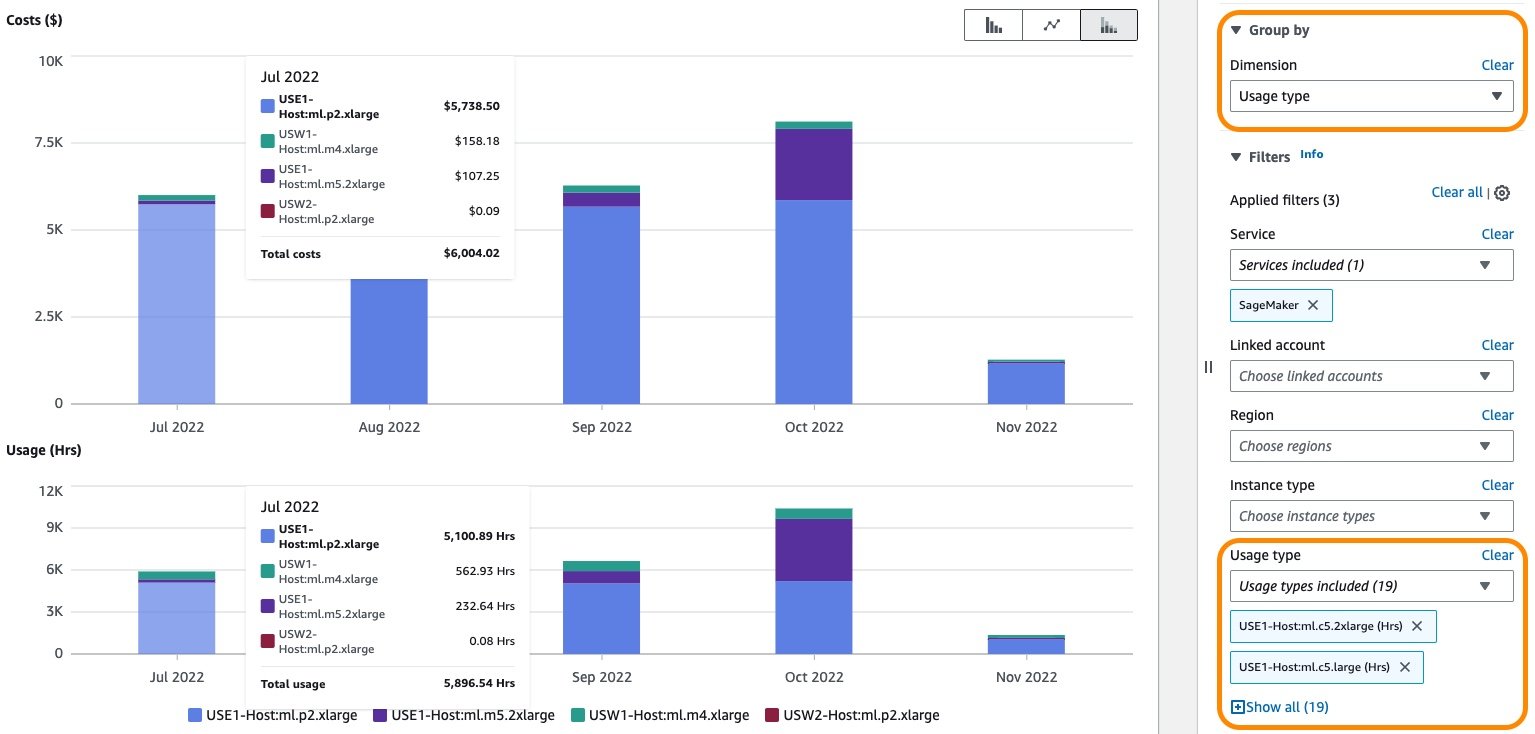
Moreover, you may discover the price related to a number of internet hosting situations through the use of the Occasion kind filter. The next screenshot reveals value and utilization breakdown for internet hosting occasion ml.p2.xlarge.
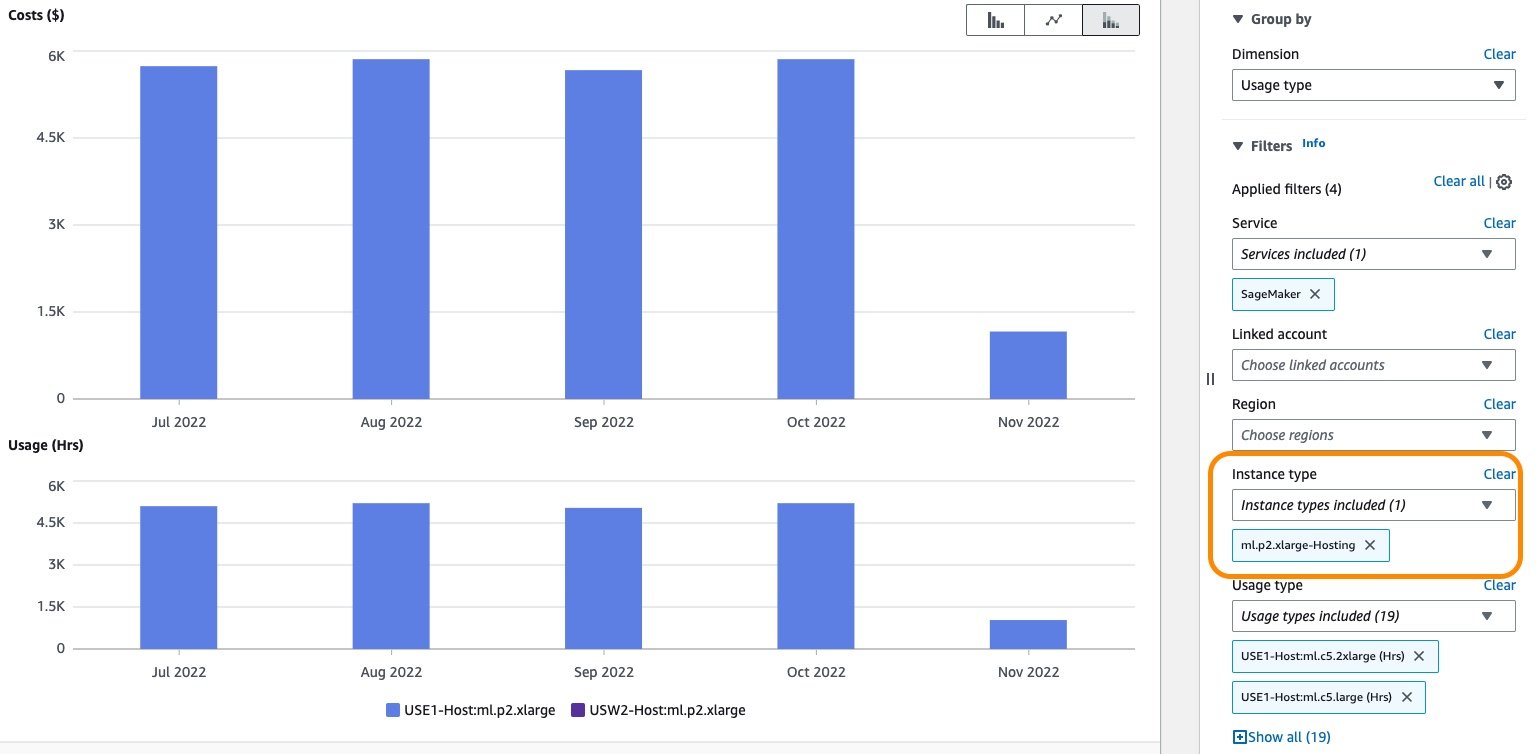
Equally, the price for GB knowledge processed in and processed out may be displayed by choosing the related utilization sorts as an utilized filter, as proven within the following screenshot.
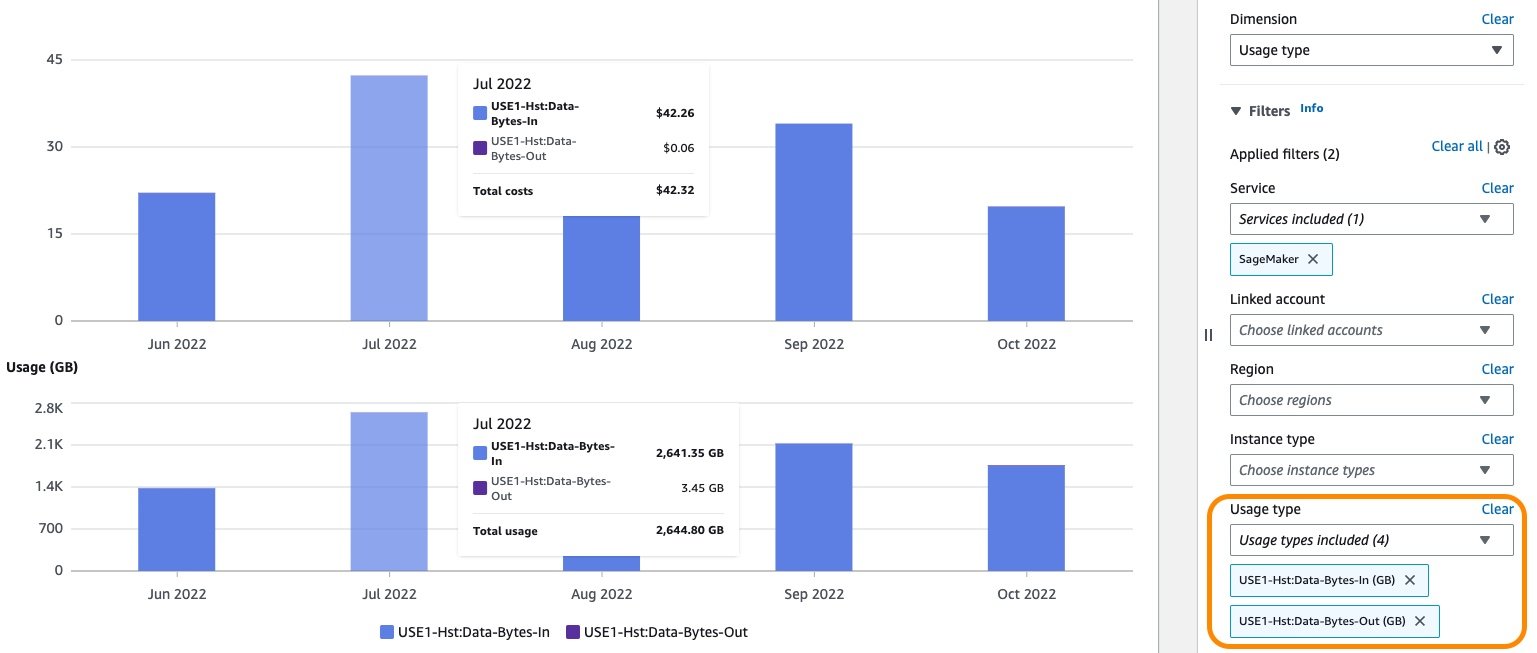
After you might have achieved your required outcomes with filters and groupings, you may both obtain your outcomes by selecting Obtain as CSV or save the report by selecting Save to report library. For common steerage on utilizing Value Explorer, seek advice from AWS Cost Explorer’s New Look and Common Use Cases.
Optionally, you may allow AWS Cost and Usage Reports (AWS CUR) to realize insights into the price and utilization knowledge to your accounts. AWS CUR incorporates hourly AWS consumption particulars. It’s saved in Amazon Simple Storage Service (Amazon S3) within the payer account, which consolidates knowledge for all of the linked accounts. You’ll be able to run queries to research traits in your utilization and take acceptable motion to optimize value. Amazon Athena is a serverless question service that you should utilize to research the information from AWS CUR in Amazon S3 utilizing normal SQL. Extra info and instance queries may be discovered within the AWS CUR Query Library.
You may as well feed AWS CUR knowledge into Amazon QuickSight, the place you may slice and cube it any means you’d like for reporting or visualization functions. For directions, see How do I ingest and visualize the AWS Cost and Usage Report (CUR) into Amazon QuickSight.
You’ll be able to receive resource-level info akin to endpoint ARN, endpoint occasion sorts, hourly occasion price, each day utilization hours, and extra from AWS CUR. You may as well embrace cost-allocation tags in your question for an extra degree of granularity. The next instance question returns real-time internet hosting useful resource utilization for the final 3 months for the given payer account:
The next screenshot reveals the outcomes obtained from operating the question utilizing Athena. For extra info, seek advice from Querying Cost and Usage Reports using Amazon Athena.

The results of the question reveals that endpoint mme-xgboost-housing with ml.x4.xlarge occasion is reporting 24 hours of runtime for a number of consecutive days. The occasion price is $0.24/hour and the each day value for operating for twenty-four hours is $5.76.
AWS CUR outcomes may help you determine patterns of endpoints operating for consecutive days in every of the linked accounts, in addition to endpoints with the best month-to-month value. This could additionally make it easier to resolve whether or not the endpoints in non-production accounts may be deleted to avoid wasting value.
Optimize prices for real-time endpoints
From a value administration perspective, it’s vital to determine under-utilized (or over-sized) situations and convey the occasion dimension and counts, if required, consistent with workload necessities. Widespread system metrics like CPU/GPU utilization and reminiscence utilization are written to Amazon CloudWatch for all internet hosting situations. For real-time endpoints, SageMaker makes a number of further metrics obtainable in CloudWatch. Among the generally monitored metrics embrace invocation counts and invocation 4xx/5xx errors. For a full listing of metrics, seek advice from Monitor Amazon SageMaker with Amazon CloudWatch.
The metric CPUUtilization supplies the sum of every particular person CPU core’s utilization. The CPU utilization of every core vary is 0–100. For instance, if there are 4 CPUs, the CPUUtilization vary is 0–400%. The metric MemoryUtilization is the share of reminiscence that’s utilized by the containers on an occasion. This worth vary is 0–100%. The next screenshot reveals an instance of CloudWatch metrics CPUUtilization and MemoryUtilization for an endpoint occasion ml.m4.10xlarge that comes with 40 vCPUs and 160 GiB reminiscence.


These metrics graphs present most CPU utilization of roughly 3,000%, which is the equal of 30 vCPUs. Which means that this endpoint isn’t using greater than 30 vCPUs out of the entire capability of 40 vCPUs. Equally, the reminiscence utilization is under 6%. Utilizing this info, you may probably experiment with a smaller occasion that may match this useful resource want. Moreover, the CPUUtilization metric reveals a traditional sample of periodic excessive and low CPU demand, which makes this endpoint a very good candidate for auto scaling. You can begin with a smaller occasion and scale out first as your compute demand adjustments. For info, see Automatically Scale Amazon SageMaker Models.
SageMaker is nice for testing new fashions as a result of you may simply deploy them into an A/B testing setting utilizing production variants, and also you solely pay for what you utilize. Every manufacturing variant runs by itself compute occasion and also you’re charged per instance-hour consumed for every occasion whereas the variant is operating.
SageMaker additionally helps shadow variants, which have the identical elements as a manufacturing variant and run on their very own compute occasion. With shadow variants, SageMaker robotically deploys the mannequin in a check setting, routes a replica of the inference requests obtained by the manufacturing mannequin to the check mannequin in actual time, and collects efficiency metrics akin to latency and throughput. This allows you to validate any new candidate element of your mannequin serving stack earlier than selling it to manufacturing.
While you’re achieved along with your checks and aren’t utilizing the endpoint or the variants extensively anymore, you must delete it to avoid wasting value. As a result of the mannequin is saved in Amazon S3, you may recreate it as wanted. You’ll be able to robotically detect these endpoints and take corrective actions (akin to deleting them) through the use of Amazon CloudWatch Events and AWS Lambda capabilities. For instance, you should utilize the Invocations metric to get the entire variety of requests despatched to a mannequin endpoint after which detect if the endpoints have been idle for the previous variety of hours (with no invocations over a sure interval, akin to 24 hours).
In case you have a number of under-utilized endpoint situations, take into account internet hosting choices akin to multi-model endpoints (MMEs), multi-container endpoints (MCEs), and serial inference pipelines to consolidate utilization to fewer endpoint situations.
For real-time and asynchronous inference mannequin deployment, you may optimize value and efficiency by deploying fashions on SageMaker utilizing AWS Graviton. AWS Graviton is a household of processors designed by AWS that present one of the best worth efficiency and are extra power environment friendly than their x86 counterparts. For steerage on deploying an ML mannequin to AWS Graviton-based situations and particulars on the value efficiency profit, seek advice from Run machine learning inference workloads on AWS Graviton-based instances with Amazon SageMaker. SageMaker additionally helps AWS Inferentia accelerators by means of the ml.inf2 household of situations for deploying ML fashions for real-time and asynchronous inference. You should use these situations on SageMaker to attain excessive efficiency at a low value for generative synthetic intelligence (AI) fashions, together with giant language fashions (LLMs) and imaginative and prescient transformers.
As well as, you should utilize Amazon SageMaker Inference Recommender to run load checks and consider the value efficiency advantages of deploying your mannequin on these situations. For extra steerage on robotically detecting idle SageMaker endpoints, in addition to occasion right-sizing and auto scaling for SageMaker endpoints, seek advice from Ensure efficient compute resources on Amazon SageMaker.
SageMaker batch remodel
Batch inference, or offline inference, is the method of producing predictions on a batch of observations. Offline predictions are appropriate for bigger datasets and in instances the place you may afford to attend a number of minutes or hours for a response.
The price for SageMaker batch remodel is predicated on the per instance-hour consumed for every occasion whereas the batch remodel job is operating, as outlined in Amazon SageMaker Pricing. In Value Explorer, you may discover batch remodel prices by making use of a filter on the utilization kind. The identify of this utilization kind is structured as REGION-Tsform:instanceType (for instance, USE1-Tsform:ml.c5.9xlarge).
As proven within the following screenshot, filtering by utilization kind Tsform: will present an inventory of SageMaker batch remodel utilization sorts in an account.
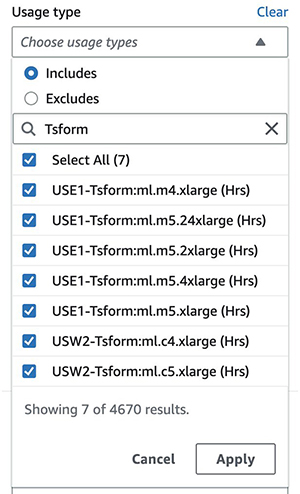
You’ll be able to both choose particular utilization sorts or choose Choose All and select Apply to show the price breakdown of batch remodel occasion utilization for the chosen sorts. As talked about earlier, you can too apply further filters. The next screenshot reveals value and utilization graphs for the chosen batch remodel utilization sorts.
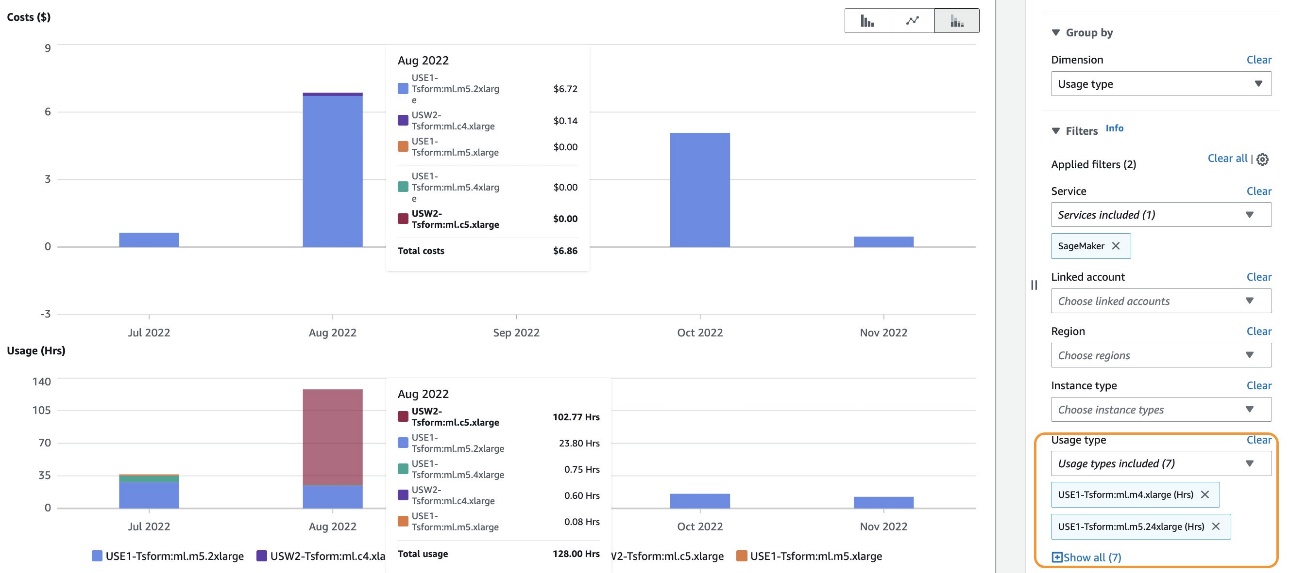
Optimize prices for batch remodel
SageMaker batch remodel solely prices you for the situations used whereas your jobs are operating. In case your knowledge is already in Amazon S3, then there isn’t any value for studying enter knowledge from Amazon S3 and writing output knowledge to Amazon S3. All output objects are tried to be uploaded to Amazon S3. If all are profitable, then the batch remodel job is marked as full. If a number of objects fail, the batch remodel job is marked as failed.
Fees for batch remodel jobs apply within the following eventualities:
- The job is profitable
- Failure because of
ClientErrorand the mannequin container is SageMaker or a SageMaker managed framework - Failure because of
AlgorithmErrororClientErrorand the mannequin container is your individual customized container (BYOC)
The next are a few of the greatest practices for optimizing a SageMaker batch remodel job. These suggestions can scale back the entire runtime of your batch remodel job, thereby reducing prices:
- Set BatchStrategy to
MultiRecordandSplitTypetoLinefor those who want the batch remodel job to make mini batches from the enter file. If it might probably’t robotically cut up the dataset into mini batches, you may divide it into mini batches by placing every batch in a separate enter file, positioned within the knowledge supply S3 bucket. - Be sure that the batch dimension suits into the reminiscence. SageMaker often handles this robotically; nonetheless, when dividing batches manually, this must be tuned primarily based on the reminiscence.
- Batch remodel partitions the S3 objects within the enter by key and maps these objects to situations. When you might have multiples recordsdata, one occasion would possibly course of
input1.csv, and one other occasion would possibly course ofinput2.csv. In case you have one enter file however initialize a number of compute situations, just one occasion processes the enter file and the remainder of the situations are idle. Make sure that the variety of recordsdata is the same as or larger than the variety of situations. - In case you have a lot of small recordsdata, it could be helpful to mix a number of recordsdata right into a small variety of larger recordsdata to cut back Amazon S3 interplay time.
- Should you’re utilizing the CreateTransformJob API, you may scale back the time it takes to finish batch remodel jobs through the use of optimum values for parameters akin to MaxPayloadInMB, MaxConcurrentTransforms, or BatchStrategy:
MaxConcurrentTransformssignifies the utmost variety of parallel requests that may be despatched to every occasion in a remodel job. The perfect worth forMaxConcurrentTransformsis the same as the variety of vCPU cores in an occasion.MaxPayloadInMBis the utmost allowed dimension of the payload, in MB. The worth inMaxPayloadInMBshould be larger than or equal to the scale of a single report. To estimate the scale of a report in MB, divide the scale of your dataset by the variety of data. To make sure that the data match throughout the most payload dimension, we advocate utilizing a barely bigger worth. The default worth is 6 MB.MaxPayloadInMBshould not be larger than 100 MB. Should you specify the optionally availableMaxConcurrentTransformsparameter, then the worth of (MaxConcurrentTransforms*MaxPayloadInMB) should additionally not exceed 100 MB.- For instances the place the payload could be arbitrarily giant and is transmitted utilizing HTTP chunked encoding, set the MaxPayloadInMB worth to 0. This characteristic works solely in supported algorithms. At the moment, SageMaker built-in algorithms don’t assist HTTP chunked encoding.
- Batch inference duties are often good candidates for horizontal scaling. Every employee inside a cluster can function on a unique subset of information with out the necessity to trade info with different staff. AWS affords a number of storage and compute choices that allow horizontal scaling. If a single occasion will not be adequate to satisfy your efficiency necessities, think about using a number of situations in parallel to distribute the workload. For key concerns when architecting batch remodel jobs, seek advice from Batch Inference at Scale with Amazon SageMaker.
- Repeatedly monitor the efficiency metrics of your SageMaker batch remodel jobs utilizing CloudWatch. Search for bottlenecks, akin to excessive CPU or GPU utilization, reminiscence utilization, or community throughput, to find out if it’s essential to alter occasion sizes or configurations.
- SageMaker makes use of the Amazon S3 multipart upload API to add outcomes from a batch remodel job to Amazon S3. If an error happens, the uploaded outcomes are faraway from Amazon S3. In some instances, akin to when a community outage happens, an incomplete multipart add would possibly stay in Amazon S3. To keep away from incurring storage prices, we advocate that you simply add the S3 bucket policy to the S3 bucket lifecycle guidelines. This coverage deletes incomplete multipart uploads that could be saved within the S3 bucket. For extra info, see Managing your storage lifecycle.
SageMaker asynchronous inference
Asynchronous inference is a good alternative for cost-sensitive workloads with giant payloads and burst site visitors. Requests can take as much as 1 hour to course of and have payload sizes of as much as 1 GB, so it’s extra appropriate for workloads which have relaxed latency necessities.
Invocation of asynchronous endpoints differs from real-time endpoints. Somewhat than passing a request payload synchronously with the request, you add the payload to Amazon S3 and move an S3 URI as part of the request. Internally, SageMaker maintains a queue with these requests and processes them. Throughout endpoint creation, you may optionally specify an Amazon Simple Notification Service (Amazon SNS) matter to obtain success or error notifications. While you obtain the notification that your inference request has been efficiently processed, you may entry the outcome within the output Amazon S3 location.
The price for asynchronous inference is predicated on the per instance-hour consumed for every occasion whereas the endpoint is operating, value of GB-month of provisioned storage, in addition to GB knowledge processed out and in of the endpoint occasion, as outlined in Amazon SageMaker Pricing. In Value Explorer, you may filter asynchronous inference prices by making use of a filter on the utilization kind. The identify of this utilization kind is structured as REGION-AsyncInf:instanceType (for instance, USE1-AsyncInf:ml.c5.9xlarge). Observe that GB quantity and GB knowledge processed utilization sorts are the identical as real-time endpoints, as talked about earlier on this put up.
As proven within the following screenshot, filtering by the utilization kind AsyncInf: in Value Explorer shows a value breakdown by asynchronous endpoint utilization sorts.
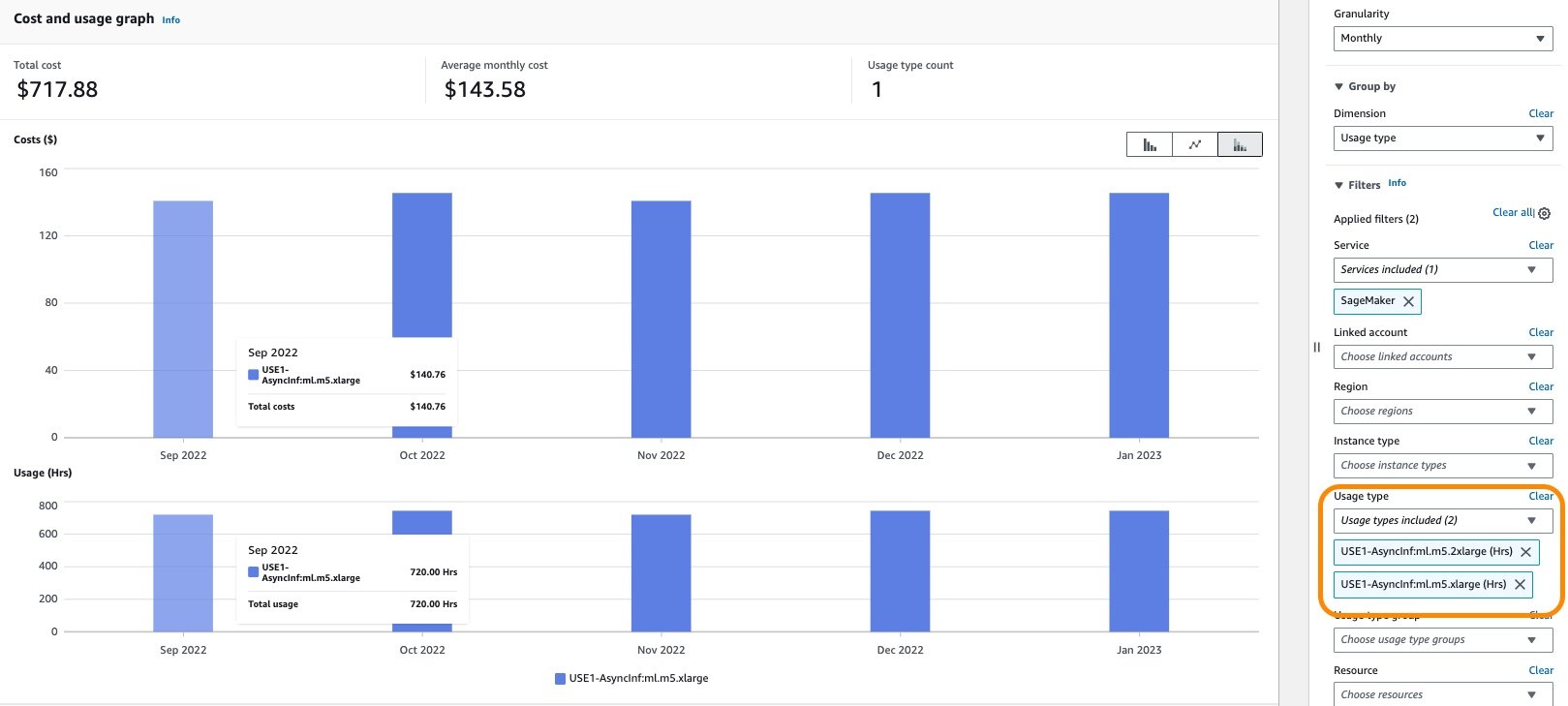
To see the price and utilization breakdown by occasion hours, it’s essential to de-select all of the REGION-Host:VolumeUsage.gp2 utilization sorts earlier than making use of the utilization kind filter. You may as well apply further filters. Useful resource-level info akin to endpoint ARN, endpoint occasion sorts, hourly occasion price, and each day utilization hours may be obtained from AWS CUR. The next is an instance of an AWS CUR question to acquire asynchronous internet hosting useful resource utilization for the final 3 months:
The next screenshot reveals the outcomes obtained from operating the AWS CUR question utilizing Athena.

The results of the question reveals that endpoint sagemaker-abc-model-5 with ml.m5.xlarge occasion is reporting 24 hours of runtime for a number of consecutive days. The occasion price is $0.23/hour and the each day value for operating for twenty-four hours is $5.52.
As talked about earlier, AWS CUR outcomes may help you determine patterns of endpoints operating for consecutive days, in addition to endpoints with the best month-to-month value. This could additionally make it easier to resolve whether or not the endpoints in non-production accounts may be deleted to avoid wasting value.
Optimize prices for asynchronous inference
Identical to the real-time endpoints, the price for asynchronous endpoints is predicated on the occasion kind utilization. Subsequently, it’s vital to determine under-utilized situations and resize them primarily based on the workload necessities. As a way to monitor asynchronous endpoints, SageMaker makes several metrics akin to ApproximateBacklogSize, HasBacklogWithoutCapacity, and extra obtainable in CloudWatch. These metrics can present requests within the queue for an occasion and can be utilized for auto scaling an endpoint. SageMaker asynchronous inference additionally consists of host-level metrics. For info on host-level metrics, see SageMaker Jobs and Endpoint Metrics. These metrics can present useful resource utilization that may make it easier to right-size the occasion.
SageMaker helps auto scaling for asynchronous endpoints. In contrast to real-time hosted endpoints, asynchronous inference endpoints assist cutting down situations to zero by setting the minimal capability to zero. For asynchronous endpoints, SageMaker strongly recommends that you simply create a coverage configuration for target-tracking scaling for a deployed mannequin (variant). It is advisable outline the scaling coverage that scaled on the ApproximateBacklogPerInstance customized metric and set the MinCapacity worth to zero.
Asynchronous inference allows you to save on prices by auto scaling the occasion depend to zero when there are not any requests to course of, so that you solely pay when your endpoint is processing requests. Requests which might be obtained when there are zero situations are queued for processing after the endpoint scales up. Subsequently, to be used instances that may tolerate a chilly begin penalty of some minutes, you may optionally scale down the endpoint occasion depend to zero when there are not any excellent requests and cut back up as new requests arrive. Chilly begin time will depend on the time required to launch a brand new endpoint from scratch. Additionally, if the mannequin itself is large, then the time may be longer. In case your job is predicted to take longer than the 1-hour processing time, you might wish to take into account SageMaker batch remodel.
Moreover, you might also take into account your request’s queued time mixed with the processing time to decide on the occasion kind. For instance, in case your use case can tolerate hours of wait time, you may select a smaller occasion to avoid wasting value.
For extra steerage on occasion right-sizing and auto scaling for SageMaker endpoints, seek advice from Ensure efficient compute resources on Amazon SageMaker.
Serverless inference
Serverless inference lets you deploy ML fashions for inference with out having to configure or handle the underlying infrastructure. Primarily based on the quantity of inference requests your mannequin receives, SageMaker serverless inference robotically provisions, scales, and turns off compute capability. Consequently, you pay for under the compute time to run your inference code and the quantity of information processed, not for idle time. For serverless endpoints, occasion provisioning will not be crucial. It is advisable present the memory size and maximum concurrency. As a result of serverless endpoints provision compute assets on demand, your endpoint could expertise a couple of additional seconds of latency (chilly begin) for the primary invocation after an idle interval. You pay for the compute capability used to course of inference requests, billed by the millisecond, GB-month of provisioned storage, and the quantity of information processed. The compute cost will depend on the reminiscence configuration you select.
In Value Explorer, you may filter serverless endpoints prices by making use of a filter on the utilization kind. The identify of this utilization kind is structured as REGION-ServerlessInf:Mem-MemorySize (for instance, USE2-ServerlessInf:Mem-4GB). Observe that GB quantity and GB knowledge processed utilization sorts are the identical as real-time endpoints.
You’ll be able to see the price breakdown by making use of further filters akin to account quantity, occasion kind, Area, and extra. The next screenshot reveals the price breakdown by making use of filters for the serverless inference utilization kind.
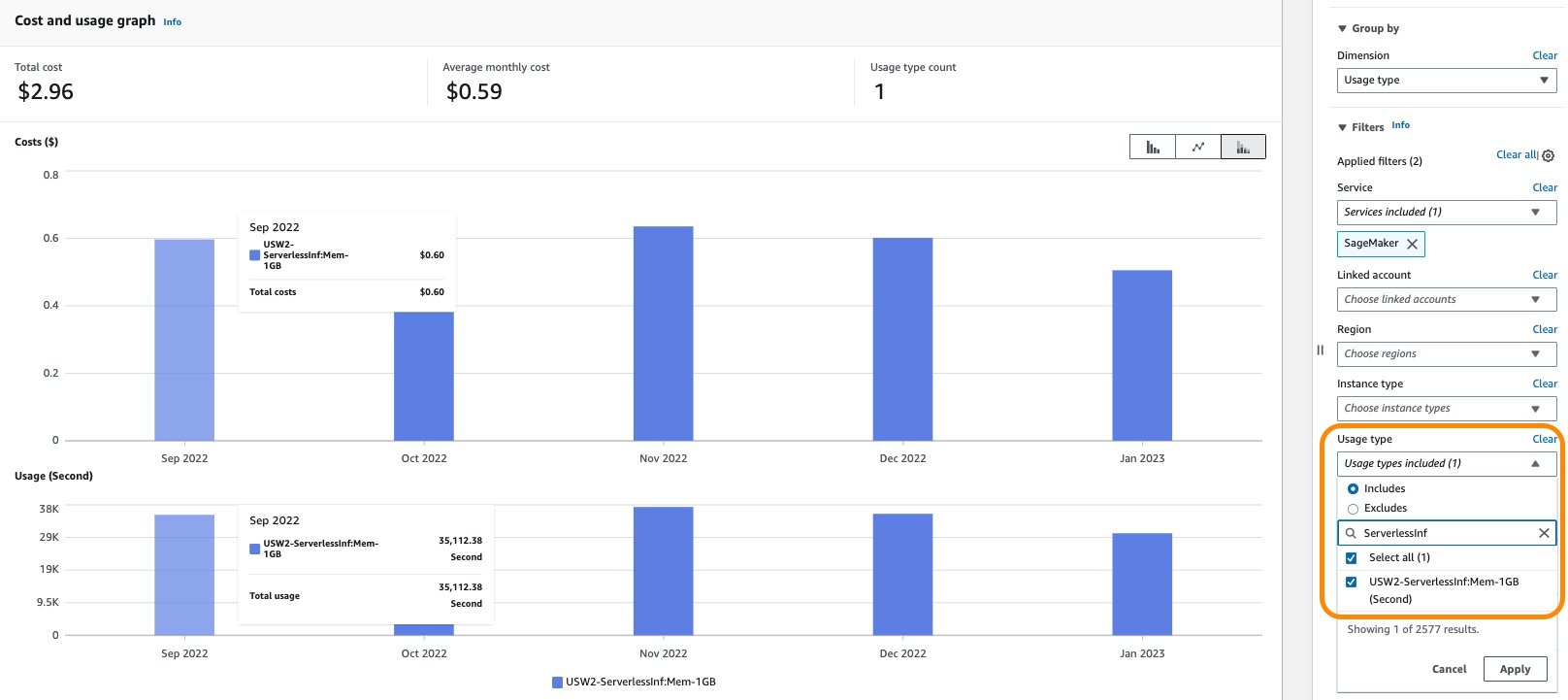
Optimize value for serverless inference
When configuring your serverless endpoint, you may specify the reminiscence dimension and most variety of concurrent invocations. SageMaker serverless inference auto-assigns compute assets proportional to the reminiscence you choose. Should you select a bigger reminiscence dimension, your container has entry to extra vCPUs. With serverless inference, you solely pay for the compute capability used to course of inference requests, billed by the millisecond, and the quantity of information processed. The compute cost will depend on the reminiscence configuration you select. The reminiscence sizes you may select are 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB, and 6144 MB. The pricing will increase with the reminiscence dimension increments, as defined in Amazon SageMaker Pricing, so it’s vital to pick the right reminiscence dimension. As a common rule, the reminiscence dimension must be at the very least as giant as your mannequin dimension. Nevertheless, it’s a very good apply to seek advice from reminiscence utilization when deciding the endpoint reminiscence dimension, along with the mannequin dimension itself.
Common greatest practices for optimizing SageMaker inference prices
Optimizing internet hosting prices isn’t a one-time occasion. It’s a steady means of monitoring deployed infrastructure, utilization patterns, and efficiency, and likewise holding a eager eye on new modern options that AWS releases that would affect value. Contemplate the next greatest practices:
- Select an acceptable occasion kind – SageMaker helps a number of occasion sorts, every with various mixtures of CPU, GPU, reminiscence, and storage capacities. Primarily based in your mannequin’s useful resource necessities, select an occasion kind that gives the mandatory assets with out over-provisioning. For details about obtainable SageMaker occasion sorts, their specs, and steerage on choosing the proper occasion, seek advice from Ensure efficient compute resources on Amazon SageMaker.
- Take a look at utilizing native mode – As a way to detect failures and debug sooner, it’s beneficial to check the code and container (in case of BYOC) in local mode earlier than operating the inference workload on the distant SageMaker occasion. Native mode is a good way to check your scripts earlier than operating them in a SageMaker managed internet hosting setting.
- Optimize fashions to be extra performant – Unoptimized fashions can result in longer runtimes and use extra assets. You’ll be able to select to make use of extra or larger situations to enhance efficiency; nonetheless, this results in larger prices. By optimizing your fashions to be extra performant, you could possibly decrease prices through the use of fewer or smaller situations whereas holding the identical or higher efficiency traits. You should use Amazon SageMaker Neo with SageMaker inference to robotically optimize fashions. For extra particulars and samples, see Optimize model performance using Neo.
- Use tags and price administration instruments – To take care of visibility into your inference workloads, it’s beneficial to make use of tags in addition to AWS value administration instruments akin to AWS Budgets, the AWS Billing console, and the forecasting characteristic of Value Explorer. You may as well discover SageMaker Financial savings Plans as a versatile pricing mannequin. For extra details about these choices, seek advice from Part 1 of this collection.
Conclusion
On this put up, we offered steerage on value evaluation and greatest practices when utilizing SageMaker inference choices. As machine studying establishes itself as a robust device throughout industries, coaching and operating ML fashions wants to stay cost-effective. SageMaker affords a large and deep characteristic set for facilitating every step within the ML pipeline and supplies value optimization alternatives with out impacting efficiency or agility. Attain out to your AWS crew for value steerage in your SageMaker workloads.
In regards to the Authors
 Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise prospects offering technical steerage with greatest practices for deploying and sustaining AI/ML options within the AWS ecosystem. She has labored with a variety of organizations on varied deep studying use instances involving NLP and pc imaginative and prescient. She is captivated with empowering organizations to leverage generative AI to boost their use expertise. In her spare time, she enjoys films, music, and literature.
Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise prospects offering technical steerage with greatest practices for deploying and sustaining AI/ML options within the AWS ecosystem. She has labored with a variety of organizations on varied deep studying use instances involving NLP and pc imaginative and prescient. She is captivated with empowering organizations to leverage generative AI to boost their use expertise. In her spare time, she enjoys films, music, and literature.
 Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Primarily based out of Israel, Uri works to empower enterprise prospects on all issues ML to design, construct, and function at scale. In his spare time, he enjoys biking, mountain climbing, and rock and roll climbing.
Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Primarily based out of Israel, Uri works to empower enterprise prospects on all issues ML to design, construct, and function at scale. In his spare time, he enjoys biking, mountain climbing, and rock and roll climbing.