On Privateness and Personalization in Federated Studying: A Retrospective on the US/UK PETs Problem – Machine Studying Weblog | ML@CMU
TL;DR: We research using differential privateness in personalised, cross-silo federated studying (NeurIPS’22), clarify how these insights led us to develop a 1st place resolution within the US/UK Privacy-Enhancing Technologies (PETs) Prize Challenge, and share challenges and classes realized alongside the best way. If you’re feeling adventurous, checkout the extended version of this post with extra technical particulars!
How can we be higher ready for the following pandemic?
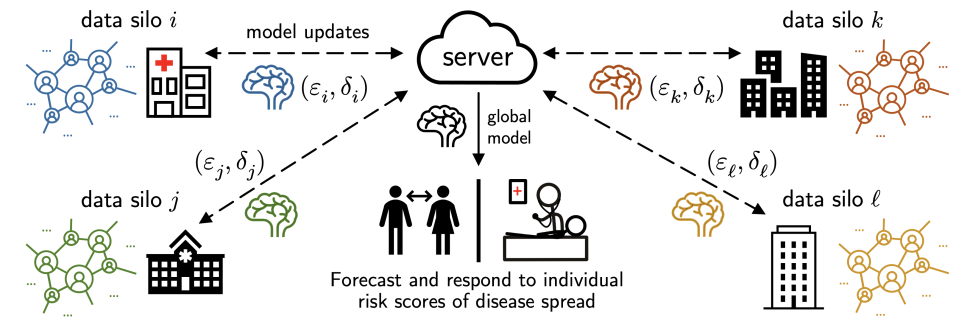
Affected person information collected by teams resembling hospitals and well being businesses is a crucial instrument for monitoring and stopping the unfold of illness. Sadly, whereas this information accommodates a wealth of helpful data for illness forecasting, the information itself could also be extremely delicate and saved in disparate areas (e.g., throughout a number of hospitals, well being businesses, and districts).
On this submit we talk about our analysis on federated learning, which goals to sort out this problem by performing decentralized studying throughout personal information silos. We then discover an utility of our analysis to the issue of privacy-preserving pandemic forecasting—a state of affairs the place we not too long ago received a 1st place, $100k prize in a competition hosted by the US & UK governments—and finish by discussing a number of instructions of future work primarily based on our experiences.
Half 1: Privateness, Personalization, and Cross-Silo Federated Studying
Federated studying (FL) is a method to coach fashions utilizing decentralized information with out straight speaking such information. Sometimes:
- a central server sends a mannequin to collaborating purchasers;
- the purchasers practice that mannequin utilizing their very own native information and ship again up to date fashions; and
- the server aggregates the updates (e.g., through averaging, as in FedAvg)
and the cycle repeats. Corporations like Apple and Google have deployed FL to coach fashions for purposes resembling predictive keyboards, text selection, and speaker verification in networks of person units.
Nonetheless, whereas vital consideration has been given to cross-device FL (e.g., studying throughout massive networks of units resembling cellphones), the world of cross-silo FL (e.g., studying throughout a handful of knowledge silos resembling hospitals or monetary establishments) is comparatively under-explored, and it presents attention-grabbing challenges when it comes to the right way to greatest mannequin federated information and mitigate privateness dangers. In Half 1.1, we’ll look at an appropriate privateness granularity for such settings, and in Half 1.2, we’ll see how this interfaces with mannequin personalization, an vital approach in dealing with information heterogeneity throughout purchasers.
1.1. How ought to we defend privateness in cross-silo federated studying?
Though the high-level federated studying workflow described above will help to mitigate systemic privateness dangers, past work means that FL’s information minimization precept alone isn’t enough for information privateness, because the consumer fashions and updates can nonetheless reveal delicate data.
That is the place differential privateness (DP) can come in useful. DP offers each a proper assure and an efficient empirical mitigation to assaults like membership inference and data poisoning. In a nutshell, DP is a statistical notion of privateness the place we add randomness to a question on a “dataset” to create quantifiable uncertainty about whether or not anyone “information level” has contributed to the question output. DP is often measured by two scalars ((varepsilon, delta))—the smaller, the extra personal.
Within the above, “dataset” and “information level” are in quotes as a result of privateness granularity issues. In cross-device FL, it is not uncommon to use “client-level DP” when coaching a mannequin, the place the federated purchasers (e.g., cellphones) are regarded as “information factors”. This successfully ensures that every collaborating consumer/cell phone person stays personal.
Nonetheless, whereas client-level DP is smart for cross-device FL as every consumer naturally corresponds to an individual, this privateness granularity might not be appropriate for cross-silo FL, the place there are fewer (2-100) ‘purchasers’ however every holds many information topics that require safety, e.g., every ‘consumer’ could also be a hospital, financial institution, or faculty with many affected person, buyer, or pupil information.
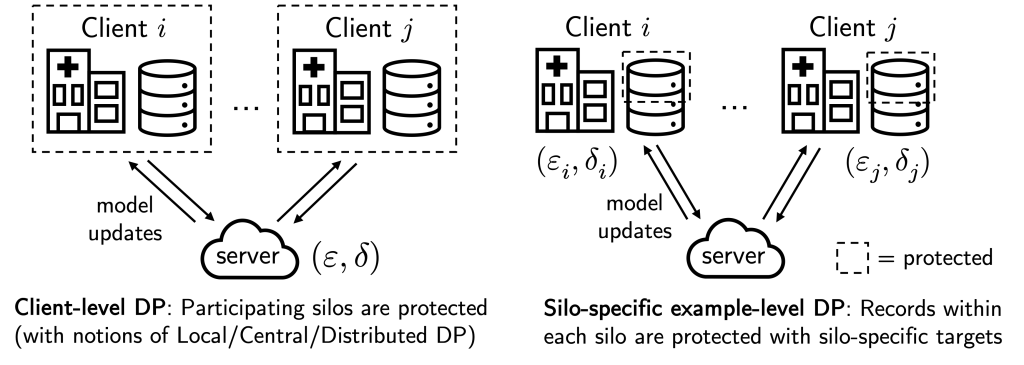
In our latest work (NeurIPS’22), we as an alternative contemplate the notion of “silo-specific example-level DP” in cross-silo FL (see determine above). Briefly, this says that the (okay)-th information silo could set its personal ((varepsilon_k, delta_k)) example-level DP goal for any studying algorithm with respect to its native dataset.
This notion is healthier aligned with real-world use circumstances of cross-silo FL, the place every information topic contributes a single “instance”, e.g., every affected person in a hospital contributes their particular person medical document. It is usually very straightforward to implement: every silo can simply run DP-SGD for native gradient steps with calibrated per-step noise. As we talk about beneath, this alternate privateness granularity impacts how we contemplate modeling federated information to enhance privateness/utility trade-offs.
1.2. The interaction of privateness, heterogeneity, and mannequin personalization
Let’s now take a look at how this privateness granularity could interface with mannequin personalization in federated studying.
Mannequin personalization is a standard approach used to enhance mannequin efficiency in FL when information heterogeneity (i.e. non-identically distributed information) exists between information silos. Certainly, existing benchmarks counsel that practical federated datasets could also be extremely heterogeneous and that becoming separate native fashions on the federated information are already aggressive baselines.
When contemplating mannequin personalization methods beneath silo-specific example-level privateness, we discover {that a} distinctive trade-off could emerge between the utility prices from privateness and information heterogeneity (see determine beneath):
- As DP noises are added independently by every silo for its personal privateness targets, these noises are mirrored within the silos’ mannequin updates and may thus be smoothed out when these updates are averaged (e.g. through FedAvg), resulting in a smaller utility drop from DP for the federated mannequin.
- Alternatively, federation additionally signifies that the shared, federated mannequin could undergo from information heterogeneity (“one dimension does not match all”).
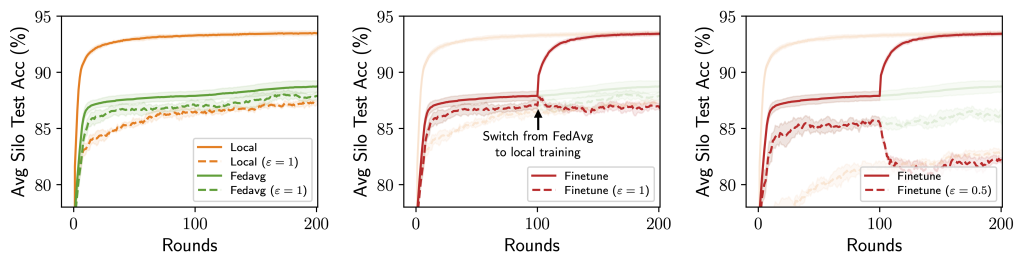
This “privacy-heterogeneity value tradeoff” is attention-grabbing as a result of it means that mannequin personalization can play a key and distinct function in cross-silo FL. Intuitively, native coaching (no FL participation) and FedAvg (full FL participation) might be considered as two ends of a personalization spectrum with an identical privateness prices—silos’ participation in FL itself doesn’t incur privateness prices resulting from DP’s robustness to post-processing—and numerous personalization algorithms (finetuning, clustering, …) are successfully navigating this spectrum in numerous methods.
If native coaching minimizes the impact of knowledge heterogeneity however enjoys no DP noise discount, and contrarily for FedAvg, it’s pure to wonder if there are personalization strategies that lie in between and obtain higher utility. In that case, what strategies would work greatest?
Our evaluation factors to mean-regularized multi-task studying (MR-MTL) as a easy but notably appropriate type of personalization. MR-MTL merely asks every consumer (okay) to coach its personal native mannequin (w_k), regularize it in the direction of the imply of others’ fashions (bar w) through a penalty (fraclambda 2 | w_k – bar w |_2^2 ), and preserve (w_k) throughout rounds (i.e. consumer is stateful). The imply mannequin (bar w) is maintained by the FL server (as in FedAvg) and could also be up to date in each spherical. Extra concretely, every native replace step takes the next type:
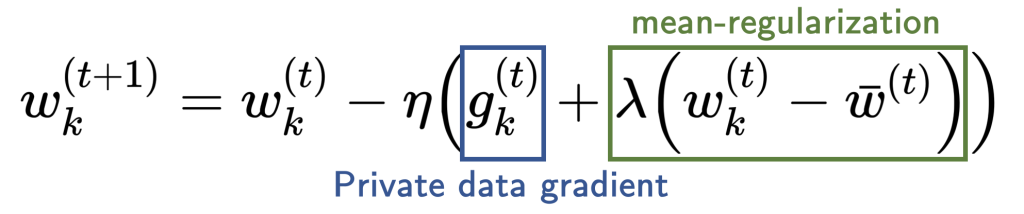
The hyperparameter (lambda) serves as a clean knob between native coaching and FedAvg: (lambda = 0) recovers native coaching, and a bigger (lambda) forces the personalised fashions to be nearer to one another (intuitively, “federate extra”).
MR-MTL has some good properties within the context of personal cross-silo FL:
- Noise discount is attained all through coaching through the mushy proximity constraint in the direction of an averaged mannequin;
- The mean-regularization itself has no privateness overhead; and
- (lambda) offers a clean interpolation alongside the personalization spectrum.
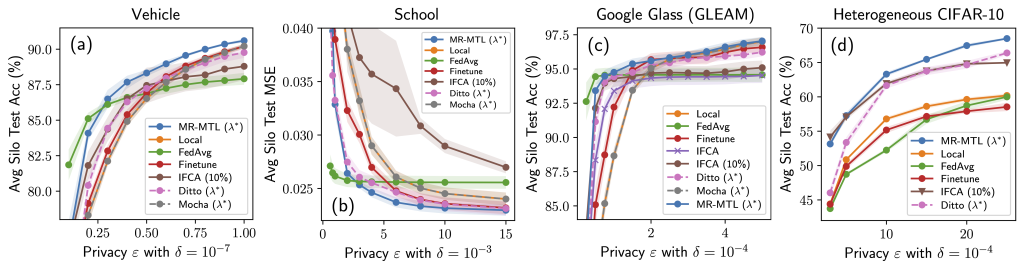
Why is the above attention-grabbing? Contemplate the next experiment the place we attempt a spread of (lambda) values roughly interpolating native coaching and FedAvg. Observe that we may discover a “candy spot” (lambda^ast) that outperforms each of the endpoints beneath the identical privateness value. Furthermore, each the utility benefit of MR-MTL((lambda^ast)) over the endpoints, and (lambda^ast) itself, are bigger beneath privateness; intuitively, this says that silos are inspired to “federate extra” for noise discount.
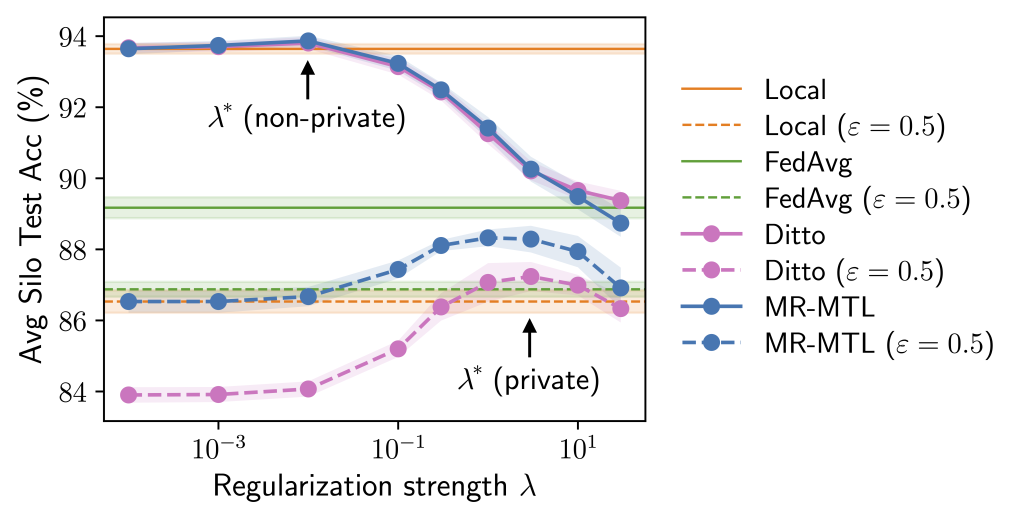
The above offers tough instinct on why MR-MTL could also be a powerful baseline for personal cross-silo FL and motivates this method for a sensible pandemic forecasting drawback, which we talk about in Half 2. Our full paper delves deeper into the analyses and offers extra outcomes and discussions!
Half 2: Federated Pandemic Forecasting on the US/UK PETs Problem
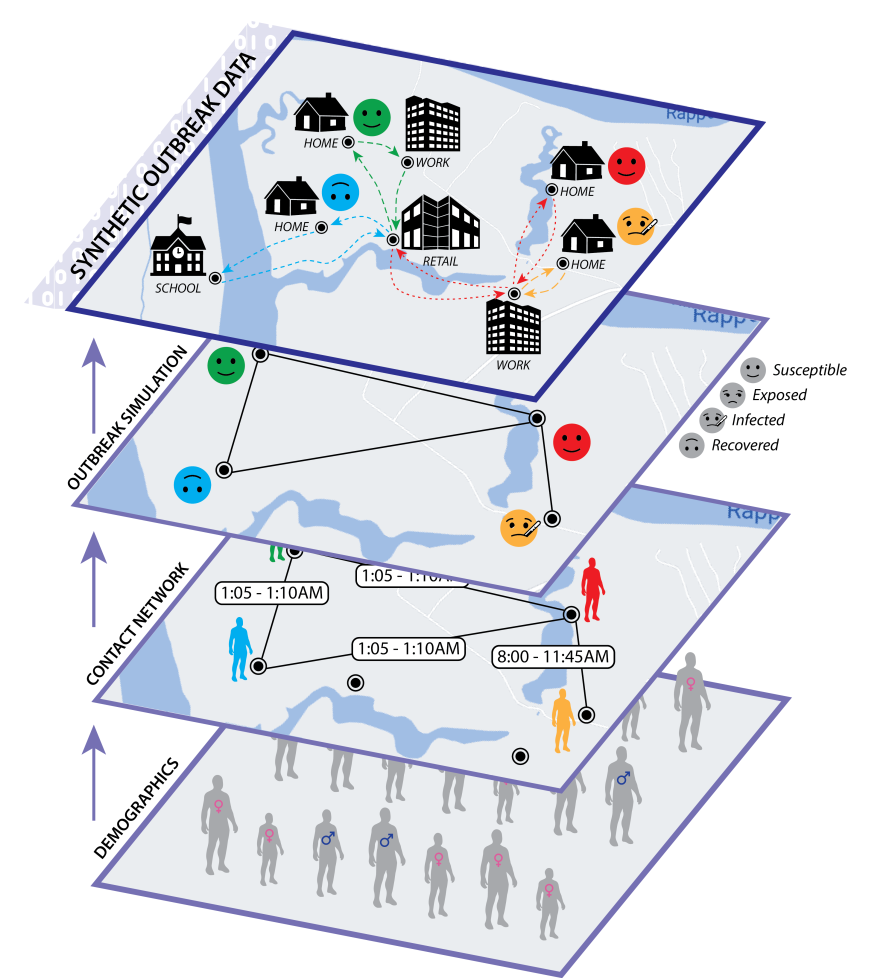
Let’s now check out a federated pandemic forecasting drawback on the US/UK Privacy-Enhancing Technologies (PETs) prize challenge, and the way we could apply the concepts from Half 1.
2.1. Downside setup
The pandemic forecasting drawback asks the next: Given an individual’s demographic attributes (e.g. age, family dimension), areas, actions, an infection historical past, and the contact community, what’s the chance of an infection within the subsequent (t_text{pred}=7) days? Can we make predictions whereas defending the privateness of people? Furthermore, what if the information are siloed throughout administrative areas?
There’s loads to unpack within the above. First, the pandemic outbreak drawback follows a discrete-time SIR model (Susceptible → Infectious → Recovered) and we start with a subset of the inhabitants contaminated. Subsequently,
- Every individual goes about their normal each day actions and will get into contact with others (e.g. at a shopping center)—this types a contact graph the place people are nodes and direct contacts are edges;
- Every individual could get contaminated with completely different threat ranges relying on a myriad of things—their age, the character and period of their contact(s), their node centrality, and so on.; and
- Such an infection may also be asymptomatic—the person can seem within the S state whereas being secretly infectious.
The challenge dataset fashions a pandemic outbreak in Virginia and accommodates roughly 7.7 million nodes (individuals) and 186 million edges (contacts) with well being states over 63 days; so the precise contact graph is pretty massive but in addition fairly sparse.
There are a couple of additional components that make this drawback difficult:
- Knowledge imbalance: lower than 5% of individuals are ever within the I or R state and roughly 0.3% of individuals grew to become contaminated within the closing week.
- Knowledge silos: the true contact graph is minimize alongside administrative boundaries, e.g., by grouped FIPS codes/counties. Every silo solely sees an area subgraph, however individuals should still journey and make contacts throughout a number of areas! in Within the official analysis, the inhabitants sizes can even differ by greater than 10(instances) throughout silos.
- Temporal modeling: we’re given the primary (t_text{practice} = 56) days of every individual’s well being states (S/I/R) and requested to foretell particular person infections any time within the subsequent ( t_text{pred} = 7 ) days. What’s a coaching instance on this case? How ought to we carry out temporal partitioning? How does this relate to privateness accounting?
- Graphs usually complicate DP: we are sometimes used to ML settings the place we will clearly outline the privateness granularity and the way it pertains to an precise particular person (e.g. medical photographs of sufferers). That is tough with graphs: individuals could make completely different numbers of contacts every of various natures, and their affect can propagate all through the graph. At a excessive stage (and as specified by the scope of sensitive data of the competition), what we care about is named node-level DP—the mannequin output is “roughly the identical” if we add/take away/change a node, together with its edges.
2.2. Making use of MR-MTL with silo-specific example-level privateness
One clear method to the pandemic forecasting drawback is to simply function on the particular person stage and think about it as (federated) binary classification: if we may construct a function vector to summarize a person, then threat scores are merely the sigmoid possibilities of near-term an infection.
After all, the issue lies in what that function vector (and the corresponding label) is—we’ll get to this within the following part. However already, we will see that MR-MTL with silo-specific example-level privateness (from Half 1) is a pleasant framework for quite a lot of causes:
- Mannequin personalization is probably going wanted because the silos are massive and heterogeneous by building (geographic areas are not like to all be related).
- Privateness definition: There are a small variety of purchasers, however every holds many information topics, and client-level DP isn’t appropriate.
- Usability, effectivity, and scalability: MR-MTL is remarkably straightforward to implement with minimal useful resource overhead (over FedAvg and native coaching). That is essential for real-world purposes.
- Adaptability and explainability: The framework is extremely adaptable to any studying algorithm that may take DP-SGD-style updates. It additionally preserves the explainability of the underlying ML algorithm as we don’t obfuscate the mannequin weights, updates, or predictions.
It is usually useful to have a look at the risk mannequin we is perhaps coping with and the way our framework behaves beneath it; the reader could discover extra particulars within the extended post!
2.3. Constructing coaching examples
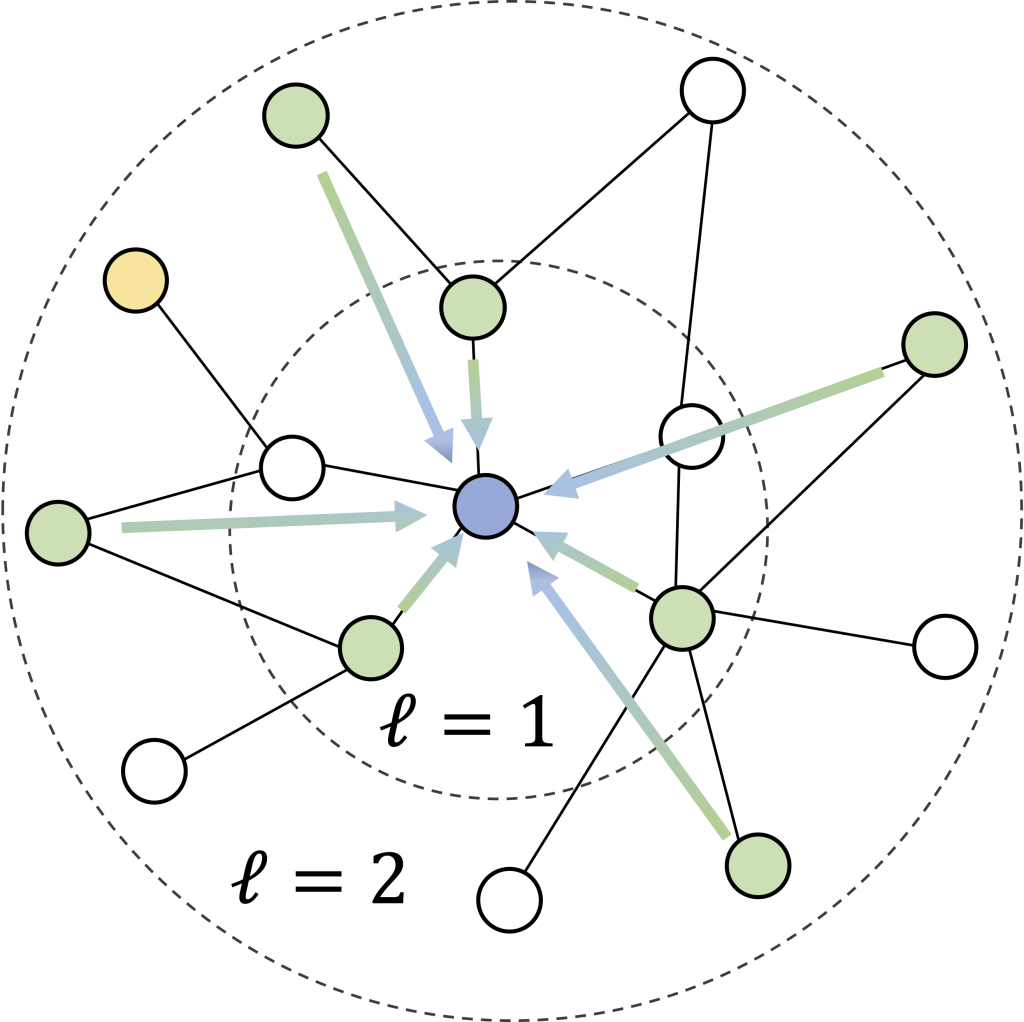
We now describe the right way to convert particular person data and the contact community right into a tabular dataset for each silo ( okay ) with ( n_k ) nodes.
Recall that our process is to foretell the chance of an infection of an individual inside ( t_text{pred} = 7) days, and that every silo solely sees its native subgraph. We formulate this through a silo-specific set of examples ( ( X_k in mathbb R^{n_k instances d}, Y_k in mathbb {0, 1}^{n_k} ) ), the place the options ( {X_k^{(i)} in mathbb R^d} ) describe the neighborhood round an individual ( i ) (see determine) and binary label ( {Y_k^{(i)}} ) denotes if the individual turn into contaminated within the subsequent ( t_text{pred} ) days.
Every instance’s options ( X_k^{(i)} ) encompass the next:
(1) Particular person options: Primary (normalized) demographic options like age, gender, and family dimension; exercise options like working, faculty, going to church, or procuring; and the person’s an infection historical past as concatenated one-hot vectors (which is determined by how we create labels; see beneath).
(2) Contact options: Certainly one of our key simplifying heuristics is that every node’s (ell)-hop neighborhood ought to comprise a lot of the data we have to predict an infection. We construct the contact options as follows:
- Each sampled neighbor (v) of a node (u) is encoded utilizing its particular person options (as above) together with the edge options describing the contact—e.g. the placement, the period, and the exercise sort.
- We use iterative neighborhood sampling (determine above), which means that we first choose a set of ( S_1 ) 1-hop neighbors, after which pattern (S_2) 2-hop neighbors adjoining to these 1-hop neighbors, and so forth. This permits reusing 1-hop edge options and retains the function dimension (d) low.
- We additionally used deterministic neighborhood sampling—the identical individual at all times takes the identical subset of neighbors. This drastically reduces computation because the graph/neighborhoods can now be cached. For the reader, this additionally has implications on privacy accounting.

The determine above illustrates the neighborhood function vector that describes an individual and their contacts for the binary classifier! Intriguingly, this makes the per-silo fashions a simplified variant of a graph neural community (GNN) with a single-step, non-parameterized neighborhood aggregation and prediction (cf. SGC models).
For the labels ( Y_k^{(i)} ), we deployed a random an infection window technique:
- Decide a window dimension ( t_text{window} ) (say 21 days);
- Choose a random day (t’) inside the legitimate vary ((t_text{window} le t’ le t_text{practice} – t_text{pred}));
- Encode the S/I/R states up to now window from (t’) for each node within the neighborhood as particular person options;
- The label is then whether or not individual (i) is contaminated in any of the following (t_text{pred}) days from (t’).
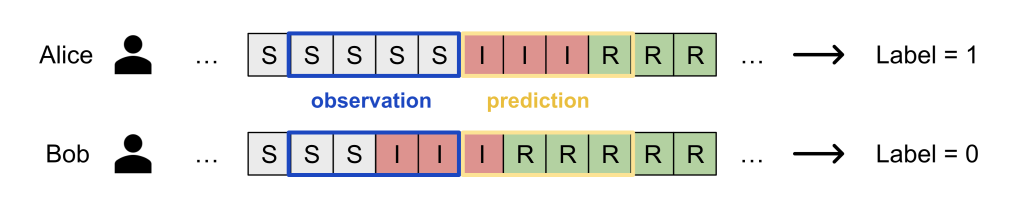
Our technique implicitly assumes that an individual’s an infection threat is particular person: whether or not Bob will get contaminated relies upon solely on his personal actions and contacts up to now window. That is actually not good because it ignores population-level modeling (e.g. denser areas have greater dangers of an infection), nevertheless it makes the ML drawback quite simple: simply plug-in current tabular information modeling approaches!
2.4. Placing all of it collectively
We are able to now see our resolution coming collectively: every silo builds a tabular dataset utilizing neighborhood vectors for options and an infection home windows for labels, and every silo trains a personalised binary classifier beneath MR-MTL with silo-specific example-level privateness. We full our methodology with a couple of extra elements:
- Privateness accounting. We’ve to date glossed over what silo-specific “example-level” DP truly means for a person. We’ve put extra particulars in the extended blog post, and the primary thought is that native DP-SGD can provide “neighborhood-level” DP since every node’s enclosing neighborhood is fastened and distinctive, and we will then convert it to node-level DP (our privateness aim from Half 2.1) by rigorously accounting for how a sure node could seem in different nodes’ neighborhoods.
- Noisy SGD as an empirical protection. Whereas we have now a whole framework for offering silo-specific node-level DP ensures, for the PETs problem particularly we determined to go for weak DP ((varepsilon > 500)) as an empirical safety, somewhat than a rigorous theoretical assure. Whereas some readers could discover this mildly disturbing at first look, we word that the power of safety is determined by the information, the fashions, the precise threats, the specified privacy-utility trade-off, and several other essential components linking concept and apply which we define within the extended blog. Our resolution was in flip attacked by a number of red teams to check for vulnerabilities.
- Mannequin structure: easy is sweet. Whereas the mannequin design area is massive, we’re enthusiastic about strategies amenable to gradient-based personal optimization (e.g. DP-SGD) and weight-space averaging for federated studying. We in contrast easy logistic regression and a 3-layer MLP and located that the variance in information strongly favors linear fashions, which even have advantages in privateness (when it comes to restricted capability for memorization) in addition to explainability, effectivity, and robustness.
- Computation-utility tradeoff for neighborhood sampling. Whereas bigger neighborhood sizes (S) and extra hops (ell) higher seize the unique contact graph, additionally they blow up the computation and our experiments discovered that bigger (S) and (ell) are inclined to have diminishing returns.
- Knowledge imbalance and weighted loss. As a result of the information are extremely imbalanced, coaching naively will undergo from low recall and AUPRC. Whereas there are established over-/under-sampling methods to take care of such imbalance, they, sadly, make privacy accounting loads trickier when it comes to the subsampling assumption or the elevated information queries. We leveraged the focal loss from the pc imaginative and prescient literature designed to emphasise laborious examples (contaminated circumstances) and located that it did enhance each the AUPRC and the recall significantly.
The above captures the essence of our entry to the problem. Regardless of the numerous subtleties in absolutely constructing out a working system, the primary concepts had been fairly easy: practice personalised fashions with DP and add some proximity constraints!
Takeaways and Open Challenges
In Half 1, we reviewed our NeurIPS’22 paper that studied the appliance of differential privateness in cross-silo federated studying situations, and in Half 2, we noticed how the core concepts and strategies from the paper helped us develop our submission to the PETs prize problem and win a 1st place within the pandemic forecasting monitor. For readers enthusiastic about extra particulars—resembling theoretical analyses, hyperparameter tuning, additional experiments, and failure modes—please take a look at our full paper. Our work additionally recognized a number of vital future instructions on this context:
DP beneath information imbalance. DP is inherently a uniform assure, however information imbalance implies that examples are not created equal—minority examples (e.g., illness an infection, bank card fraud) are extra informative, and so they have a tendency to provide off (a lot) bigger gradients throughout mannequin coaching. Ought to we as an alternative do class-specific (group-wise) DP or refine “heterogeneous DP” or “outlier DP” notions to higher cater to the discrepancy between information factors?
Graphs and privateness. One other basic foundation of DP is that we may delineate what’s and isn’t an particular person. However as we’ve seen, the data boundaries are sometimes nebulous when a person is a node in a graph (assume social networks and gossip propagation), notably when the node is arbitrarily properly related. As a substitute of getting inflexible constraints (e.g., imposing a max node diploma and accounting for it), are there different privateness definitions that provide various levels of safety for various node connectedness?
Scalable, personal, and federated timber for tabular information. Choice timber/forests are inclined to work extraordinarily properly for tabular information resembling ours, even with information imbalance, however regardless of recent progress, we argue that they aren’t but mature beneath personal and federated settings resulting from some underlying assumptions.
Novel coaching frameworks. Whereas MR-MTL is a straightforward and powerful baseline beneath our privateness granularity, it has clear limitations when it comes to modeling capability. Are there different strategies that may additionally present related properties to stability the rising privacy-heterogeneity value tradeoff?
Sincere privateness value of hyperparameter search. When looking for higher frameworks, the dependence on hyperparameters is especially attention-grabbing: our full paper (section 7) made a stunning however considerably miserable statement that the trustworthy privateness value of simply tuning (on common) 10 configurations (values of (lambda) on this case) could already outweigh the utility benefit of one of the best tune MR-MTL((lambda^ast)). What does this imply if MR-MTL is already a powerful baseline with only a single hyperparameter?
Try the next associated hyperlinks:
DISCLAIMER: All opinions expressed on this submit are these of the authors and don’t symbolize the views of CMU.




