Internet hosting ML Fashions on Amazon SageMaker utilizing Triton: XGBoost, LightGBM, and Treelite Fashions

One of the vital in style fashions obtainable in the present day is XGBoost. With the flexibility to unravel numerous issues corresponding to classification and regression, XGBoost has turn into a preferred possibility that additionally falls into the class of tree-based fashions. On this publish, we dive deep to see how Amazon SageMaker can serve these fashions utilizing NVIDIA Triton Inference Server. Actual-time inference workloads can have various ranges of necessities and repair stage agreements (SLAs) when it comes to latency and throughput, and could be met utilizing SageMaker real-time endpoints.
SageMaker offers single model endpoints, which let you deploy a single machine studying (ML) mannequin towards a logical endpoint. For different use instances, you possibly can select to handle value and efficiency utilizing multi-model endpoints, which let you specify a number of fashions to host behind a logical endpoint. Whatever the possibility the you select, SageMaker endpoints enable a scalable mechanism for even probably the most demanding enterprise prospects whereas offering worth in a plethora of options, together with shadow variants, auto scaling, and native integration with Amazon CloudWatch (for extra data, seek advice from CloudWatch Metrics for Multi-Model Endpoint Deployments).
Triton helps numerous backends as engines to help the operating and serving of assorted ML fashions for inference. For any Triton deployment, it’s essential to know the way the backend habits impacts your workloads and what to anticipate so that you could achieve success. On this publish, we allow you to perceive the Forest Inference Library (FIL) backend, which is supported by Triton on SageMaker, so that you could make an knowledgeable determination on your workloads and get the very best efficiency and price optimization doable.
Deep dive into the FIL backend
Triton helps the FIL backend to serve tree fashions, corresponding to XGBoost, LightGBM, scikit-learn Random Forest, RAPIDS cuML Random Forest, and every other mannequin supported by Treelite. These fashions have lengthy been used for fixing issues corresponding to classification or regression. Though these kind of fashions have historically run on CPUs, the recognition of those fashions and inference calls for have led to numerous methods to extend inference efficiency. The FIL backend makes use of many of those methods by utilizing cuML constructs and is constructed on C++ and the CUDA core library to optimize inference efficiency on GPU accelerators.
The FIL backend makes use of cuML’s libraries to make use of CPU or GPU cores to speed up studying. With a view to use these processors, information is referenced from host reminiscence (for instance, NumPy arrays) or GPU arrays (uDF, Numba, cuPY, or any library that helps the __cuda_array_interface__) API. After the info is staged in reminiscence, the FIL backend can run processing throughout all of the obtainable CPU or GPU cores.
The FIL backend threads can talk with one another with out using shared reminiscence of the host, however in ensemble workloads, host reminiscence must be thought-about. The next diagram reveals an ensemble scheduler runtime structure the place you will have the flexibility to fine-tune the reminiscence areas, together with CPU addressable shared reminiscence that’s used for inter-process communication between Triton (C++) and the Python course of (Python backend) for exchanging tensors (enter/output) with the FIL backend.
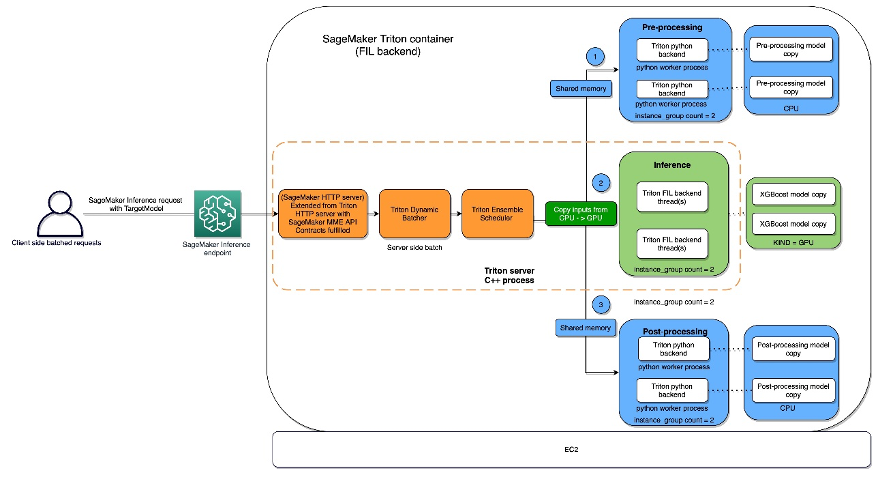
Triton Inference Server offers configurable choices for builders to tune their workloads and optimize mannequin efficiency. The configuration dynamic_batching permits Triton to carry client-side requests and batch them on the server aspect in an effort to effectively use FIL’s parallel computation to inference your complete batch collectively. The choice max_queue_delay_microseconds gives a fail-safe management of how lengthy Triton waits to kind a batch.
There are a variety of different FIL-specific options available that impression efficiency and habits. We advise beginning with storage_type. When operating the backend on GPU, FIL creates a brand new reminiscence/information construction that could be a illustration of the tree for which FIL can impression efficiency and footprint. That is configurable by way of the setting parameter storage_type, which has the choices dense, sparse, and auto. Selecting the dense possibility will eat extra GPU reminiscence and doesn’t all the time lead to higher efficiency, so it’s greatest to examine. In distinction, the sparse possibility will eat much less GPU reminiscence and may presumably carry out as effectively or higher than dense. Selecting auto will trigger the mannequin to default to dense except doing so will eat considerably extra GPU reminiscence than sparse.
On the subject of mannequin efficiency, you may take into account emphasizing the threads_per_tree possibility. One factor that you could be overserve in real-world eventualities is that threads_per_tree can have a much bigger impression on throughput than every other parameter. Setting it to any energy of two from 1–32 is professional. The optimum worth is tough to foretell for this parameter, however when the server is anticipated to take care of greater load or course of bigger batch sizes, it tends to profit from a bigger worth than when it’s processing a couple of rows at a time.
One other parameter to pay attention to is algo, which can be obtainable for those who’re operating on GPU. This parameter determines the algorithm that’s used to course of the inference requests. The choices supported for this are ALGO_AUTO, NAIVE, TREE_REORG, and BATCH_TREE_REORG. These choices decide how nodes inside a tree are organized and may lead to efficiency beneficial properties. The ALGO_AUTO possibility defaults to NAIVE for sparse storage and BATCH_TREE_REORG for dense storage.
Lastly, FIL comes with Shapley explainer, which could be activated by utilizing the treeshap_output parameter. Nonetheless, it’s best to remember the fact that Shapley outputs damage efficiency attributable to its output measurement.
Mannequin format
There may be at the moment no normal file format to retailer forest-based fashions; each framework tends to outline its personal format. With a view to help a number of enter file codecs, FIL imports information utilizing the open-source Treelite library. This permits FIL to help fashions educated in in style frameworks, corresponding to XGBoost and LightGBM. Notice that the format of the mannequin that you just’re offering should be set within the model_type configuration worth specified within the config.pbtxt file.
Config.pbtxt
Every mannequin in a model repository should embody a mannequin configuration that gives the required and non-compulsory details about the mannequin. Sometimes, this configuration is supplied in a config.pbtxt file specified as ModelConfig protobuf. To study extra concerning the config settings, seek advice from Model Configuration. The next are a few of the mannequin configuration parameters:
- max_batch_size – This determines the utmost batch measurement that may be handed to this mannequin. On the whole, the one restrict on the dimensions of batches handed to a FIL backend is the reminiscence obtainable with which to course of them. For GPU runs, the obtainable reminiscence is decided by the dimensions of Triton’s CUDA reminiscence pool, which could be set by way of a command line argument when beginning the server.
- enter – Choices on this part inform Triton the variety of options to anticipate for every enter pattern.
- output – Choices on this part inform Triton what number of output values there can be for every pattern. If the
predict_probapossibility is about to true, then a chance worth can be returned for every class. In any other case, a single worth can be returned, indicating the category predicted for the given pattern. - instance_group – This determines what number of cases of this mannequin can be created and whether or not they are going to use GPU or CPU.
- model_type – This string signifies what format the mannequin is in (
xgboost_jsonon this instance, howeverxgboost,lightgbm, andtl_checkpointare legitimate codecs as effectively). - predict_proba – If set to true, chance values can be returned for every class slightly than only a class prediction.
- output_class – That is set to true for classification fashions and false for regression fashions.
- threshold – It is a rating threshold for figuring out classification. When
output_classis about to true, this should be supplied, though it received’t be used ifpredict_probacan be set to true. - storage_type – On the whole, utilizing AUTO for this setting ought to meet most use instances. If AUTO storage is chosen, FIL will load the mannequin utilizing both a sparse or dense illustration based mostly on the approximate measurement of the mannequin. In some instances, you might need to explicitly set this to SPARSE in an effort to scale back the reminiscence footprint of huge fashions.
Triton Inference Server on SageMaker
SageMaker allows you to deploy each single mannequin and multi-model endpoints with NVIDIA Triton Inference Server. The next determine reveals the Triton Inference Server high-level structure. The model repository is a file system-based repository of the fashions that Triton will make obtainable for inferencing. Inference requests arrive on the server and are routed to the suitable per-model scheduler. Triton implements multiple scheduling and batching algorithms that may be configured on a model-by-model foundation. Every mannequin’s scheduler optionally performs batching of inference requests after which passes the requests to the backend equivalent to the mannequin sort. The backend performs inferencing utilizing the inputs supplied within the batched requests to provide the requested outputs. The outputs are then returned.
When configuring your auto scaling teams for SageMaker endpoints, you might need to take into account SageMakerVariantInvocationsPerInstance as the first standards to find out the scaling traits of your auto scaling group. As well as, relying on whether or not your fashions are operating on GPU or CPU, you may additionally think about using CPUUtilization or GPUUtilization as further standards. Notice that for single mannequin endpoints, as a result of the fashions deployed are all the identical, it’s pretty easy to set correct insurance policies to satisfy your SLAs. For multi-model endpoints, we suggest deploying related fashions behind a given endpoint to have extra regular predictable efficiency. In use instances the place fashions of various sizes and necessities are used, you might need to separate these workloads throughout a number of multi-model endpoints or spend a while fine-tuning your auto scaling group coverage to acquire the very best value and efficiency stability.
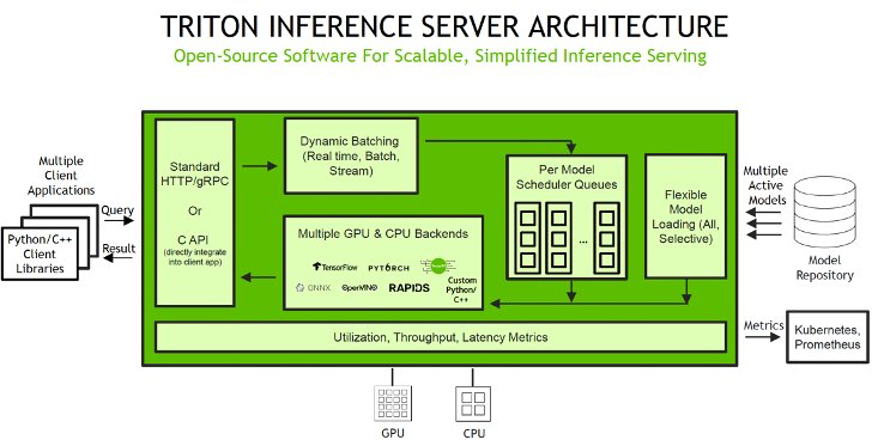
For an inventory of NVIDIA Triton Deep Studying Containers (DLCs) supported by SageMaker inference, seek advice from Available Deep Learning Containers Images.
SageMaker pocket book walkthrough
ML purposes are advanced and may typically require information preprocessing. On this pocket book, we dive into how one can deploy a tree-based ML mannequin like XGBoost utilizing the FIL backend in Triton on a SageMaker multi-model endpoint. We additionally cowl how one can implement a Python-based information preprocessing inference pipeline on your mannequin utilizing the ensemble function in Triton. It will enable us to ship within the uncooked information from the shopper aspect and have each information preprocessing and mannequin inference occur in a Triton SageMaker endpoint for optimum inference efficiency.
Triton mannequin ensemble function
Triton Inference Server drastically simplifies the deployment of AI fashions at scale in manufacturing. Triton Inference Server comes with a handy answer that simplifies constructing preprocessing and postprocessing pipelines. The Triton Inference Server platform offers the ensemble scheduler, which is liable for pipelining fashions taking part within the inference course of whereas making certain effectivity and optimizing throughput. Utilizing ensemble fashions can keep away from the overhead of transferring intermediate tensors and decrease the variety of requests that should be despatched to Triton.
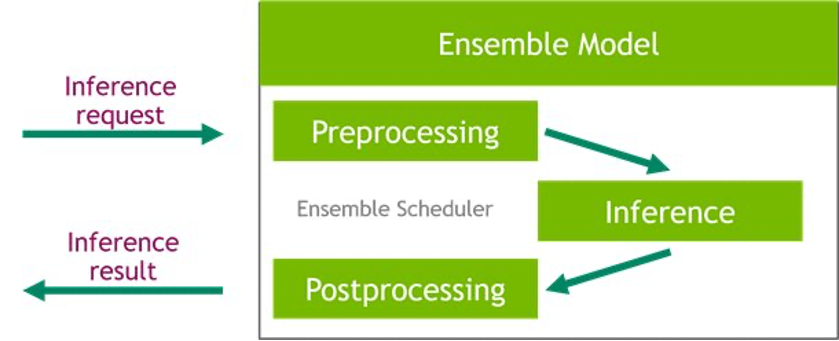
On this pocket book, we present how one can use the ensemble function for constructing a pipeline of knowledge preprocessing with XGBoost mannequin inference, and you’ll extrapolate from it so as to add customized postprocessing to the pipeline.
Arrange the setting
We start by organising the required setting. We set up the dependencies required to bundle our mannequin pipeline and run inferences utilizing Triton Inference Server. We additionally outline the AWS Identity and Access Management (IAM) position that can give SageMaker entry to the mannequin artifacts and the NVIDIA Triton Amazon Elastic Container Registry (Amazon ECR) picture. See the next code:
Create a Conda setting for preprocessing dependencies
The Python backend in Triton requires us to make use of a Conda setting for any further dependencies. On this case, we use the Python backend to preprocess the uncooked information earlier than feeding it into the XGBoost mannequin that’s operating within the FIL backend. Regardless that we initially used RAPIDS cuDF and cuML to do the info preprocessing, right here we use Pandas and scikit-learn as preprocessing dependencies throughout inference. We do that for 3 causes:
- We present how one can create a Conda setting on your dependencies and how one can bundle it within the format expected by Triton’s Python backend.
- By exhibiting the preprocessing mannequin operating within the Python backend on the CPU whereas the XGBoost runs on the GPU within the FIL backend, we illustrate how every mannequin in Triton’s ensemble pipeline can run on a distinct framework backend in addition to completely different {hardware} configurations.
- It highlights how the RAPIDS libraries (cuDF, cuML) are suitable with their CPU counterparts (Pandas, scikit-learn). For instance, we are able to present how
LabelEncoderscreated in cuML can be utilized in scikit-learn and vice versa.
We comply with the directions from the Triton documentation for packaging preprocessing dependencies (scikit-learn and Pandas) for use within the Python backend as a Conda setting TAR file. The bash script create_prep_env.sh creates the Conda setting TAR file, then we transfer it into the preprocessing mannequin listing. See the next code:
After we run the previous script, it generates preprocessing_env.tar.gz, which we copy to the preprocessing listing:
Arrange preprocessing with the Triton Python backend
For preprocessing, we use Triton’s Python backend to carry out tabular information preprocessing (categorical encoding) throughout inference for uncooked information requests coming into the server. For extra details about the preprocessing that was executed throughout coaching, seek advice from the training notebook.
The Python backend permits preprocessing, postprocessing, and every other customized logic to be carried out in Python and served with Triton. Utilizing Triton on SageMaker requires us to first arrange a mannequin repository folder containing the fashions we need to serve. We’ve already arrange a mannequin for Python information preprocessing referred to as preprocessing in cpu_model_repository and gpu_model_repository.
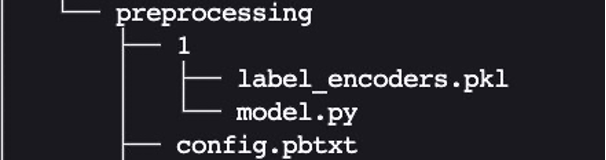
Triton has particular necessities for mannequin repository format. Inside the top-level mannequin repository listing, every mannequin has its personal subdirectory containing the knowledge for the corresponding mannequin. Every mannequin listing in Triton will need to have not less than one numeric subdirectory representing a model of the mannequin. The worth 1 represents model 1 of our Python preprocessing mannequin. Every mannequin is run by a particular backend, so inside every model subdirectory there should be the mannequin artifact required by that backend. For this instance, we use the Python backend, which requires the Python file you’re serving to be referred to as mannequin.py, and the file must implement certain functions. If we have been utilizing a PyTorch backend, a mannequin.pt file can be required, and so forth. For extra particulars on naming conventions for mannequin recordsdata, seek advice from Model Files.
The model.py Python file we use right here implements all of the tabular information preprocessing logic to transform uncooked information into options that may be fed into our XGBoost mannequin.
Each Triton mannequin should additionally present a config.pbtxt file describing the mannequin configuration. To study extra concerning the config settings, seek advice from Model Configuration. Our config.pbtxt file specifies the backend as python and all of the enter columns for uncooked information together with preprocessed output, which consists of 15 options. We additionally specify we need to run this Python preprocessing mannequin on the CPU. See the next code:
Arrange a tree-based ML mannequin for the FIL backend
Subsequent, we arrange the mannequin listing for a tree-based ML mannequin like XGBoost, which can be utilizing the FIL backend.
The anticipated format for cpu_memory_repository and gpu_memory_repository are much like the one we confirmed earlier.
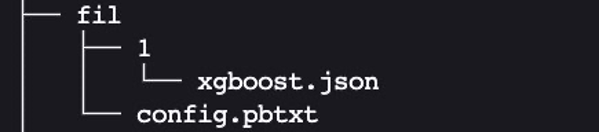
Right here, FIL is the title of the mannequin. We can provide it a distinct title like xgboost if we need to. 1 is the model subdirectory, which accommodates the mannequin artifact. On this case, it’s the xgboost.json mannequin that we saved. Let’s create this anticipated format:
We have to have the configuration file config.pbtxt describing the mannequin configuration for the tree-based ML mannequin, in order that the FIL backend in Triton can perceive how one can serve it. For extra data, seek advice from the newest generic Triton configuration options and the configuration choices particular to the FIL backend. We concentrate on just some of the commonest and related choices on this instance.
Create config.pbtxt for model_cpu_repository:
Equally, arrange config.pbtxt for model_gpu_repository (observe the distinction is USE_GPU = True):
Arrange an inference pipeline of the info preprocessing Python backend and FIL backend utilizing ensembles
Now we’re able to arrange the inference pipeline for information preprocessing and tree-based mannequin inference utilizing an ensemble model. An ensemble mannequin represents a pipeline of a number of fashions and the connection of enter and output tensors between these fashions. Right here we use the ensemble mannequin to construct a pipeline of knowledge preprocessing within the Python backend adopted by XGBoost within the FIL backend.
The anticipated format for the ensemble mannequin listing is much like those we confirmed beforehand:
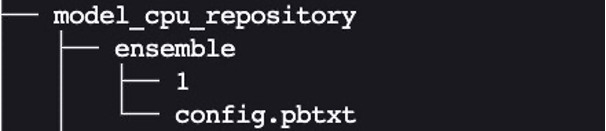
We created the ensemble mannequin’s config.pbtxt following the steering in Ensemble Models. Importantly, we have to arrange the ensemble scheduler in config.pbtxt, which specifies the info stream between fashions inside the ensemble. The ensemble scheduler collects the output tensors in every step, and offers them as enter tensors for different steps in line with the specification.
Bundle the mannequin repository and add to Amazon S3
Lastly, we find yourself with the next mannequin repository listing construction, containing a Python preprocessing mannequin and its dependencies together with the XGBoost FIL mannequin and the mannequin ensemble.
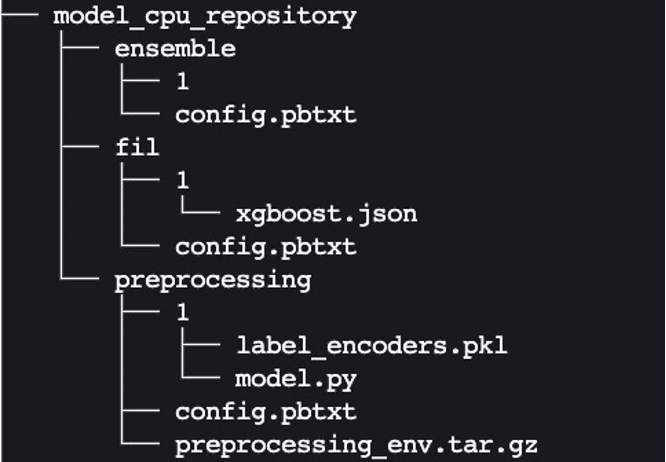
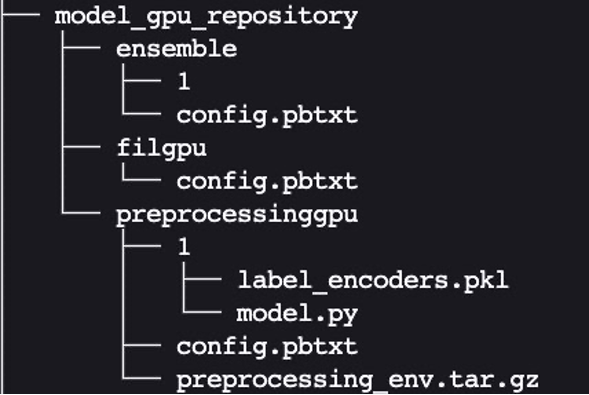
We bundle the listing and its contents as mannequin.tar.gz for importing to Amazon Simple Storage Service (Amazon S3). We’ve two choices on this instance: utilizing a CPU-based occasion or a GPU-based occasion. A GPU-based occasion is extra appropriate while you want greater processing energy and need to use CUDA cores.
Create and add the mannequin bundle for a CPU-based occasion (optimized for CPU) with the next code:
Create and add the mannequin bundle for a GPU-based occasion (optimized for GPU) with the next code:
Create a SageMaker endpoint
We now have the mannequin artifacts saved in an S3 bucket. On this step, we are able to additionally present the extra setting variable SAGEMAKER_TRITON_DEFAULT_MODEL_NAME, which specifies the title of the mannequin to be loaded by Triton. The worth of this key ought to match the folder title within the mannequin bundle uploaded to Amazon S3. This variable is non-compulsory within the case of a single mannequin. Within the case of ensemble fashions, this key needs to be specified for Triton to start out up in SageMaker.
Moreover, you possibly can set SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT and SAGEMAKER_TRITON_THREAD_COUNT for optimizing the thread counts.
We use the previous mannequin to create an endpoint configuration the place we are able to specify the kind and variety of cases we wish within the endpoint
We use this endpoint configuration to create a SageMaker endpoint and look forward to the deployment to complete. With SageMaker MMEs, we now have the choice to host a number of ensemble fashions by repeating this course of, however we stick to one deployment for this instance:
The standing will change to InService when the deployment is profitable.
Invoke your mannequin hosted on the SageMaker endpoint
After the endpoint is operating, we are able to use some pattern uncooked information to carry out inference utilizing JSON because the payload format. For the inference request format, Triton makes use of the KFServing neighborhood normal inference protocols. See the next code:
The pocket book referred within the weblog could be discovered within the GitHub repository.
Greatest practices
Along with the choices to fine-tune the settings of the FIL backend we talked about earlier, information scientists may be sure that the enter information for the backend is optimized for processing by the engine. At any time when doable, enter information in row-major format into the GPU array. Different codecs would require inner conversion and take up cycles, reducing efficiency.
Because of the means FIL information constructions are maintained in GPU reminiscence, be conscious of the tree depth. The deeper the tree depth, the bigger your GPU reminiscence footprint can be.
Use the instance_group_count parameter so as to add employee processes and enhance the throughput of the FIL backend, which is able to lead to bigger CPU and GPU reminiscence consumption. As well as, take into account SageMaker-specific variables which might be obtainable to extend the throughput, corresponding to HTTP threads, HTTP buffer measurement, batch measurement, and max delay.
Conclusion
On this publish, we dove deep into the FIL backend that Triton Inference Server helps on SageMaker. This backend offers for each CPU and GPU acceleration of your tree-based fashions corresponding to the favored XGBoost algorithm. There are lots of choices to think about to get the very best efficiency for inference, corresponding to batch sizes, information enter codecs, and different elements that may be tuned to satisfy your wants. SageMaker means that you can use this functionality with single and multi-model endpoints to stability of efficiency and price financial savings.
We encourage you to take the knowledge on this publish and see if SageMaker can meet your internet hosting must serve tree-based fashions, assembly your necessities for value discount and workload efficiency.
The pocket book referenced on this publish could be discovered within the SageMaker examples GitHub repository. Moreover, you could find the newest documentation on the FIL backend on GitHub.
In regards to the Authors
 Raghu Ramesha is an Senior ML Options Architect with the Amazon SageMaker Service crew. He focuses on serving to prospects construct, deploy, and migrate ML manufacturing workloads to SageMaker at scale. He focuses on machine studying, AI, and laptop imaginative and prescient domains, and holds a grasp’s diploma in Laptop Science from UT Dallas. In his free time, he enjoys touring and pictures.
Raghu Ramesha is an Senior ML Options Architect with the Amazon SageMaker Service crew. He focuses on serving to prospects construct, deploy, and migrate ML manufacturing workloads to SageMaker at scale. He focuses on machine studying, AI, and laptop imaginative and prescient domains, and holds a grasp’s diploma in Laptop Science from UT Dallas. In his free time, he enjoys touring and pictures.
 James Park is a Options Architect at Amazon Net Companies. He works with Amazon.com to design, construct, and deploy know-how options on AWS, and has a specific curiosity in AI and machine studying. In his spare time he enjoys looking for out new cultures, new experiences, and staying updated with the newest know-how tendencies.
James Park is a Options Architect at Amazon Net Companies. He works with Amazon.com to design, construct, and deploy know-how options on AWS, and has a specific curiosity in AI and machine studying. In his spare time he enjoys looking for out new cultures, new experiences, and staying updated with the newest know-how tendencies.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing and synthetic intelligence. He focuses on deep studying, together with NLP and laptop imaginative and prescient domains. He helps prospects obtain high-performance mannequin inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from giant enterprises to mid-sized startups on issues associated to distributed computing and synthetic intelligence. He focuses on deep studying, together with NLP and laptop imaginative and prescient domains. He helps prospects obtain high-performance mannequin inference on Amazon SageMaker.
 Jiahong Liu is a Resolution Architect on the Cloud Service Supplier crew at NVIDIA. He assists purchasers in adopting machine studying and AI options that leverage NVIDIA accelerated computing to deal with their coaching and inference challenges. In his leisure time, he enjoys origami, DIY initiatives, and enjoying basketball.
Jiahong Liu is a Resolution Architect on the Cloud Service Supplier crew at NVIDIA. He assists purchasers in adopting machine studying and AI options that leverage NVIDIA accelerated computing to deal with their coaching and inference challenges. In his leisure time, he enjoys origami, DIY initiatives, and enjoying basketball.
 Kshitiz Gupta is a Options Architect at NVIDIA. He enjoys educating cloud prospects concerning the GPU AI applied sciences NVIDIA has to supply and aiding them with accelerating their machine studying and deep studying purposes. Outdoors of labor, he enjoys operating, mountain climbing and wildlife watching.
Kshitiz Gupta is a Options Architect at NVIDIA. He enjoys educating cloud prospects concerning the GPU AI applied sciences NVIDIA has to supply and aiding them with accelerating their machine studying and deep studying purposes. Outdoors of labor, he enjoys operating, mountain climbing and wildlife watching.





