Peking College Researchers Introduce FastServe: A Distributed Inference Serving System For Giant Language Fashions LLMs
Giant language mannequin (LLM) enhancements create alternatives in varied fields and encourage a brand new wave of interactive AI purposes. Probably the most noteworthy one is ChatGPT, which allows individuals to speak informally with an AI agent to resolve issues starting from software program engineering to language translation. ChatGPT is among the fastest-growing applications in historical past, due to its exceptional capabilities. Many corporations observe the pattern of releasing LLMs and ChatGPT-like merchandise, together with Microsoft’s New Bing, Google’s Bard, Meta’s LLaMa, Stanford’s Alpaca, Databricks’ Dolly, and UC Berkeley’s Vicuna.
LLM inference differs from one other deep neural community (DNN) mannequin inference, reminiscent of ResNet, as a result of it has particular traits. Interactive AI purposes constructed on LLMs should present inferences to operate. These apps’ interactive design necessitates fast job completion instances (JCT) for LLM inference to ship partaking person experiences. For example, shoppers anticipate an instantaneous response once they submit knowledge into ChatGPT. Nevertheless, the inference serving infrastructure is underneath nice pressure as a result of quantity and complexity of LLMs. Companies arrange expensive clusters with accelerators like GPUs and TPUs to deal with LLM inference operations.
DNN inference jobs are sometimes deterministic and extremely predictable, i.e., the mannequin and the {hardware} largely decide the inference job’s execution time. For example, the execution time of varied enter pictures varies a short time utilizing the identical ResNet mannequin on a sure GPU. LLM inference positions, in distinction, have a novel autoregressive sample. The LLM inference work goes by means of a number of rounds. Every iteration produces one output token, which is then added to the enter to make the next token within the following iteration. The output size, which is unknown on the outset, impacts each the execution time and enter size. Most deterministic mannequin inference duties, like these carried out by ResNet, are catered for by present inference serving programs like Clockwork and Shepherd.
They base their scheduling choices on exact execution time profiling, which is ineffective for LLM inference with variable execution instances. Probably the most superior methodology for LLM inference is Orca. It suggests iteration-level scheduling, permitting for including new jobs to or deleting accomplished jobs from the present processing batch after every iteration. Nevertheless, it processes inference jobs utilizing first-come, first-served (FCFS). A scheduled activity runs constantly till it’s accomplished. The processing batch can’t be elevated with an arbitrary variety of incoming features as a result of restricted GPU reminiscence capability and the low JCT necessities of inference jobs. Head-of-line blocking in run-to-completion processing is well-known.
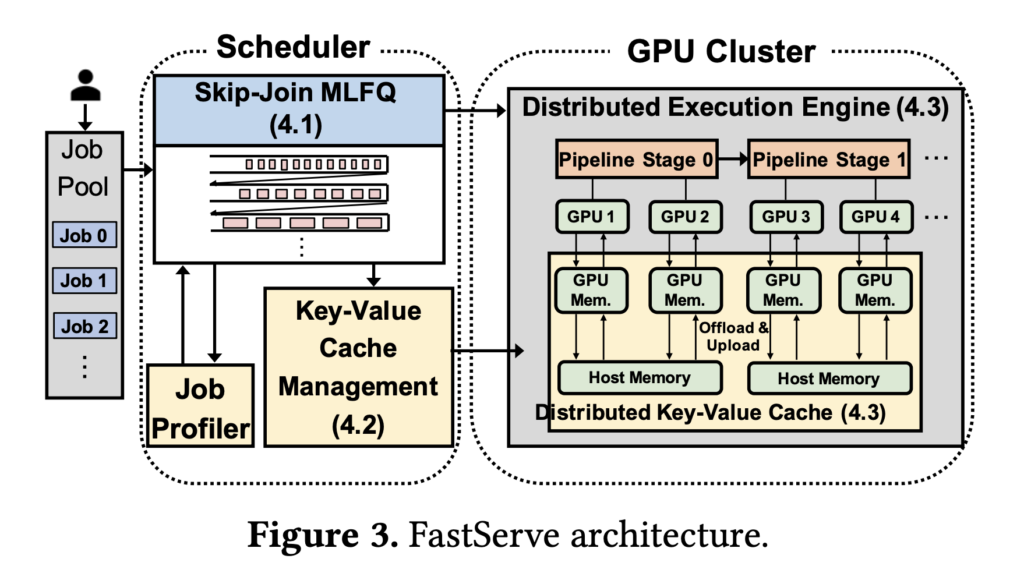
As a result of LLMs are huge in measurement and take a very long time to execute in absolute phrases, the problem is especially extreme for LLM inference operations. Giant LLM inference jobs, particularly these with prolonged output lengths, would take a very long time to finish and impede subsequent quick jobs. Researchers from Peking College developed a distributed inference serving answer for LLMs known as FastServe. To allow preemption on the stage of every output token, FastServe makes use of iteration-level scheduling and the autoregressive sample of LLM inference. FastServe can select whether or not to proceed a scheduled activity after it has generated an output token or to preempt it with one other job within the queue. This allows FastServe to cut back JCT and head-of-line blocking through preemptive scheduling.
A novel skip-join Multi-Degree Suggestions Queue (MLFQ) scheduler serves as the muse of FastServe. MLFQ is a widely known methodology for minimizing common JCT in information-free environments. Every work begins within the highest precedence queue, and if it doesn’t end inside a sure time, it will get demoted to the subsequent precedence queue. LLM inference is semi-information agnostic, that means that whereas the output size is just not identified a priori, the enter size is thought. That is the principle distinction between LLM inference and the standard state of affairs. The enter size determines the execution time to create the preliminary output token, which could take for much longer than these of the next tokens due to the autoregressive sample of LLM inference.
The preliminary output token’s execution time takes up a lot of the work when the enter is prolonged and the output is temporary. They use this high quality so as to add skip-join to the standard MLFQ. Every arrival activity joins an acceptable queue by evaluating the execution time of the primary output token with the demotion thresholds of the strains, versus all the time getting into the best precedence queue. The upper precedence queues than the joined queue are bypassed to attenuate downgrades. Preemptive scheduling with MLFQ provides further reminiscence overhead to maintain begun however incomplete jobs in an interim state. LLMs preserve a key-value cache for every Transformer layer to retailer the intermediate state. So long as the batch measurement is just not exceeded, the FCFS cache must retailer the scheduled jobs’ intermediate states. Nevertheless, further jobs might have begun in MLFQ, however they’re relegated to queues with lesser priorities. All begun however incomplete jobs in MLFQ will need to have the interim state maintained by the cache. Given the scale of LLMs and the restricted reminiscence area of GPUs, the cache might overflow. When the cache is full, the scheduler naively can delay initiating new jobs, however this as soon as extra creates head-of-line blocking.
As a substitute, they develop a productive GPU reminiscence administration system that proactively uploads the state of processes in low-priority queues when they’re scheduled and offloads the state when the cache is sort of full. To extend effectivity, they make use of pipelining and asynchronous reminiscence operations. FastServe makes use of parallelization methods like tensor and pipeline parallelism to offer distributed inference serving with many GPUs for big fashions that don’t slot in one GPU. To scale back pipeline bubbles, the scheduler performs quite a few batches of jobs concurrently. A distributed key-value cache is organized by the key-value cache supervisor, which additionally distributes the administration of reminiscence swapping between GPU and host reminiscence. They put into follow a FastServe system prototype based mostly on NVIDIA FasterTransformer.The outcomes reveal that FastServe enhances the typical and tail JCT by as much as 5.1 and 6.4, respectively, in comparison with the cutting-edge answer Orca.
Take a look at the Paper. Don’t neglect to affix our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. When you’ve got any questions relating to the above article or if we missed something, be happy to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with individuals and collaborate on fascinating tasks.




