Prepare ImageNet with out Hyperparameters with Computerized Gradient Descent | by Chris Mingard | Apr, 2023
In the direction of architecture-aware optimisation
TL;DR We’ve derived an optimiser referred to as computerized gradient descent (AGD) that may practice ImageNet with out hyperparameters. This removes the necessity for costly and time-consuming studying price tuning, collection of studying price decay schedulers, and so on. Our paper might be discovered here.
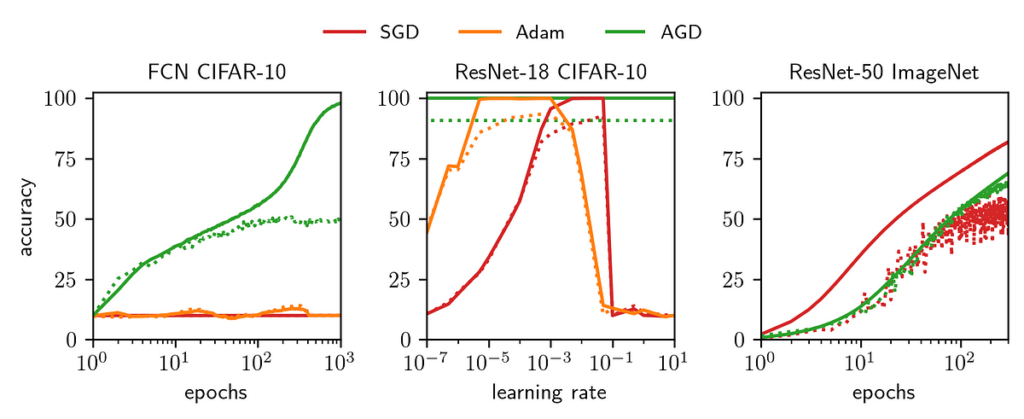
I labored on this venture with Jeremy Bernstein, Kevin Huang, Navid Azizan and Yisong Yue. See Jeremy’s GitHub for a clear Pytorch implementation, or my GitHub for an experimental model with extra options. Determine 1 summarises the variations between AGD, Adam, and SGD.

Anybody who has skilled a deep neural community has probably needed to tune the educational price. That is (1) to make sure coaching is maximally environment friendly and (2) as a result of discovering the suitable studying price can considerably enhance total generalisation. That is additionally an enormous ache.

Nevertheless, with SGD the optimum studying price extremely is determined by the structure being skilled. Discovering it usually requires a expensive grid search process, sweeping over many orders of magnitude. Moreover, different hyperparameters, like momentum and studying price decay schedulers, additionally have to be chosen and tuned.
We current an optimiser referred to as computerized gradient descent (AGD) that doesn’t want a studying price to coach a variety of architectures and datasets, scaling all the way in which as much as ResNet-50 on ImageNet. This removes the necessity for any hyperparameter tuning (as each the efficient studying price and studying price decay drop out of the evaluation), saving on compute prices and massively dashing up the method of coaching a mannequin.
A deep studying system consists of a lot of interrelated elements: structure, knowledge, loss perform and gradients. There’s a construction in the way in which these elements work together, however as of but no person has precisely nailed down this construction, so we’re left with a lot of tuning (e.g. studying price, initialisation, schedulers) to make sure fast convergence, and keep away from overfitting.
However characterising these interactions completely might take away all levels of freedom within the optimisation course of — that are presently taken care of by guide hyperparameter tuning. Second-order strategies presently characterise the sensitivity of the target to weight perturbations utilizing the Hessian, and take away levels of freedom that manner — nevertheless, such strategies might be computationally intensive and thus not sensible for big fashions.
We derive AGD by characterising these interactions analytically:
- We certain the change within the output of the neural community by way of the change in weights, for given knowledge and structure.
- We relate the change in goal (the overall loss over all inputs in a batch) to the change within the output of the neural community
- We mix these leads to a so-called majorise-minimise method. We majorise the target — that’s, we derive an higher certain on the target that lies tangent to the target. We are able to then minimise this higher certain, realizing that this may transfer us downhill. That is visualised in Determine 3, the place the purple curve reveals the majorisation of the target perform, proven by the blue curve.
On this part, we undergo all the important thing components of the algorithm. See Appendix A for a sketch derivation.
On parameterisation
We use a parameterisation that differs barely from the standard PyTorch defaults. AGD might be derived with out assuming this parameterisation, however utilizing it simplifies the evaluation. For a totally linked layer l, we use orthogonal initialisation, scaled such that the singular values have magnitude sqrt((enter dimension of l )/(output dimension of l )).
We use this normalisation as a result of it has good properties that PyTorch default parameterisation doesn’t, together with stability with width, resistance to blow-ups within the activations, and promotion of function studying. That is just like Greg Yang and Edward Hu’s muP.
On the replace
The step might be damaged into two separate components. The primary is the calculation of eta (η), the “computerized studying price”, which scales the replace in any respect layers. Eta has a logarithmic dependence on the gradient norm — when the gradients are small, eta is roughly linear (like customary optimisers) however when they’re very giant, the logarithm mechanically performs a kind of gradient clipping.
Every layer is up to date utilizing eta multiplied by the layer’s weight norm, multiplied by normalised gradients, and divided by depth. The division by depth is chargeable for scaling with depth. It’s fascinating that gradient normalisation drops out of the evaluation, as different optimisers like Adam incorporate comparable concepts heuristically.
The purpose for these experiments was to check AGD’s means to (1) converge throughout a variety of architectures and datasets, and (2) obtain comparable take a look at accuracy to tuned Adam and SGD.
Determine 4 reveals the educational curves of 4 architectures, from a fully-connected community (FCN) to ResNet-50, on datasets from CIFAR-10 to ImageNet. We evaluate AGD, proven with stable strains, to a normal optimiser, proven with dotted strains (SGD for ImageNet and tuned Adam for the opposite three). The prime row reveals the practice goal (loss) and computerized studying price η. The backside row reveals the practice and take a look at accuracies. Determine 5 compares AGD vs tuned Adam vs tuned SGD on an 8-layer FCN. We see very comparable efficiency from all three algorithms, reaching close to equivalent take a look at accuracy.
Determine 6 reveals that AGD trains FCNs over a variety of depths (2 to 32) and widths (64 to 2048). Determine 7 reveals the dependence of AGD on batch dimension (from 32 to 4096), on a 4-layer FCN. It appears to converge to a superb optimum regardless of the batch dimension!
To summarise, right here is an “architecture-aware” optimiser: computerized gradient descent (AGD), able to coaching small programs like an FCN on CIFAR-10 to large-scale programs like ResNet-50 on ImageNet, at a variety of batch sizes, with out the necessity for guide hyperparameter tuning.
Whereas utilizing AGD has not eliminated all hyperparameters from machine studying, those who stay — batch dimension and structure — sometimes fall below into the “make them as giant as doable to replenish time/compute price range”.
Nevertheless, there may be heaps nonetheless to be carried out. We don’t explicitly take note of stochasticity launched into the gradient resulting from batch dimension. We additionally haven’t regarded into regularisation like weight decay. Whereas we’ve carried out a little bit bit of labor in including assist for affine parameters (in batch norm layers) and bias phrases, we haven’t examined it extensively, neither is it as nicely justified by concept as the remainder of the outcomes right here.
Maybe most significantly, we nonetheless must do the evaluation required for transformers, and take a look at AGD on NLP duties. Progress is being made on this entrance as nicely!
Lastly, take a look at Jeremy’s GitHub for a clear model, or my GitHub for a developmental model with assist for bias phrases and affine parameters, if you wish to strive AGD! We hope one can find it helpful.
We are going to undergo a sketch of the vital steps of the proof right here. That is designed for anybody who needs to see how the principle concepts come collectively, with out going by the complete proof, present in our paper here.

Equation (1) specifies explicitly how the general goal throughout the dataset S is decomposed into particular person datapoints. L denotes loss, x the inputs, y the targets and w the weights. Equation (2) reveals a decomposition of the linearisation error of the target — the contributions of upper order phrases given some change in weights, Δw, to the change in loss ΔL(w). The linearisation error of the target is vital as a result of it is the same as the contributions of upper order phrases within the loss expanded at weights w — bounding this may inform us how far we will transfer earlier than the upper order phrases turn out to be vital, and ensure we’re taking steps of smart dimension, downhill.
The primary time period on the RHS of Equation (2) is an internal product between two high-dimensional vectors, the linearisation error of the mannequin, and the spinoff of the loss with respect to f(x). Since there isn’t a clear cause why these two vectors must be aligned, we assume that their internal product is zero.
Including L(W+ΔW) to every facet of Equation (2), and noting that the linearisation error of the loss occurs to be a Bregman divergence, we will simplify the notation:

A Bregman divergence is a measure of distance between two factors (on this case, the outputs of two completely different parameter decisions of a neural community), outlined by way of a strictly convex perform — on this case, the loss.
Calculating the Bregman divergence is definitely fairly simple for imply sq. error loss, and offers us

The place dₗ is the output dimension of the community. We now assert the next scalings. All of those are considerably arbitrary, however having them on this type will make the evaluation a lot easier.

We use the next two bounds on the scale of the community output. Equation (5) bounds the magnitude of the community output, and comes from simply making use of the (enter scaling) and (weight scaling) to a fully-connected community. Equation (6) bounds the utmost change in f(x) with a change within the weights W. The second inequality in (6) is tightest at giant depth however holds for any depth.

Now, we substitute Equation (6) again into Equation (4), and increase all phrases out explicitly to get Equation (7).

We are able to substitute the sum in Equation (7) with G, outlined in Equation (8) below a further assumption in regards to the gradient conditioning, which is mentioned intimately within the paper. Lastly, we get Equation (9) — that is the majorisation — the purple line in Determine 3. We decrease the majorisation by differentiating with respect to η, and clear up the ensuing quadratic in exp(η), retaining the constructive resolution. This offers the next replace

And this concludes our derivation of computerized gradient descent. Please tell us when you’ve got any feedback, questions or other forms of suggestions.
All photos within the weblog are made by the authors of our paper.




