Finest practices and open challenges – Google AI Weblog
Massive machine studying (ML) fashions are ubiquitous in trendy functions: from spam filters to recommender systems and virtual assistants. These fashions obtain outstanding efficiency partially as a result of abundance of accessible coaching information. Nonetheless, these information can generally include non-public info, together with private identifiable info, copyright materials, and so on. Due to this fact, defending the privateness of the coaching information is essential to sensible, utilized ML.
Differential Privacy (DP) is without doubt one of the most generally accepted applied sciences that permits reasoning about information anonymization in a proper means. Within the context of an ML mannequin, DP can assure that every particular person consumer’s contribution is not going to lead to a considerably totally different mannequin. A mannequin’s privateness ensures are characterised by a tuple (ε, δ), the place smaller values of each signify stronger DP ensures and higher privateness.
Whereas there are profitable examples of protecting training data utilizing DP, acquiring good utility with differentially non-public ML (DP-ML) strategies might be difficult. First, there are inherent privateness/computation tradeoffs that will restrict a mannequin’s utility. Additional, DP-ML fashions typically require architectural and hyperparameter tuning, and tips on how to do that successfully are restricted or tough to seek out. Lastly, non-rigorous privateness reporting makes it difficult to match and select the perfect DP strategies.
In “How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy”, to seem within the Journal of Artificial Intelligence Research, we focus on the present state of DP-ML analysis. We offer an outline of frequent strategies for acquiring DP-ML fashions and focus on analysis, engineering challenges, mitigation strategies and present open questions. We are going to current tutorials primarily based on this work at ICML 2023 and KDD 2023.
DP-ML strategies
DP might be launched through the ML mannequin improvement course of in three locations: (1) on the enter information stage, (2) throughout coaching, or (3) at inference. Every choice supplies privateness protections at totally different levels of the ML improvement course of, with the weakest being when DP is launched on the prediction stage and the strongest being when launched on the enter stage. Making the enter information differentially non-public implies that any mannequin that’s skilled on this information may even have DP ensures. When introducing DP through the coaching, solely that exact mannequin has DP ensures. DP on the prediction stage implies that solely the mannequin’s predictions are protected, however the mannequin itself isn’t differentially non-public.
 |
| The duty of introducing DP will get progressively simpler from the left to proper. |
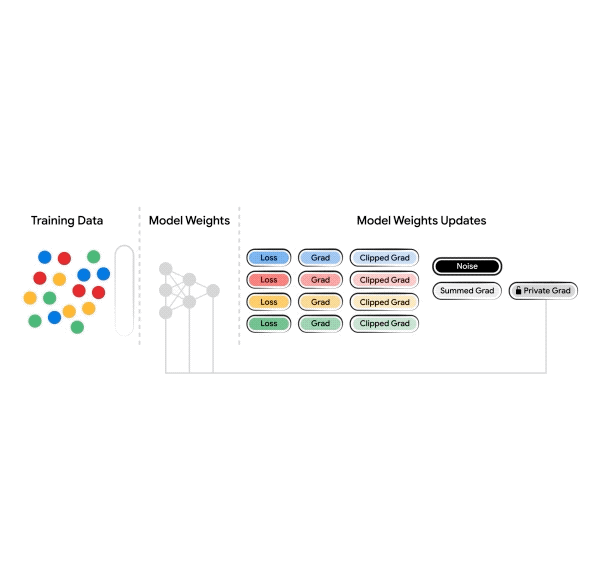
DP is usually launched throughout coaching (DP-training). Gradient noise injection strategies, like DP-SGD or DP-FTRL, and their extensions are presently probably the most sensible strategies for reaching DP ensures in complicated fashions like massive deep neural networks.
DP-SGD builds off of the stochastic gradient descent (SGD) optimizer with two modifications: (1) per-example gradients are clipped to a sure norm to restrict sensitivity (the affect of a person instance on the general mannequin), which is a sluggish and computationally intensive course of, and (2) a loud gradient replace is fashioned by taking aggregated gradients and including noise that’s proportional to the sensitivity and the power of privateness ensures.
 |
| DP-SGD is a modification of SGD that entails a) clipping per-example gradients to restrict the sensitivity and b) including the noise, calibrated to the sensitivity and privateness ensures, to the aggregated gradients, earlier than the gradient replace step. |
Present DP-training challenges
Gradient noise injection strategies often exhibit: (1) lack of utility, (2) slower coaching, and (3) an elevated memory footprint.
Lack of utility:
The perfect methodology for decreasing utility drop is to make use of extra computation. Utilizing bigger batch sizes and/or extra iterations is without doubt one of the most outstanding and sensible methods of bettering a mannequin’s efficiency. Hyperparameter tuning can also be extraordinarily vital however typically ignored. The utility of DP-trained fashions is delicate to the overall quantity of noise added, which will depend on hyperparameters, just like the clipping norm and batch dimension. Moreover, different hyperparameters like the educational fee needs to be re-tuned to account for noisy gradient updates.
An alternative choice is to acquire extra information or use public information of comparable distribution. This may be finished by leveraging publicly obtainable checkpoints, like ResNet or T5, and fine-tuning them utilizing non-public information.
Slower coaching:
Most gradient noise injection strategies restrict sensitivity through clipping per-example gradients, significantly slowing down backpropagation. This may be addressed by selecting an environment friendly DP framework that effectively implements per-example clipping.
Elevated reminiscence footprint:
DP-training requires important reminiscence for computing and storing per-example gradients. Moreover, it requires considerably bigger batches to acquire higher utility. Growing the computation assets (e.g., the quantity and dimension of accelerators) is the best resolution for further reminiscence necessities. Alternatively, several works advocate for gradient accumulation the place smaller batches are mixed to simulate a bigger batch earlier than the gradient replace is utilized. Additional, some algorithms (e.g., ghost clipping, which is predicated on this paper) keep away from per-example gradient clipping altogether.
Finest practices
The next finest practices can attain rigorous DP ensures with the perfect mannequin utility doable.
Choosing the proper privateness unit:
First, we needs to be clear a few mannequin’s privateness ensures. That is encoded by choosing the “privateness unit,” which represents the neighboring dataset idea (i.e., datasets the place just one row is totally different). Instance-level safety is a standard alternative within the analysis literature, however is probably not ultimate, nonetheless, for user-generated information if particular person customers contributed a number of data to the coaching dataset. For such a case, user-level safety is perhaps extra acceptable. For textual content and sequence information, the selection of the unit is tougher since in most functions particular person coaching examples will not be aligned to the semantic that means embedded within the textual content.
Selecting privateness ensures:
We define three broad tiers of privateness ensures and encourage practitioners to decide on the bottom doable tier under:
- Tier 1 — Sturdy privateness ensures: Selecting ε ≤ 1 supplies a robust privateness assure, however steadily leads to a major utility drop for giant fashions and thus could solely be possible for smaller fashions.
- Tier 2 — Cheap privateness ensures: We advocate for the presently undocumented, however nonetheless extensively used, aim for DP-ML fashions to realize an ε ≤ 10.
- Tier 3 — Weak privateness ensures: Any finite ε is an enchancment over a mannequin with no formal privateness assure. Nonetheless, for ε > 10, the DP assure alone can’t be taken as enough proof of information anonymization, and extra measures (e.g., empirical privateness auditing) could also be essential to make sure the mannequin protects consumer information.
Hyperparameter tuning:
Selecting hyperparameters requires optimizing over three inter-dependent aims: 1) mannequin utility, 2) privateness value ε, and three) computation value. Widespread methods take two of the three as constraints, and deal with optimizing the third. We offer strategies that can maximize the utility with a restricted variety of trials, e.g., tuning with privateness and computation constraints.
Reporting privateness ensures:
Plenty of works on DP for ML report solely ε and probably δ values for his or her coaching process. Nonetheless, we consider that practitioners ought to present a complete overview of mannequin ensures that features:
- DP setting: Are the outcomes assuming central DP with a trusted service supplier, local DP, or another setting?
- Instantiating the DP definition:
- Information accesses lined: Whether or not the DP assure applies (solely) to a single coaching run or additionally covers hyperparameter tuning and so on.
- Remaining mechanism’s output: What is roofed by the privateness ensures and might be launched publicly (e.g., mannequin checkpoints, the complete sequence of privatized gradients, and so on.)
- Unit of privateness: The chosen “privateness unit” (example-level, user-level, and so on.)
- Adjacency definition for DP “neighboring” datasets: An outline of how neighboring datasets differ (e.g., add-or-remove, replace-one, zero-out-one).
- Privateness accounting particulars: Offering accounting particulars, e.g., composition and amplification, are vital for correct comparability between strategies and may embody:
- Sort of accounting used, e.g., Rényi DP-based accounting, PLD accounting, and so on.
- Accounting assumptions and whether or not they maintain (e.g., Poisson sampling was assumed for privateness amplification however information shuffling was utilized in coaching).
- Formal DP assertion for the mannequin and tuning course of (e.g., the particular ε, δ-DP or ρ-zCDP values).
- Transparency and verifiability: When doable, full open-source code utilizing commonplace DP libraries for the important thing mechanism implementation and accounting parts.
Taking note of all of the parts used:
Often, DP-training is a simple software of DP-SGD or different algorithms. Nonetheless, some parts or losses which might be typically utilized in ML fashions (e.g., contrastive losses, graph neural network layers) needs to be examined to make sure privateness ensures will not be violated.
Open questions
Whereas DP-ML is an lively analysis space, we spotlight the broad areas the place there may be room for enchancment.
Creating higher accounting strategies:
Our present understanding of DP-training ε, δ ensures depends on a variety of strategies, like Rényi DP composition and privateness amplification. We consider that higher accounting strategies for present algorithms will reveal that DP ensures for ML fashions are literally higher than anticipated.
Creating higher algorithms:
The computational burden of utilizing gradient noise injection for DP-training comes from the necessity to use bigger batches and restrict per-example sensitivity. Creating strategies that may use smaller batches or figuring out different methods (other than per-example clipping) to restrict the sensitivity could be a breakthrough for DP-ML.
Higher optimization strategies:
Instantly making use of the identical DP-SGD recipe is believed to be suboptimal for adaptive optimizers as a result of the noise added to denationalise the gradient could accumulate in studying fee computation. Designing theoretically grounded DP adaptive optimizers stays an lively analysis subject. One other potential route is to higher perceive the floor of DP loss, since for traditional (non-DP) ML fashions flatter areas have been proven to generalize better.
Figuring out architectures which might be extra sturdy to noise:
There’s a chance to higher perceive whether or not we have to modify the structure of an present mannequin when introducing DP.
Conclusion
Our survey paper summarizes the present analysis associated to creating ML fashions DP, and supplies sensible tips about how you can obtain the perfect privacy-utility commerce offs. Our hope is that this work will function a reference level for the practitioners who need to successfully apply DP to complicated ML fashions.
Acknowledgements
We thank Hussein Hazimeh, Zheng Xu , Carson Denison , H. Brendan McMahan, Sergei Vassilvitskii, Steve Chien and Abhradeep Thakurta, Badih Ghazi, Chiyuan Zhang for the assistance making ready this weblog put up, paper and tutorials content material. Due to John Guilyard for creating the graphics on this put up, and Ravi Kumar for feedback.





