Are Mannequin Explanations Helpful in Observe? Rethinking Help Human-ML Interactions. – Machine Studying Weblog | ML@CMU

Determine 1. This weblog submit discusses the effectiveness of black-box mannequin explanations in aiding finish customers to make choices. We observe that explanations don’t in truth assist with concrete functions comparable to fraud detection and paper matching for peer overview. Our work additional motivates novel instructions for growing and evaluating instruments to help human-ML interactions.
Mannequin explanations have been touted as essential data to facilitate human-ML interactions in lots of real-world functions the place finish customers make choices knowledgeable by ML predictions. For instance, explanations are thought to help mannequin builders in figuring out when fashions depend on spurious artifacts and to assist area specialists in figuring out whether or not to comply with a mannequin’s prediction. Nonetheless, whereas quite a few explainable AI (XAI) strategies have been developed, XAI has but to ship on this promise. XAI strategies are sometimes optimized for numerous however slim technical targets disconnected from their claimed use circumstances. To attach strategies to concrete use circumstances, we argued in our Communications of ACM paper [1] for researchers to carefully consider how effectively proposed strategies may help actual customers of their real-world functions.
In the direction of bridging this hole, our group has since accomplished two collaborative tasks the place we labored with area specialists in e-commerce fraud detection and paper matching for peer overview. Via these efforts, we’ve gleaned the next two insights:
- Present XAI strategies aren’t helpful for decision-making. Presenting people with widespread, general-purpose XAI strategies doesn’t enhance their efficiency on real-world use circumstances that motivated the event of those strategies. Our damaging findings align with these of contemporaneous works.
- Rigorous, real-world analysis is vital however onerous. These findings had been obtained by person research that had been time-consuming to conduct.
We imagine that every of those insights motivates a corresponding analysis course to help human-ML interactions higher shifting ahead. First, past strategies that try to clarify the ML mannequin itself, we should always think about a wider vary of approaches that current related task-specific data to human decision-makers; we refer to those approaches as human-centered ML (HCML) strategies [10]. Second, we have to create new workflows to judge proposed HCML strategies which can be each low-cost and informative of real-world efficiency.
On this submit, we first define our workflow for evaluating XAI strategies. We then describe how we instantiated this workflow in two domains: fraud detection and peer overview paper matching. Lastly, we describe the 2 aforementioned insights from these efforts; we hope these takeaways will inspire the group to rethink how HCML strategies are developed and evaluated.
How do you rigorously consider clarification strategies?
In our CACM paper [1], we launched a use-case-grounded workflow to judge clarification strategies in follow—this implies exhibiting that they’re ‘helpful,’ i.e., that they will really enhance human-ML interactions within the real-world functions that they’re motivated by. This workflow contrasts with analysis workflows of XAI strategies in prior work, which relied on researcher-defined proxy metrics which will or might not be related to any downstream job. Our proposed three-step workflow relies on the overall scientific technique:
Step 1: Outline a concrete use case. To do that, researchers could must work carefully with area specialists to outline a job that displays the sensible use case of curiosity.
Step 2: Choose clarification strategies for analysis. Whereas chosen strategies is perhaps comprised of widespread XAI strategies, the suitable set of strategies is to a big extent application-specific and must also embody related non-explanation baselines.
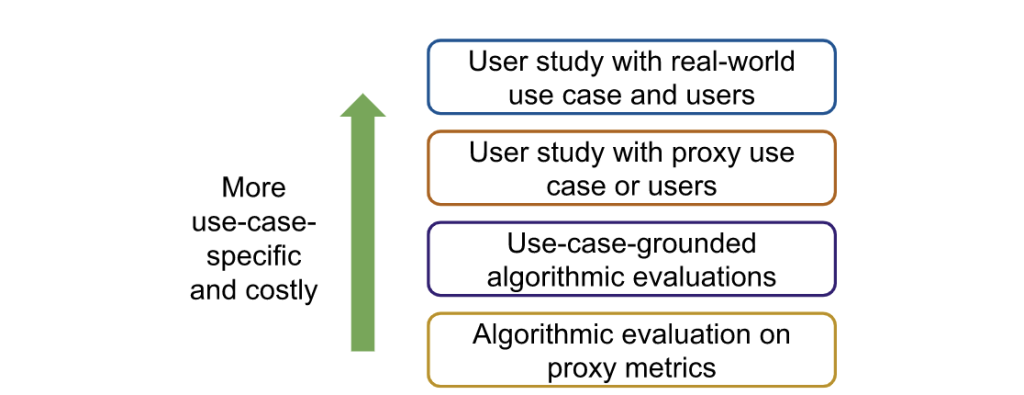
Step 3: Consider clarification strategies in opposition to baselines. Whereas researchers ought to finally consider chosen strategies by a person research with real-world customers, researchers could need to first conduct cheaper, noisier types of analysis to slim down the set of strategies in consideration (Determine 2).
Instantiating the workflow in follow
We collaborated with specialists from two domains (fraud detection and peer overview paper matching) to instantiate this use-case-grounded workflow and consider current XAI strategies:
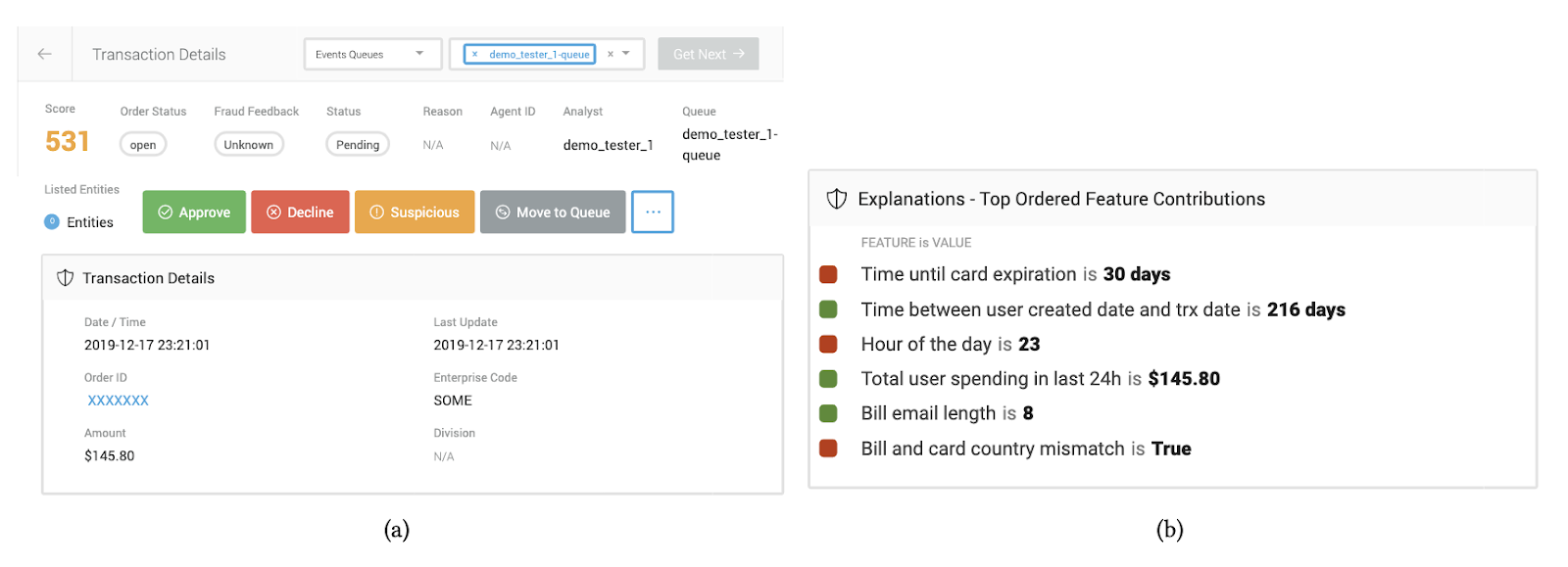
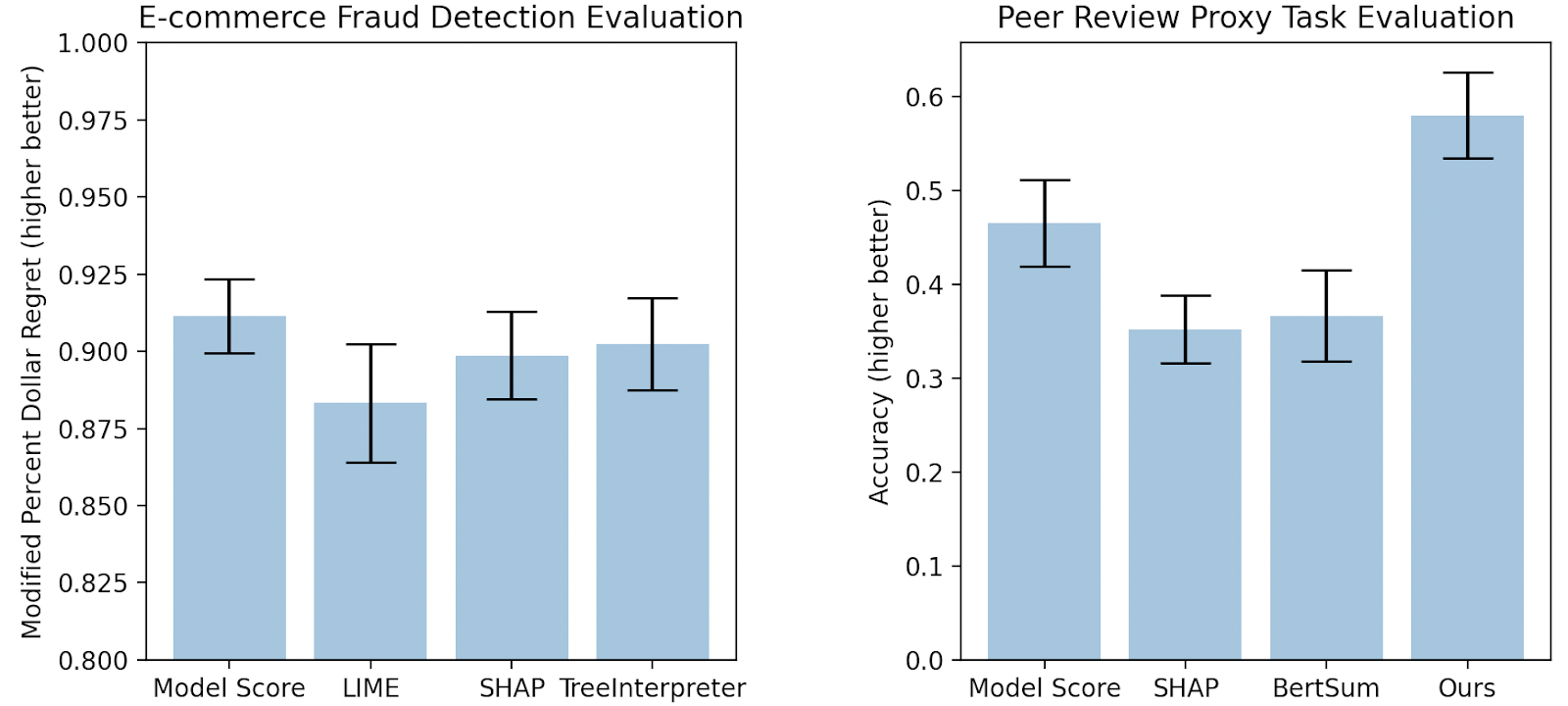
Area 1: Fraud detection [3]. We partnered with researchers at Feedzai, a monetary start-up, to evaluate whether or not offering mannequin explanations improved the flexibility of fraud analysts to detect fraudulent e-commerce transactions. Provided that we had entry to real-world knowledge (i.e., historic e-commerce transactions for which we had floor fact solutions of whether or not the transaction was fraudulent) and actual customers (i.e., fraud analysts), we straight performed a person research on this context. An instance of the interface proven to analysts is in Determine 3. We in contrast analysts’ common efficiency when proven completely different explanations to a baseline setting the place they had been solely supplied the mannequin prediction. We finally discovered that not one of the widespread XAI strategies we evaluated (LIME, SHAP, and Tree Interpreter) resulted in any enchancment within the analysts’ choices in comparison with the baseline setting (Determine 5, left). Evaluating these strategies with actual customers moreover posed many logistical challenges as a result of fraud analysts took time from their common day-to-day work to periodically take part in our research.
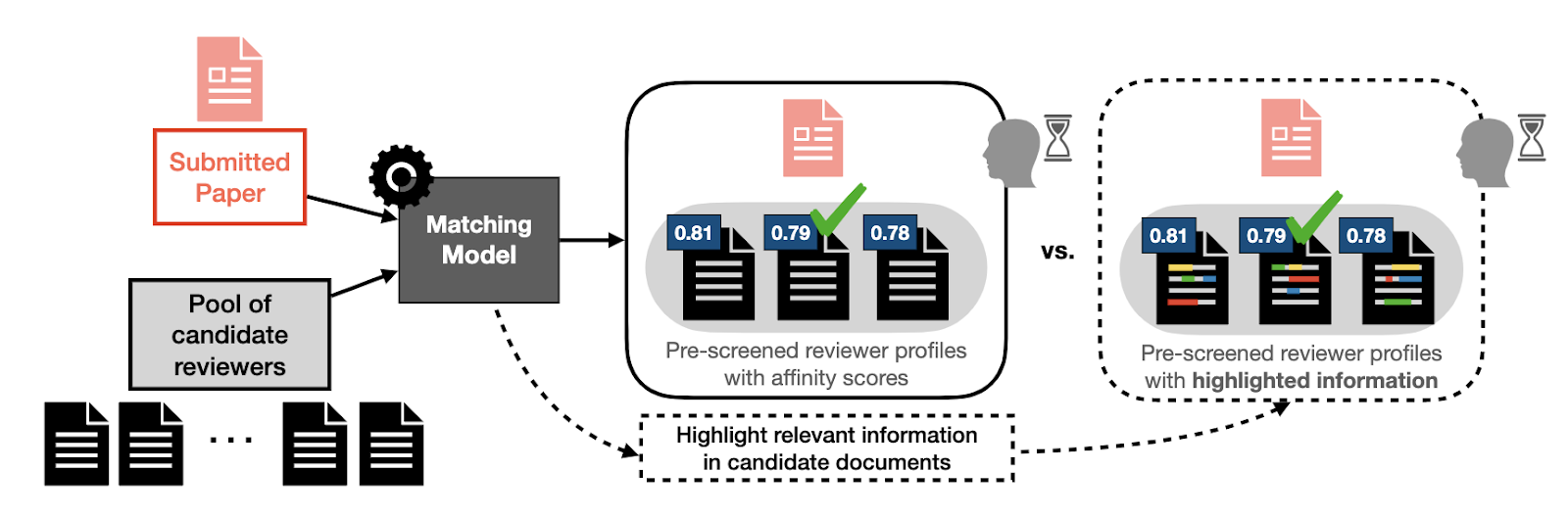
Area 2: Peer overview paper matching [4]. We collaborated with Professor Nihar Shah (CMU), an skilled in peer overview, to research what data may assist meta-reviewers of a convention higher match submitted papers to acceptable reviewers. Studying from our prior expertise, we first performed a person research utilizing proxy duties and customers, which we labored with Professor Shah to design as proven in Determine 4. On this proxy setting, we discovered that offering explanations from widespread XAI strategies in truth led customers to be extra assured—-the vast majority of members proven highlights from XAI strategies believed the highlighted data was useful—yet, they made statistically worse choices (Determine 5 proper)!
How can we higher help human-ML interactions?
Via these collaborations, we recognized two vital instructions for future work, which we describe in additional element together with our preliminary efforts in every course.
We have to develop strategies for particular use circumstances. Our outcomes counsel that explanations from widespread, general-purpose XAI strategies can each damage decision-making whereas making customers overconfident. These findings have additionally been noticed in a number of contemporaneous works (e.g., [7,8,9]). Researchers, as a substitute, want to contemplate growing human-centered ML (HCML) strategies [10] tailor-made for every downstream use case. HCML strategies are any strategy that gives details about the actual use case and context that may inform human choices.

Our contributions: Within the peer overview matching setting, we proposed an HCML technique designed in tandem with a website skilled [4]. Notably, our technique shouldn’t be a mannequin clarification strategy, because it highlights data within the enter knowledge, particularly sentences and phrases which can be comparable within the submitted paper and the reviewer profile. Determine 6 compares the textual content highlighted utilizing our technique to the textual content highlighted utilizing current strategies. Our technique outperformed each a baseline the place there was no clarification and the mannequin clarification situation (Determine 5, proper). Primarily based on these optimistic outcomes, we plan to maneuver evaluations of our proposed technique to extra life like peer overview settings. Additional, we carried out an exploratory research to higher perceive how individuals work together with data supplied by HCML strategies as a primary step in direction of developing with a extra systematic strategy to plan task-specific HCML strategies [5].
We want extra environment friendly analysis pipelines. Whereas person research performed in a real-world use case and with actual customers are the perfect option to consider HCML strategies, it’s a time- and resource-consuming course of. We spotlight the necessity for more cost effective evaluations that may be utilized to slim down candidate HCML strategies and nonetheless implicate the downstream use case. One possibility is to work with area specialists to design a proxy job as we did within the peer overview setting, however even these research require cautious consideration of the generalizability to the real-world use case.
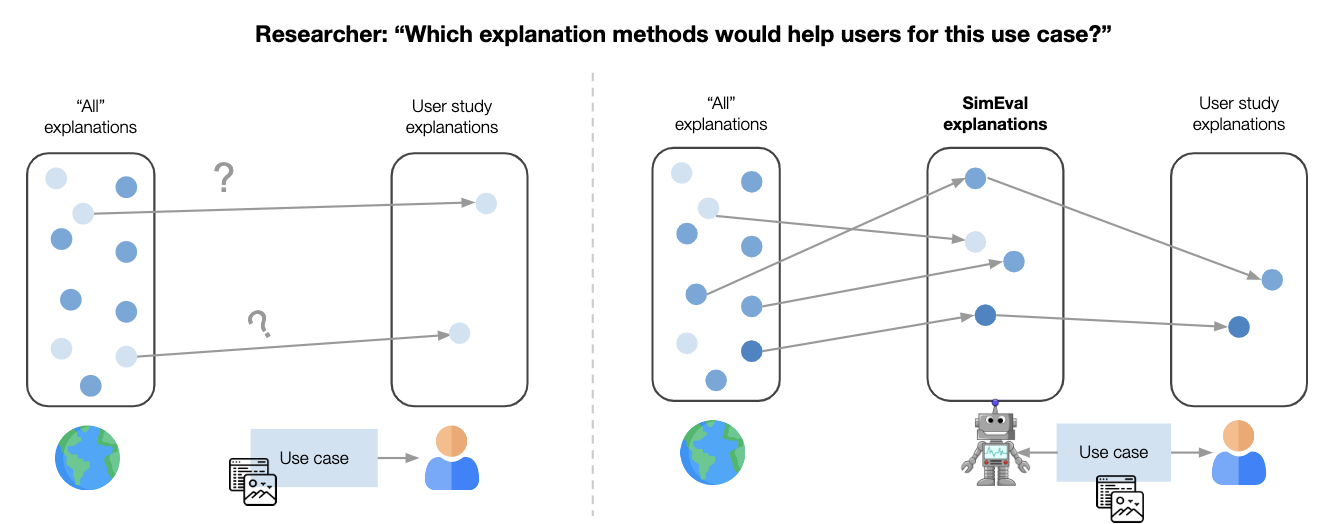
Our contributions. We launched an algorithmic-based analysis known as simulated person analysis (SimEvals) [2]. As a substitute of conducting research on proxy duties, researchers can practice SimEvals, that are ML fashions that function human proxies. SimEvals extra faithfully displays facets of real-world analysis as a result of their coaching and analysis knowledge are instantiated on the identical knowledge and job thought of in real-world research. To coach SimEvals, the researcher first must generate a dataset of observation-label pairs. The commentary corresponds to the knowledge that will be offered in a person research (and critically contains the HCML technique), whereas the output is the bottom fact label for the use case of curiosity. For instance, within the fraud detection setting, the commentary would include each the e-commerce transaction and ML mannequin rating proven in Determine 3(a) together with the reason proven in Determine 3(b). The bottom fact label is whether or not or not the transaction was fraudulent. SimEvals are educated to foretell a label given an commentary and their take a look at set accuracies might be interpreted as a measure of whether or not the knowledge contained within the commentary is predictive for the use case.
We not solely evaluated SimEvals on a wide range of proxy duties but additionally examined SimEvals in follow by working with Feedzai, the place we discovered outcomes that corroborate the damaging findings from the person research [6]. Though SimEvals shouldn’t exchange person research as a result of SimEvals aren’t designed to imitate human decision-making, these outcomes counsel that SimEvals might be initially used to determine extra promising explanations (Determine 6).
Conclusion
In abstract, our latest efforts inspire two methods the group ought to rethink the best way to help human-ML interactions: (1) we have to exchange general-purpose XAI methods with HCML strategies tailor-made to particular use circumstances, and (2) creating intermediate analysis procedures that may assist slim down the HCML strategies to judge in additional expensive settings.
For extra details about the varied papers talked about on this weblog submit, see the hyperlinks under:
[1] Chen, V., Li, J., Kim, J. S., Plumb, G., & Talwalkar, A. Interpretable Machine Studying. Communications of the ACM, 2022. (link)
[2] Chen, V., Johnson, N., Topin, N., Plumb, G., & Talwalkar, A. Use-case-grounded simulations for clarification analysis. NeurIPS, 2022. (link)
[3] Amarasinghe, Okay., Rodolfa, Okay. T., Jesus, S., Chen, V., Balayan, V., Saleiro, P., Bizzaro, P., Talwalkar, A. & Ghani, R. (2022). On the Significance of Utility-Grounded Experimental Design for Evaluating Explainable ML Strategies. arXiv. (link)
[4] Kim, J. S., Chen, V., Pruthi, D., Shah, N., Talwalkar, A. Aiding Human Selections in Doc Matching. arXiv. (link)
[5] Chen, V., Liao, Q. V., Vaughan, J. W., & Bansal, G. (2023). Understanding the Function of Human Instinct on Reliance in Human-AI Resolution-Making with Explanations. arXiv. (link)
[6] Martin, A., Chen, V., Jesus, S., Saleiro, P. A Case Research on Designing Evaluations of ML Explanations with Simulated Consumer Research. arXiv. (link)
[7] Bansal, G., Wu, T., Zhou, J., Fok, R., Nushi, B., Kamar, E., Ribeiro, M. T. & Weld, D. Does the entire exceed its elements? the impact of ai explanations on complementary workforce efficiency. CHI, 2021. (link)
[8] Adebayo, J., Muelly, M., Abelson, H., & Kim, B. Publish hoc explanations could also be ineffective for detecting unknown spurious correlation. ICLR, 2022. (link)
[9] Zhang, Y., Liao, Q. V., & Bellamy, R. Okay. Impact of confidence and clarification on accuracy and belief calibration in AI-assisted resolution making. FAccT, 2020. (link)
[10] Chancellor, S. (2023). Towards Practices for Human-Centered Machine Studying. Communications of the ACM, 66(3), 78-85. (link)
Acknowledgments
We wish to thank Kasun Amarasinghe, Jeremy Cohen, Nari Johnson, Joon Sik Kim, Q. Vera Liao, and Junhong Shen for useful suggestions and strategies on earlier variations of the weblog submit. Thanks additionally to Emma Kallina for her assist with designing the primary determine!




