Run your native machine studying code as Amazon SageMaker Coaching jobs with minimal code modifications

We lately launched a brand new functionality within the Amazon SageMaker Python SDK that lets knowledge scientists run their machine studying (ML) code authored of their most popular built-in developer surroundings (IDE) and notebooks together with the related runtime dependencies as Amazon SageMaker coaching jobs with minimal code modifications to the experimentation achieved regionally. Knowledge scientists sometimes perform a number of iterations of experimentation in knowledge processing and coaching fashions whereas engaged on any ML drawback. They need to run this ML code and perform the experimentation with ease of use and minimal code change. Amazon SageMaker Model Training helps knowledge scientists run totally managed large-scale coaching jobs on AWS’s compute infrastructure. SageMaker Coaching additionally helps knowledge scientists with superior instruments resembling Amazon SageMaker Debugger and Profiler to debug and analyze their large-scale coaching jobs.
For patrons with small budgets, small groups, and tight timelines, each single new idea and line of code rewritten to run on SageMaker makes them much less productive in direction of their core duties, specifically knowledge processing and coaching ML fashions. They need to write code as soon as within the framework of their alternative and have the ability to transfer seamlessly from working code of their notebooks or laptops to working code at scale utilizing SageMaker capabilities.
With this new functionality of the SageMaker Python SDK, knowledge scientists can onboard their ML code to the SageMaker Coaching platform in a couple of minutes. You simply want so as to add a single line of code to your ML code, and SageMaker intelligently comprehends your code together with the datasets and workspace surroundings setup and runs it as a SageMaker Coaching job. You may then make the most of the important thing capabilities of the SageMaker Coaching platform, like the power to scale jobs simply, and different related instruments like Debugger and Profiler. On this launch, you’ll be able to run your native machine studying (ML) Python code as a single-node Amazon SageMaker coaching job or a number of parallel jobs. Distributed coaching jobs(throughout a number of nodes) aren’t supported by distant capabilities.
On this put up, we present you the best way to use this new functionality to run native ML code as a SageMaker Coaching job.
Resolution overview
Now you can run your ML code written in your IDE or pocket book as a SageMaker Coaching job by annotating the perform, which acts as an entry level to the consumer’s code base, with a easy decorator. Upon invocation, this functionality robotically takes a snapshot of all of the related variables, capabilities, packages, surroundings variables, and different runtime necessities out of your ML code, serializes them, and submits them as a SageMaker Coaching job. It integrates with the lately introduced SageMaker Python SDK feature for setting default values for parameters. This functionality simplifies the SageMaker constructs that you’ll want to be taught to have the ability to run code utilizing SageMaker Coaching. Knowledge scientists can write, debug, and iterate their code in any most popular IDE (resembling Amazon SageMaker Studio, notebooks, VS Code, or PyCharm). When prepared, you’ll be able to annotate your Python perform with the @distant decorator and run it as a SageMaker job at scale.
This functionality takes acquainted open-source Python objects as arguments and outputs. Moreover, you don’t want to know container lifecycle administration and may merely run your workloads throughout completely different compute contexts (resembling a neighborhood IDE, Studio, or coaching jobs) with minimal configuration overheads. To run any native code as a SageMaker Coaching job, this functionality infers the configurations required to run jobs, such because the AWS Identity and Access Management (IAM) position, encryption key, and community configuration, from the Studio or IDE settings (which will be the default settings) and passes them to the platform by default. You have got the pliability to customise your runtime within the SageMaker managed infrastructure utilizing the inferred configuration or override them on the SDK-level by passing them as arguments to the decorator.
This new functionality of the SageMaker Python SDK transforms your ML code in an current workspace surroundings and any related knowledge processing code and datasets right into a SageMaker Coaching job. This functionality appears to be like for ML code wrapped inside a @distant decorator and robotically interprets it right into a job that runs in both Studio or a neighborhood IDE resembling PyCharm.
Within the following sections, we stroll by way of the options of this new functionality and the best way to launch python capabilities as SageMaker Coaching jobs.
Conditions
To make use of this new SageMaker Python SDK functionality and run the code related to this put up, you want the next conditions:
- An AWS account that can include all of your AWS sources
- An IAM position to entry SageMaker
- Entry to Studio or a SageMaker pocket book occasion or an IDE resembling PyCharm
Use the SDK from Studio and SageMaker notebooks
You should use this functionality from Studio by launching a pocket book and wrapping your code with a @distant decorator contained in the pocket book. You first have to import the distant perform utilizing the next code:
from sagemaker.remote_function import distantOnce you use the decorator perform, this functionality will robotically interpret the perform of your code and run it as a SageMaker Coaching job.
You too can use this functionality from a SageMaker pocket book occasion. You first want to begin a pocket book occasion, open Jupyter or Jupyter Lab on it, and launch a pocket book. Then import the distant perform as proven within the previous code and wrap your code with the @distant decorator. We embrace an instance of the best way to use the decorator perform and the related settings later on this put up.
Use the SDK out of your native surroundings
You too can use this functionality out of your native IDE. As a prerequisite, you could have the AWS Command Line Interface (AWS CLI), SageMaker Python SDK, and AWS SDK for Python (Boto3) put in in your native surroundings. You should import these libraries in your code, set the SageMaker session, specify settings, and enhance your perform with the @distant decorator. Within the following instance code, we run a easy divide perform as a SageMaker Coaching job:
import boto3
import sagemaker
from sagemaker.remote_function import distant
sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
settings = dict(
sagemaker_session=sm_session,
position=<IAM_ROLE_NAME>
instance_type="ml.m5.xlarge",
)
@distant(**settings)
def divide(x, y):
return x / y
if __name__ == "__main__":
print(divide(2, 3.0))We are able to use an analogous methodology to run superior capabilities as coaching jobs, as proven within the subsequent part.
Launch Python capabilities as SageMaker jobs
The brand new SageMaker Python SDK function means that you can run Python capabilities as SageMaker Training jobs. Any Python code, ML coaching code developed by knowledge scientists utilizing their most popular native IDEs (PyCharm, VS Code), SageMaker notebooks, or Studio notebooks will be launched as a managed SageMaker job.
In ML workloads utilizing this functionality, related datasets, dependencies, and workspace surroundings setups are serialized utilizing the ML code and run as a SageMaker job synchronously and asynchronously.
You may add a @distant decorator annotation to any Python code together with a neighborhood ML processing or coaching perform to launch it as a managed SageMaker Coaching job, thereby benefiting from the dimensions, efficiency, and price advantages of SageMaker. This may be achieved with minimal code modifications by including a decorator to the Python perform code. Invocation to the adorned perform is run synchronously, and the perform run waits till the SageMaker job is full.
Within the following instance, we use the @distant decorator to launch SageMaker jobs in decorator mode utilizing an ml.m5.massive occasion. SageMaker makes use of coaching jobs to launch this perform as a managed job.
from sagemaker.remote_function import distant
from numpy as np
@distant(instance_type="ml.m5.massive")
def matrix_multiply(a, b):
return np.matmul(a, b)
a = np.array([[1, 0], [0, 1]])
b = np.array([1, 2])
assert matrix_multiply(a, b) == np.array([1,2])You too can use decorator mode to launch SageMaker jobs, Python packages, and dependencies. You may embrace surroundings variables resembling VPC, subnets, and safety teams to launch SageMaker coaching jobs within the surroundings.yml file. This enables ML engineers and admins to configure these surroundings variables so knowledge scientists can concentrate on ML mannequin constructing and iterate sooner. See the next code:
from sagemaker.remote_function import distant
@distant(instance_type="ml.g4dn.xlarge",dependencies = "./surroundings.yml")
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
mannequin = AutoModelForSequenceClassification.from_pretrained(model_name)
... <TRUCNATED>
return os.path.be a part of(s3_output_path, model_dir), eval_resultYou should use RemoteExecutor to launch Python capabilities as SageMaker jobs asynchronously. The executor asynchronously polls SageMaker Coaching jobs to replace the standing of the job. The RemoteExecutor class is an implementation of the concurrent.futures.Executor, which is used to submit SageMaker Coaching jobs asynchronously. See the next code:
from sagemaker.remote_function import RemoteExecutor
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
mannequin = AutoModelForSequenceClassification.from_pretrained(model_name)
...<TRUNCATED>
return os.path.be a part of(s3_output_path, model_dir), eval_result
with RemoteExecutor(instance_type="ml.g4dn.xlarge", dependencies="./necessities.txt") as e:
future = e.submit(train_hf_model, train_input_path,test_input_path,s3_output_path,
epochs, train_batch_size, eval_batch_size,warmup_steps,learning_rate)Customise the runtime surroundings
Decorator mode and RemoteExecutor permit you to outline and customise the runtime environments for the SageMaker job. The runtime dependencies, together with Python packages and surroundings variables for SageMaker jobs, will be specified to customise the runtime. So as to run native Python code as SageMaker managed jobs, the Python bundle and dependencies should be made accessible to SageMaker. ML engineers or knowledge science directors can configure networking and safety configurations resembling VPC, subnets, and safety teams for SageMaker jobs, so knowledge scientists can use these centrally managed configurations whereas launching SageMaker jobs. You should use both a necessities.txt file or a Conda surroundings.yaml file.
When dependencies are outlined with necessities.txt, the packages will likely be put in utilizing pip within the job runtime. If the picture used for working the job comes with Conda environments, packages will likely be put in within the Conda surroundings declared to make use of for jobs. The next code exhibits an instance necessities.txt file:
datasets
transformers
torch
scikit-learn
s3fs==0.4.2
sagemaker>=2.148.0You may cross your Conda surroundings.yaml file to create the Conda surroundings you desire to your code to run in through the coaching job. If the picture used for working the job declares a Conda surroundings to run the code underneath, we are going to replace the declared Conda surroundings with the given specification. The next code is an instance of a Conda surroundings.yaml file:
title: sagemaker_example
channels:
- conda-forge
dependencies:
- python=3.10
- pandas
- pip:
- sagemakerAlternatively, you’ll be able to set dependencies=”auto_capture” to let the SageMaker Python SDK seize the put in dependencies within the energetic Conda surroundings. You could have an energetic Conda surroundings for auto_capture to work. Observe that there are conditions for auto_capture to work; we suggest that you just cross in your dependencies as a requirement.txt or Conda surroundings.yml file as described within the earlier part.
For extra particulars, confer with Run your local code as a SageMaker Training job.
Configurations for SageMaker jobs
Infrastructure-related settings will be offloaded to a configuration file that admin customers may assist arrange. You solely have to set it up one time. Infrastructure settings cowl the community configuration, IAM roles, Amazon Simple Storage Service (Amazon S3) folder for enter, output knowledge, and tags. Check with Configuring and using defaults with the SageMaker Python SDK for extra particulars.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: path/to/necessities.txt
EnvironmentVariables: {"EnvVarKey": "EnvVarValue"}
ImageUri: 366666666666.dkr.ecr.us-west-2.amazonaws.com/my-image:newest
InstanceType: ml.m5.massive
RoleArn: arn:aws:iam::366666666666:position/MyRole
S3KmsKeyId: somekmskeyid
S3RootUri: s3://my-bucket/my-project
SecurityGroupIds:
- sg123
Subnets:
- subnet-1234
Tags:
- {"Key": "someTagKey", "Worth": "someTagValue"}
VolumeKmsKeyId: somekmskeyidImplementation
Deep studying fashions like PyTorch or TensorFlow will also be run inside Studio by working the code as a coaching job throughout the pocket book. To showcase this functionality in Studio, you’ll be able to clone this repo into your Studio and run the pocket book positioned within the GitHub repository.
This instance demonstrates an end-to-end binary textual content classification use case. We’re utilizing the Hugging Face transformers and datasets library to fine-tune a pre-trained transformer on binary textual content classification. Particularly, the pre-trained mannequin will likely be fine-tuned utilizing the IMDb dataset.
Once you clone the repository, you must find the next recordsdata:
- config.yaml – Many of the decorator arguments will be offloaded to the configuration file with the intention to separate out the infrastructure-related settings from the code base
- huggingface.ipynb – This comprises the code to coach a pre-trained HuggingFace mannequin, which will likely be fine-tuned utilizing the IMDB dataset
- necessities.txt – This file comprises all of the dependencies to run the perform that will likely be used on this pocket book for working the code and working the coaching remotely in a GPU occasion as a coaching job
Once you open the pocket book, you’ll be prompted to arrange the pocket book surroundings. You may choose the Knowledge Science 3.0 picture with the Python 3 kernel and ml.m5.massive because the quick launch occasion kind for working the pocket book code. This occasion kind is considerably sooner in spinning up an surroundings.
The coaching job will likely be run in an ml.g4dn.xlarge occasion as outlined within the config.yaml file:
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
# position arn just isn't required if in SageMaker Pocket book occasion or SageMaker Studio
# Uncomment the next line and substitute with the best execution position if in a neighborhood IDE
# RoleArn: <IAM_ROLE_ARN>
InstanceType: ml.g4dn.xlarge
Dependencies: ./necessities.txtThe necessities.txt file dependencies to run the perform for coaching the Hugging Face mannequin embrace the next:
datasets
transformers
torch
scikit-learn
# lock s3fs to this particular model as newer ones introduce dependency on aiobotocore, which isn't appropriate with botocore
s3fs==0.4.2
sagemaker>=2.148.0,<3The Hugging Face pocket book showcases the best way to run the coaching remotely by way of the @distant perform, which is run synchronously. Subsequently, the perform run for coaching the mannequin will wait till the SageMaker Coaching job is full. The coaching will likely be run remotely with a GPU occasion whereby the occasion kind is outlined within the previous configuration file.
After you run the coaching job, you’ll be able to run the remainder of the cells within the pocket book to examine the analysis metrics and classify the textual content on our skilled mannequin.
You too can view the coaching job standing that bought remotely triggered within the GPU occasion on the SageMaker dashboard by navigating again to the SageMaker console.
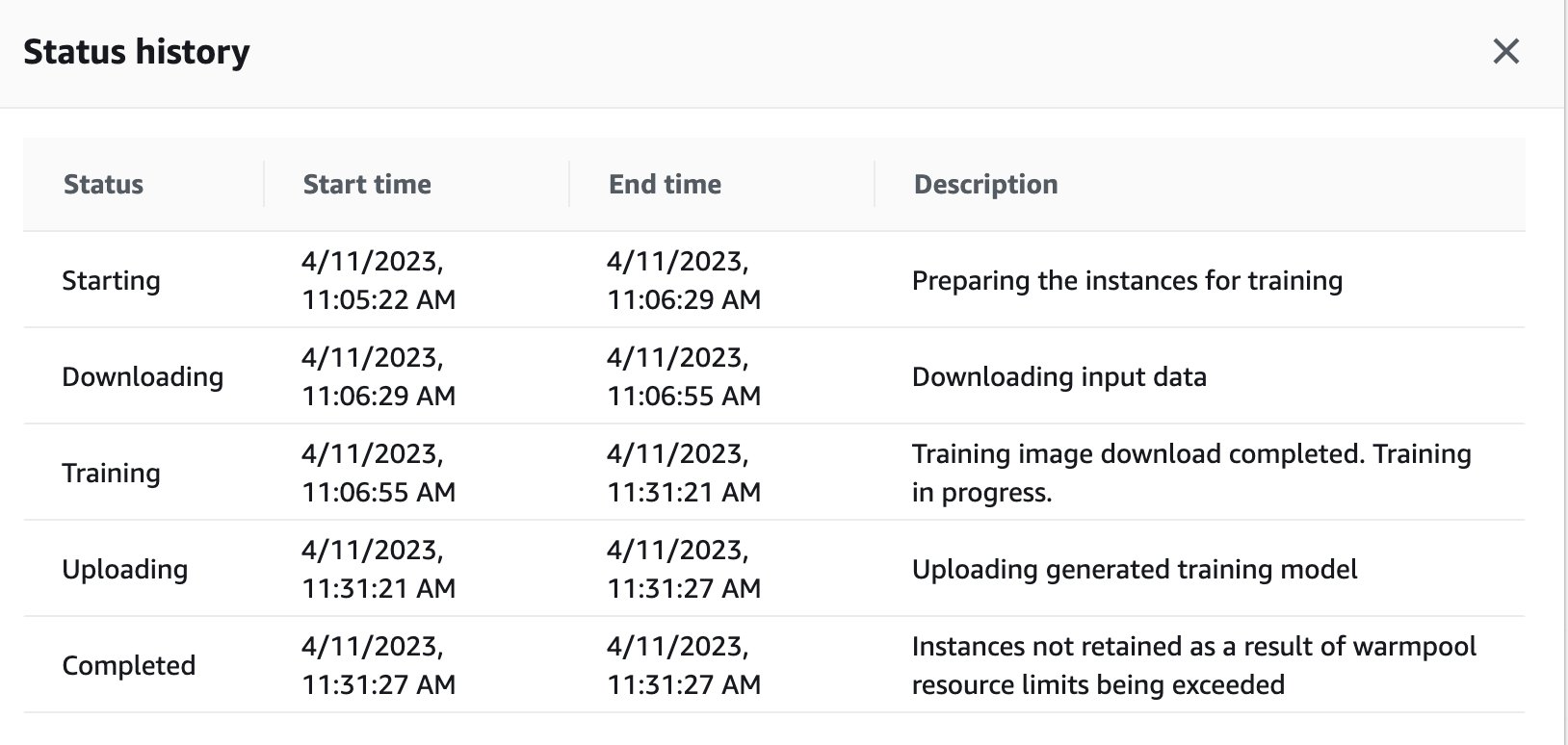
As quickly because the coaching job is full, it continues to run the directions within the pocket book for analysis and classification. Comparable jobs will be skilled and run by way of the distant executor perform embedded inside Studio notebooks to hold out the runs asynchronously.
Integration with SageMaker experiments inside a @distant perform
You may cross your experiment title, run title, and different parameters into your distant perform to create a SageMaker experiments run. The next code instance imports the experiment title, the title of the run, and the parameters to log for every run:
from sagemaker.remote_function import distant
from sagemaker.experiments.run import Run
# Outline your distant perform
@distant
def practice(value_1, value_2, exp_name, run_name):
...
...
#Creates the experiment
with Run(
experiment_name=exp_name,
run_name=run_name,
sagemaker_session=sagemaker_session
) as run:
...
...
#Outline values for the parameters to log
run.log_parameter("param_1", value_1)
run.log_parameter("param_2", value_2)
...
...
#Outline metrics to log
run.log_metric("metric_a", 0.5)
run.log_metric("metric_b", 0.1)
# Invoke your distant perform
practice(1.0, 2.0, "my-exp-name", "my-run-name") Within the previous instance, the parameters p1 and p2 are logged over time inside a coaching loop. Widespread parameters could embrace batch measurement or epochs. Within the instance, the metrics A and B are logged for a run over time inside a coaching loop. Widespread metrics could embrace accuracy or loss. For extra data, see Create an Amazon SageMaker Experiment.
Conclusion
On this put up, we launched a brand new SageMaker Python SDK functionality that permits knowledge scientists to run their ML code of their most popular IDE as SageMaker Coaching jobs. We mentioned the conditions wanted to make use of this functionality together with its options. We additionally confirmed the best way to use this functionality in Studio, SageMaker pocket book situations, and your native IDE. As well as, we offered pattern code examples to show the best way to use this functionality. As a subsequent step, we suggest making an attempt this functionality in your IDE or SageMaker by following the code examples referenced on this put up.
Concerning the Authors
 Dipankar Patro is a Software program Growth Engineer at AWS SageMaker, innovating and constructing MLOps options to assist clients undertake AI/ML options at scale. He has an MS in Pc Science and his areas of curiosity are Pc Safety, Distributed Programs and AI/ML.
Dipankar Patro is a Software program Growth Engineer at AWS SageMaker, innovating and constructing MLOps options to assist clients undertake AI/ML options at scale. He has an MS in Pc Science and his areas of curiosity are Pc Safety, Distributed Programs and AI/ML.
 Farooq Sabir is a Senior Synthetic Intelligence and Machine Studying Specialist Options Architect at AWS. He holds PhD and MS levels in Electrical Engineering from the College of Texas at Austin and an MS in Pc Science from Georgia Institute of Expertise. He has over 15 years of labor expertise and likewise likes to show and mentor faculty college students. At AWS, he helps clients formulate and remedy their enterprise issues in knowledge science, machine studying, pc imaginative and prescient, synthetic intelligence, numerical optimization, and associated domains. Primarily based in Dallas, Texas, he and his household like to journey and go on lengthy street journeys.
Farooq Sabir is a Senior Synthetic Intelligence and Machine Studying Specialist Options Architect at AWS. He holds PhD and MS levels in Electrical Engineering from the College of Texas at Austin and an MS in Pc Science from Georgia Institute of Expertise. He has over 15 years of labor expertise and likewise likes to show and mentor faculty college students. At AWS, he helps clients formulate and remedy their enterprise issues in knowledge science, machine studying, pc imaginative and prescient, synthetic intelligence, numerical optimization, and associated domains. Primarily based in Dallas, Texas, he and his household like to journey and go on lengthy street journeys.
 Manoj Ravi is a Senior Product Supervisor for Amazon SageMaker. He’s keen about constructing next-gen AI merchandise and works on software program and instruments to make large-scale machine studying simpler for purchasers. He holds an MBA from Haas College of Enterprise and a Masters in Data Programs Administration from Carnegie Mellon College. In his spare time, Manoj enjoys enjoying tennis and pursuing panorama images.
Manoj Ravi is a Senior Product Supervisor for Amazon SageMaker. He’s keen about constructing next-gen AI merchandise and works on software program and instruments to make large-scale machine studying simpler for purchasers. He holds an MBA from Haas College of Enterprise and a Masters in Data Programs Administration from Carnegie Mellon College. In his spare time, Manoj enjoys enjoying tennis and pursuing panorama images.
 Shikhar Kwatra is an AI/ML Specialist Options Architect at Amazon Internet Companies, working with a number one International System Integrator. He has earned the title of one of many Youngest Indian Grasp Inventors with over 500 patents within the AI/ML and IoT domains. Shikhar aids in architecting, constructing, and sustaining cost-efficient, scalable cloud environments for the group, and helps the GSI associate in constructing strategic business options on AWS. Shikhar enjoys enjoying guitar, composing music, and working towards mindfulness in his spare time.
Shikhar Kwatra is an AI/ML Specialist Options Architect at Amazon Internet Companies, working with a number one International System Integrator. He has earned the title of one of many Youngest Indian Grasp Inventors with over 500 patents within the AI/ML and IoT domains. Shikhar aids in architecting, constructing, and sustaining cost-efficient, scalable cloud environments for the group, and helps the GSI associate in constructing strategic business options on AWS. Shikhar enjoys enjoying guitar, composing music, and working towards mindfulness in his spare time.
 Vikram Elango is a Sr. AI/ML Specialist Options Architect at AWS, primarily based in Virginia, US. He’s at the moment centered on generative AI, LLMs, immediate engineering, massive mannequin inference optimization, and scaling ML throughout enterprises. Vikram helps monetary and insurance coverage business clients with design and thought management to construct and deploy machine studying functions at scale. In his spare time, he enjoys touring, mountain climbing, cooking, and tenting.
Vikram Elango is a Sr. AI/ML Specialist Options Architect at AWS, primarily based in Virginia, US. He’s at the moment centered on generative AI, LLMs, immediate engineering, massive mannequin inference optimization, and scaling ML throughout enterprises. Vikram helps monetary and insurance coverage business clients with design and thought management to construct and deploy machine studying functions at scale. In his spare time, he enjoys touring, mountain climbing, cooking, and tenting.





